NVIDIA Launches the RTX A400 and A1000 Professional Graphics Cards
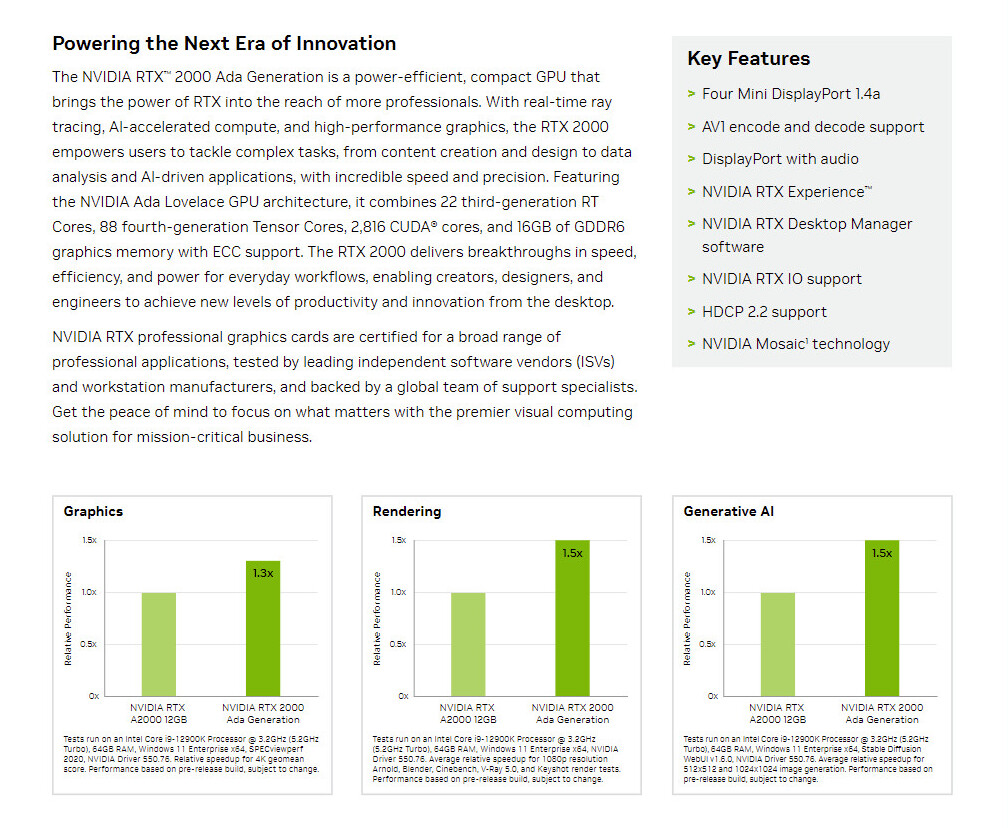
AI integration across design and productivity applications is becoming the new standard, fueling demand for advanced computing performance. This means professionals and creatives will need to tap into increased compute power, regardless of the scale, complexity or scope of their projects. To meet this growing need, NVIDIA is expanding its RTX professional graphics offerings with two new NVIDIA Ampere architecture-based GPUs for desktops: the NVIDIA RTX A400 and NVIDIA RTX A1000.
They expand access to AI and ray tracing technology, equipping professionals with the tools they need to transform their daily workflows. The RTX A400 GPU introduces accelerated ray tracing and AI to the RTX 400 series GPUs. With 24 Tensor Cores for AI processing, it surpasses traditional CPU-based solutions, enabling professionals to run cutting-edge AI applications, such as intelligent chatbots and copilots, directly on their desktops. The GPU delivers real-time ray tracing, so creators can build vivid, physically accurate 3D renders that push the boundaries of creativity and realism.
They expand access to AI and ray tracing technology, equipping professionals with the tools they need to transform their daily workflows. The RTX A400 GPU introduces accelerated ray tracing and AI to the RTX 400 series GPUs. With 24 Tensor Cores for AI processing, it surpasses traditional CPU-based solutions, enabling professionals to run cutting-edge AI applications, such as intelligent chatbots and copilots, directly on their desktops. The GPU delivers real-time ray tracing, so creators can build vivid, physically accurate 3D renders that push the boundaries of creativity and realism.