US Government Wants Nuclear Plants to Offload AI Data Center Expansion
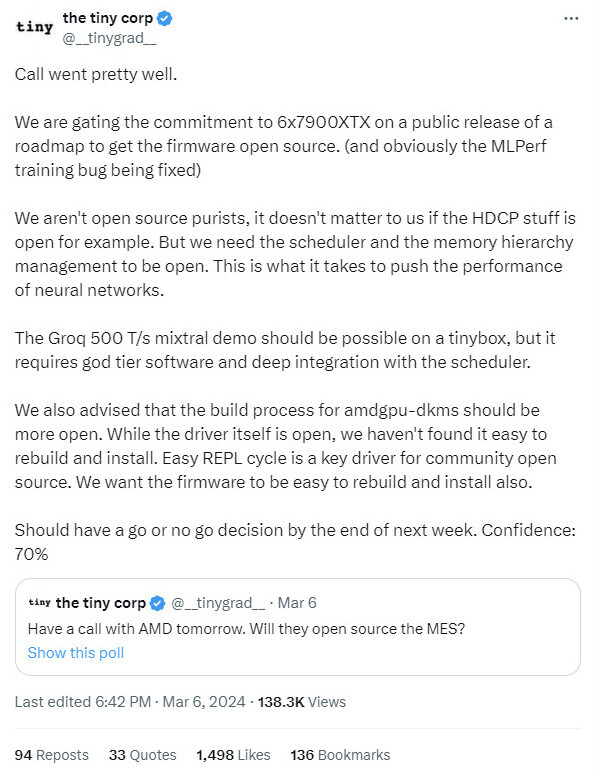
The expansion of AI technology affects not only the production and demand for graphics cards but also the electricity grid that powers them. Data centers hosting thousands of GPUs are becoming more common, and the industry has been building new facilities for GPU-enhanced servers to serve the need for more AI. However, these powerful GPUs often consume over 500 Watts per single card, and NVIDIA's latest Blackwell B200 GPU has a TGP of 1000 Watts or a single kilowatt. These kilowatt GPUs will be present in data centers with 10s of thousands of cards, resulting in multi-megawatt facilities. To combat the load on the national electricity grid, US President Joe Biden's administration has been discussing with big tech to re-evaluate their power sources, possibly using smaller nuclear plants. According to an Axios interview with Energy Secretary Jennifer Granholm, she has noted that "AI itself isn't a problem because AI could help to solve the problem." However, the problem is the load-bearing of the national electricity grid, which can't sustain the rapid expansion of the AI data centers.
The Department of Energy (DOE) has been reportedly talking with firms, most notably hyperscalers like Microsoft, Google, and Amazon, to start considering nuclear fusion and fission power plants to satisfy the need for AI expansion. We have already discussed the plan by Microsoft to embed a nuclear reactor near its data center facility and help manage the load of thousands of GPUs running AI training/inference. However, this time, it is not just Microsoft. Other tech giants are reportedly thinking about nuclear as well. They all need to offload their AI expansion from the US national power grid and develop a nuclear solution. Nuclear power is a mere 20% of the US power sourcing, and DOE is currently financing a Holtec Palisades 800-MW electric nuclear generating station with $1.52 billion in funds for restoration and resumption of service. Microsoft is investing in a Small Modular Reactors (SMRs) microreactor energy strategy, which could be an example for other big tech companies to follow.
The Department of Energy (DOE) has been reportedly talking with firms, most notably hyperscalers like Microsoft, Google, and Amazon, to start considering nuclear fusion and fission power plants to satisfy the need for AI expansion. We have already discussed the plan by Microsoft to embed a nuclear reactor near its data center facility and help manage the load of thousands of GPUs running AI training/inference. However, this time, it is not just Microsoft. Other tech giants are reportedly thinking about nuclear as well. They all need to offload their AI expansion from the US national power grid and develop a nuclear solution. Nuclear power is a mere 20% of the US power sourcing, and DOE is currently financing a Holtec Palisades 800-MW electric nuclear generating station with $1.52 billion in funds for restoration and resumption of service. Microsoft is investing in a Small Modular Reactors (SMRs) microreactor energy strategy, which could be an example for other big tech companies to follow.