Google Launches Axion Arm-based CPU for Data Center and Cloud
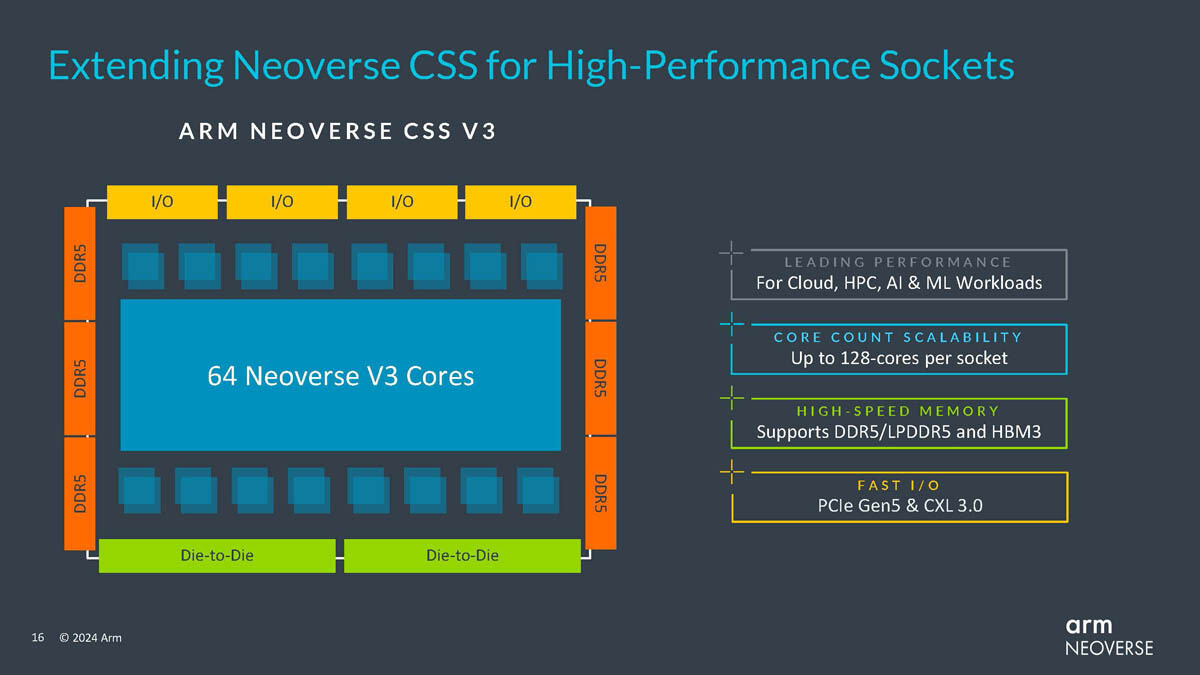
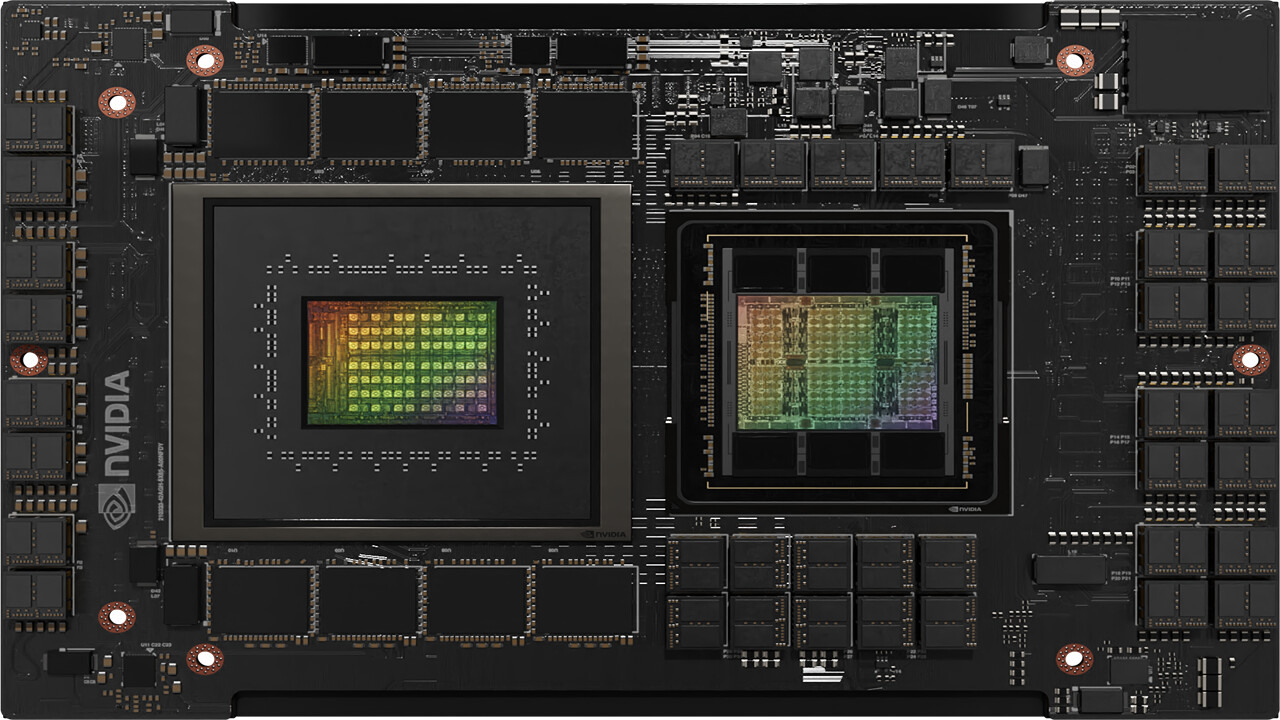
Google has officially joined the club of custom Arm-based, in-house-developed CPUs. As of today, Google's in-house semiconductor development team has launched the "Axion" CPU based on Arm instruction set architecture. Using the Arm Neoverse V2 cores, Google claims that the Axion CPU outperforms general-purpose Arm chips by 30% and Intel's processors by a staggering 50% in terms of performance. This custom silicon will fuel various Google Cloud offerings, including Compute Engine, Kubernetes Engine, Dataproc, Dataflow, and Cloud Batch. The Axion CPU, designed from the ground up, will initially support Google's AI-driven services like YouTube ads and Google Earth Engine. According to Mark Lohmeyer, Google Cloud's VP and GM of compute and machine learning infrastructure, Axion will soon be available to cloud customers, enabling them to leverage its performance without overhauling their existing applications.
Google's foray into custom silicon aligns with the strategies of its cloud rivals, Microsoft and Amazon. Microsoft recently unveiled its own AI chip for training large language models and an Arm-based CPU called Cobalt 100 for cloud and AI workloads. Amazon, on the other hand, has been offering Arm-based servers through its custom Graviton CPUs for several years. While Google won't sell these chips directly to customers, it plans to make them available through its cloud services, enabling businesses to rent and leverage their capabilities. As Amin Vahdat, the executive overseeing Google's in-house chip operations, stated, "Becoming a great hardware company is very different from becoming a great cloud company or a great organizer of the world's information."
Google's foray into custom silicon aligns with the strategies of its cloud rivals, Microsoft and Amazon. Microsoft recently unveiled its own AI chip for training large language models and an Arm-based CPU called Cobalt 100 for cloud and AI workloads. Amazon, on the other hand, has been offering Arm-based servers through its custom Graviton CPUs for several years. While Google won't sell these chips directly to customers, it plans to make them available through its cloud services, enabling businesses to rent and leverage their capabilities. As Amin Vahdat, the executive overseeing Google's in-house chip operations, stated, "Becoming a great hardware company is very different from becoming a great cloud company or a great organizer of the world's information."