Raevenlord
News Editor
- Joined
- Aug 12, 2016
- Messages
- 3,755 (1.23/day)
- Location
- Portugal
| System Name | The Ryzening |
|---|---|
| Processor | AMD Ryzen 9 5900X |
| Motherboard | MSI X570 MAG TOMAHAWK |
| Cooling | Lian Li Galahad 360mm AIO |
| Memory | 32 GB G.Skill Trident Z F4-3733 (4x 8 GB) |
| Video Card(s) | Gigabyte RTX 3070 Ti |
| Storage | Boot: Transcend MTE220S 2TB, Kintson A2000 1TB, Seagate Firewolf Pro 14 TB |
| Display(s) | Acer Nitro VG270UP (1440p 144 Hz IPS) |
| Case | Lian Li O11DX Dynamic White |
| Audio Device(s) | iFi Audio Zen DAC |
| Power Supply | Seasonic Focus+ 750 W |
| Mouse | Cooler Master Masterkeys Lite L |
| Keyboard | Cooler Master Masterkeys Lite L |
| Software | Windows 10 x64 |
The team at Videocardz has published a story with some interesting slides regarding AMD's push towards the highly-lucrative deep learning market with their INSTINCT line-up of graphics cards - and VEGA being announced as a full-fledged solution means we are perhaps (hopefully) closer to seeing a solution based on it for the consumer market as well.
Alongside the VEGA-based MI25, AMD also announced the MI6 (5.7 TFLOPS in FP32 operations, with 224 GB/s of memory bandwidth and <150 W of board power), looking suspiciously like a Polaris 10 card in disguise; and the MI8 (which appropriately delivers 8.2 TFLOPS in FP32 computations, as well as 512 GB/s memory bandwidth and <175 W typical board power), with the memory bandwidth numbers being the most telling, and putting the MI8 closely along a Fiji architecture-based solution.


The MI25 VEGA-based deep learning accelerator reportedly offers 25 TFLOPS in FP16 operations (which amounts to roughly 12.5 TFLOPS when working on FP32 mode) - still about 50% higher than AMD's Fiji architecture-based solutions. The MI25 is being touted as a passively cooled Training Accelerator, offering real competition towards NVIDIA's deep learning forays. Being accelerators as they are, they don't has any display outputs, putting it closely alongside NVIDIA's Tesla line of purely computing-oriented accelerators.
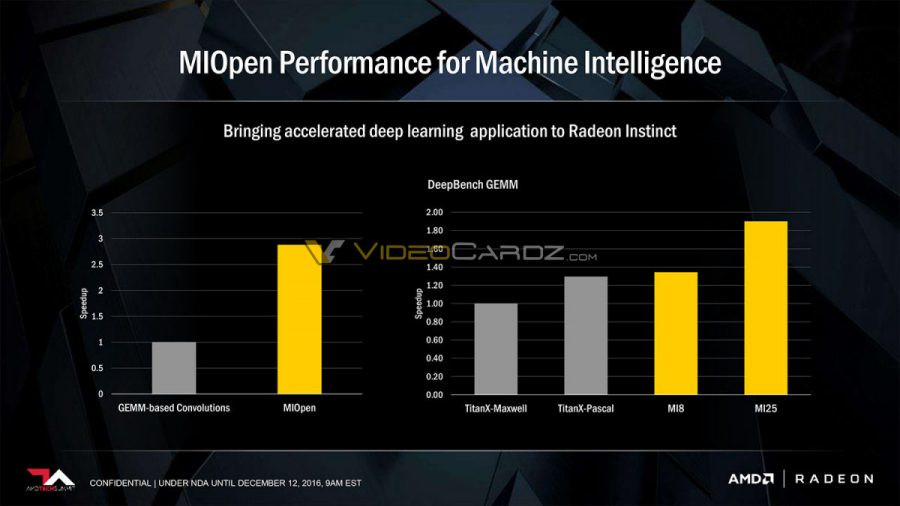
AMD pegs the MI25 as being almost 2 times faster than TITAN X Maxwell in DeepBench GEMM operations, and in the same press release, touts the symbiosis between their INSTINCT line of computing accelerators and the ZEN "Naples" platform as being optimized for GPU and Accelerator Throughput computing, with lower system costs, a lower latency architecture, peer to peer communication, and a high-density footprint - endowing a 39U computing rack with 120 VEGA MI25 INSTINCT accelerators and 3 PFLOPs in FP16 performance.




View at TechPowerUp Main Site
Alongside the VEGA-based MI25, AMD also announced the MI6 (5.7 TFLOPS in FP32 operations, with 224 GB/s of memory bandwidth and <150 W of board power), looking suspiciously like a Polaris 10 card in disguise; and the MI8 (which appropriately delivers 8.2 TFLOPS in FP32 computations, as well as 512 GB/s memory bandwidth and <175 W typical board power), with the memory bandwidth numbers being the most telling, and putting the MI8 closely along a Fiji architecture-based solution.


The MI25 VEGA-based deep learning accelerator reportedly offers 25 TFLOPS in FP16 operations (which amounts to roughly 12.5 TFLOPS when working on FP32 mode) - still about 50% higher than AMD's Fiji architecture-based solutions. The MI25 is being touted as a passively cooled Training Accelerator, offering real competition towards NVIDIA's deep learning forays. Being accelerators as they are, they don't has any display outputs, putting it closely alongside NVIDIA's Tesla line of purely computing-oriented accelerators.
AMD pegs the MI25 as being almost 2 times faster than TITAN X Maxwell in DeepBench GEMM operations, and in the same press release, touts the symbiosis between their INSTINCT line of computing accelerators and the ZEN "Naples" platform as being optimized for GPU and Accelerator Throughput computing, with lower system costs, a lower latency architecture, peer to peer communication, and a high-density footprint - endowing a 39U computing rack with 120 VEGA MI25 INSTINCT accelerators and 3 PFLOPs in FP16 performance.



View at TechPowerUp Main Site



") but yes there is a good chance that the MI25 is a dual gpu....
but yes there is a good chance that the MI25 is a dual gpu....