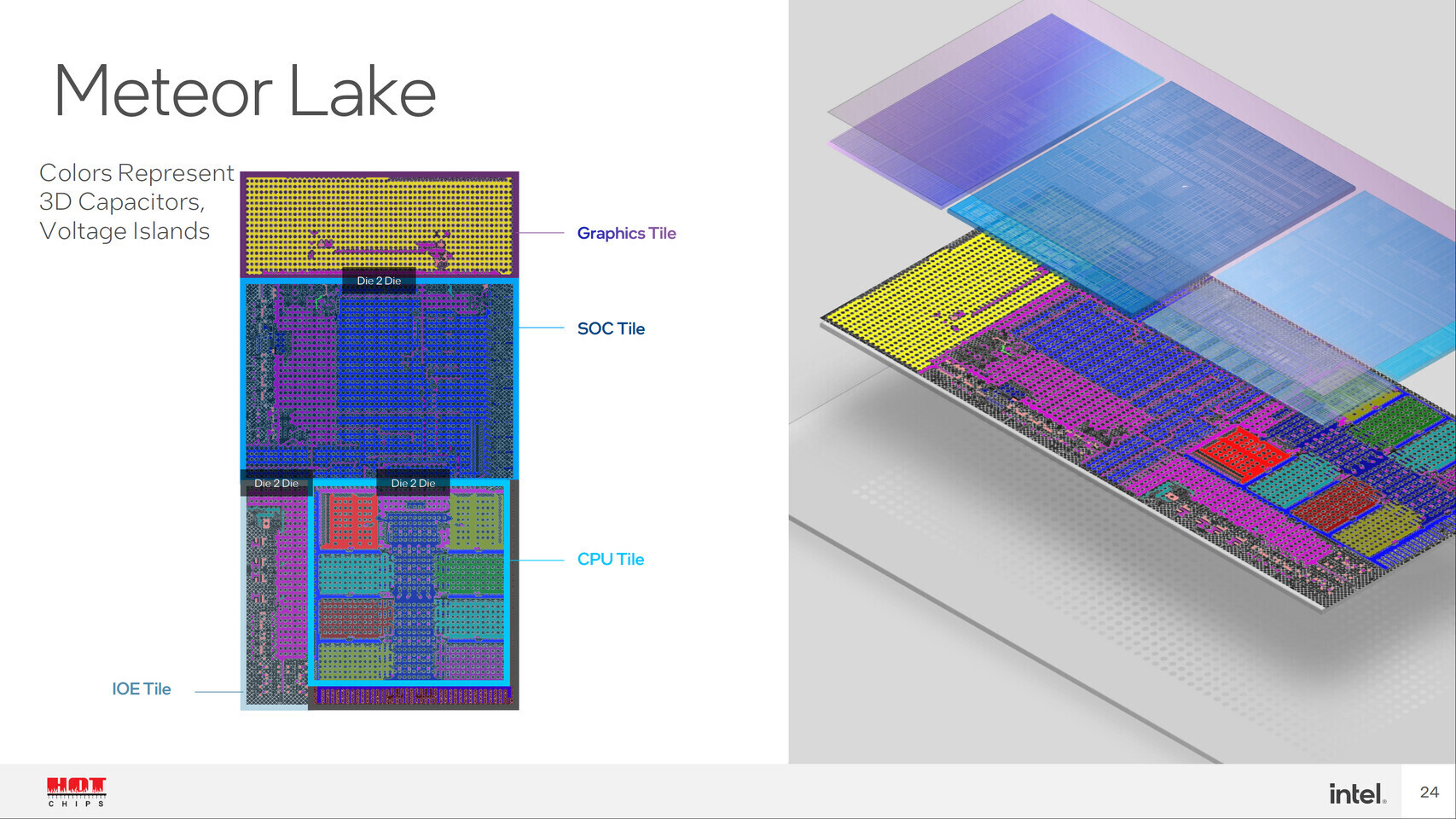
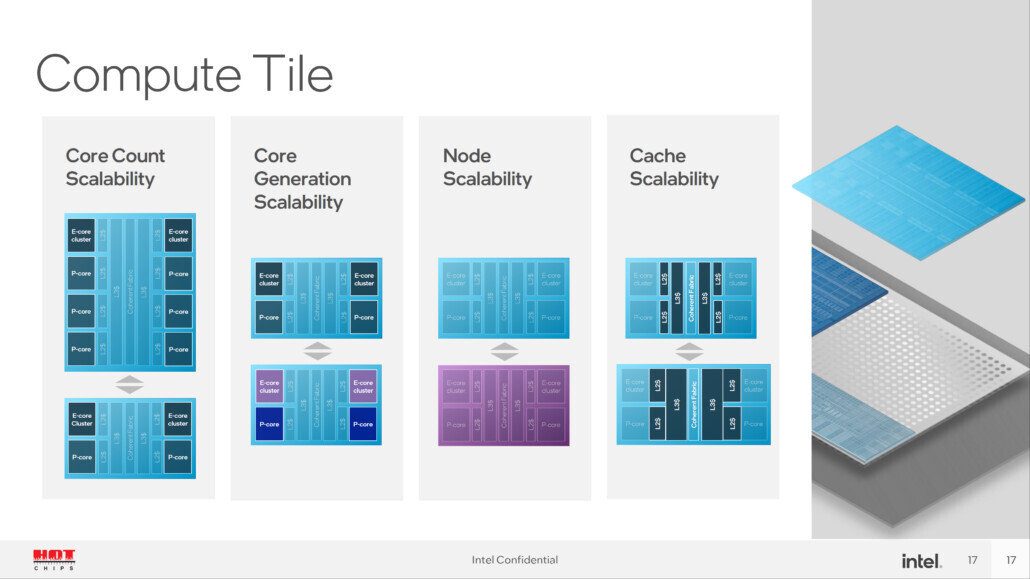
Intel Unleashes Enterprise AI with Gaudi 3, AI Open Systems Strategy and New Customer Wins
At the Intel Vision 2024 customer and partner conference, Intel introduced the Intel Gaudi 3 accelerator to bring performance, openness and choice to enterprise generative AI (GenAI), and unveiled a suite of new open scalable systems, next-gen products and strategic collaborations to accelerate GenAI adoption. With only 10% of enterprises successfully moving GenAI projects into production last year, Intel's latest offerings address the challenges businesses face in scaling AI initiatives.
"Innovation is advancing at an unprecedented pace, all enabled by silicon - and every company is quickly becoming an AI company," said Intel CEO Pat Gelsinger. "Intel is bringing AI everywhere across the enterprise, from the PC to the data center to the edge. Our latest Gaudi, Xeon and Core Ultra platforms are delivering a cohesive set of flexible solutions tailored to meet the changing needs of our customers and partners and capitalize on the immense opportunities ahead."


"Innovation is advancing at an unprecedented pace, all enabled by silicon - and every company is quickly becoming an AI company," said Intel CEO Pat Gelsinger. "Intel is bringing AI everywhere across the enterprise, from the PC to the data center to the edge. Our latest Gaudi, Xeon and Core Ultra platforms are delivering a cohesive set of flexible solutions tailored to meet the changing needs of our customers and partners and capitalize on the immense opportunities ahead."