ASUS IoT Announces PE8000G
ASUS IoT, the global AIoT solution provider, today announced PE8000G at Embedded World 2024, a powerful edge AI computer that supports multiple GPU cards for high performance—and is expertly engineered to handle rugged conditions with resistance to extreme temperatures, vibration and variable voltage. PE8000G is powered by formidable Intel Core processors (13th and 12th gen) and the Intel R680E chipset to deliver high-octane processing power and efficiency.
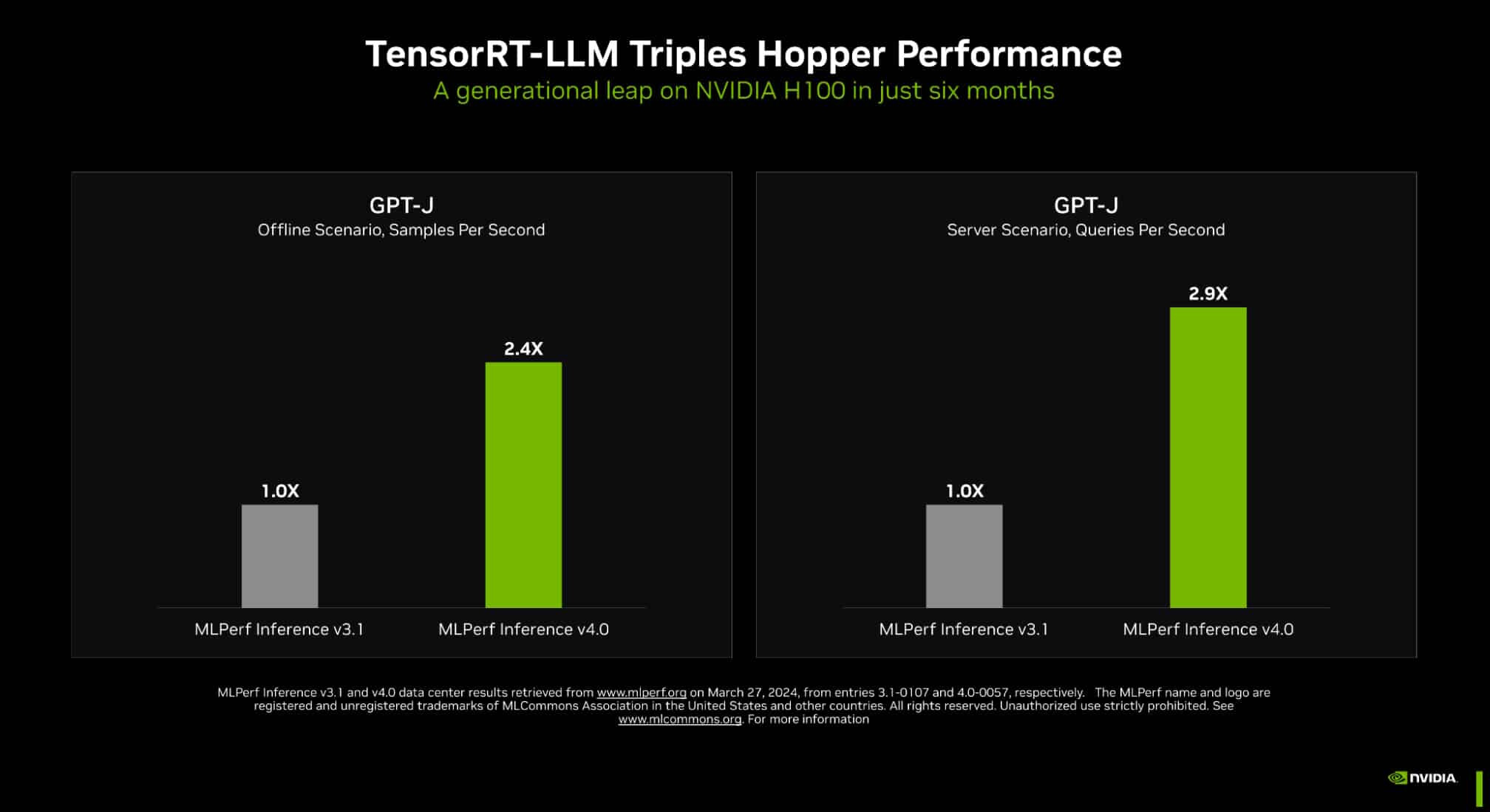
With its advanced architecture, PE8000G excels at running multiple neural network modules simultaneously in real-time—and represents a significant leap forward in edge AI computing. With its robust design, exceptional performance and wide range of features, PE8000G series is poised to revolutionize AI-driven applications across multiple industries, elevating edge AI computing to new heights and enabling organizations to tackle mission-critical tasks with confidence and to achieve unprecedented levels of productivity and innovation.


With its advanced architecture, PE8000G excels at running multiple neural network modules simultaneously in real-time—and represents a significant leap forward in edge AI computing. With its robust design, exceptional performance and wide range of features, PE8000G series is poised to revolutionize AI-driven applications across multiple industries, elevating edge AI computing to new heights and enabling organizations to tackle mission-critical tasks with confidence and to achieve unprecedented levels of productivity and innovation.