
- Joined
- Aug 20, 2007
- Messages
- 21,542 (3.40/day)
| System Name | Pioneer |
|---|---|
| Processor | Ryzen R9 9950X |
| Motherboard | GIGABYTE Aorus Elite X670 AX |
| Cooling | Noctua NH-D15 + A whole lotta Sunon and Corsair Maglev blower fans... |
| Memory | 64GB (4x 16GB) G.Skill Flare X5 @ DDR5-6000 CL30 |
| Video Card(s) | XFX RX 7900 XTX Speedster Merc 310 |
| Storage | Intel 905p Optane 960GB boot, +2x Crucial P5 Plus 2TB PCIe 4.0 NVMe SSDs |
| Display(s) | 55" LG 55" B9 OLED 4K Display |
| Case | Thermaltake Core X31 |
| Audio Device(s) | TOSLINK->Schiit Modi MB->Asgard 2 DAC Amp->AKG Pro K712 Headphones or HDMI->B9 OLED |
| Power Supply | FSP Hydro Ti Pro 850W |
| Mouse | Logitech G305 Lightspeed Wireless |
| Keyboard | WASD Code v3 with Cherry Green keyswitches + PBT DS keycaps |
| Software | Gentoo Linux x64 / Windows 11 Enterprise IoT 2024 |
Intel's "Xeon Scalable" lineup is designed to compete directly with AMD's Naples platform. Naples, a core-laden, high performance server platform that relies deeply on linking multiple core complexes together via AMD's own HyperTransport derived Infinity Fabric Interconnect has given intel some challenges in terms of how to structure its own high-core count family of devices. This has led to a new mesh-based interconnect technology from Intel.

When linking multiple core complexes together, Intel has traditionally relied on its QPI (Quick Path Interconnect) Interconnect, but it has its own limitations. For starters, QPI is a point to point technology, and it is inherently unsuitable for linking cores to cores in a mesh topology as is needed when random cores want to address each other. To work, you'd need to create a QPI link from every core to every other core on the chip, and that would be a waste of resources. Historically, to fill that gap Intel has used a "Ring bus." A ring bus functions similar to a token ring bus if you want to think of it in simple "old networking" terms. Basically, when data is transmitted, it must be passed around the bus like a token going from one speaker to the next. Each clock cycle, the bus can shift the data one way or another, but if you want to go say for example from one core to the farthest away one possible, latency suffers. In other words: This works fine for small dies, but as Intel seeks to create some true monsters, it's no longer enough.
There are some caveats to the above explanation (Intel's ring bus can have more than one "token" at a time in the analogy, and it's bidirectional, meaning data can travel both ways), but it still doesn't change the fact Intel is feeling this designs limits.
Enter the Mesh Interconnect:
Technically, this new Mesh Interconnect tech from Intel was introduced with the Xeon Phi Knight's Landing based products, but those are very exclusive, high end parts even for us mere enthusiast mortals. This launch represents the technology trickling down to a more mainstream market. To explain the tech, you simply have to forget everything you know about the ring bus chips used to use, and realize that now in the simplest chip implementations, each core has a direct "phone line" to every neighboring chip. It's a full mesh topology with all its benefits. In more complex arrangements, the "direct line to every chip" arrangement of course becomes uneconomical again, being it would require a harsh amount of resources for any chip maker to implement on massive chips the likes of which Naples and Xeon Scalable talk about. So instead, we go back to a simpler mesh topology, rows and columns.
Take this graphic, from Xeon Phi, to get an idea of how it works:

Basically, it's a grid with a full XY routing system. This means rather than run around a huge bus-like circle, they can go through a much more compact "cube" topology and save time. In a simple 3x3 cube example, whereas it would take a total of 8 clock cycles on an equivalent ringbus for communications to reach the farthest core, the most it can take on a Mesh Interconnect based core is 4. (-X-X+Y+Y is how the worst case routing would look, if you've been following this in that level of detail).
If a lot of this goes over your head, don't worry, it's pretty technical low level stuff. The bottom line is Intel has an Interconnect that can compete roughly with AMD's Infinity Fabric in its own respect, and given Intel's larger core count on each die, AMD may be wise to keep a watchful eye on that fact.
The Mesh interconnect is scheduled to debut in the much more "mainstream" (if you can call them that) markets of Xeon Scalable and Skylake-X, due to launch soon this year.
View at TechPowerUp Main Site

When linking multiple core complexes together, Intel has traditionally relied on its QPI (Quick Path Interconnect) Interconnect, but it has its own limitations. For starters, QPI is a point to point technology, and it is inherently unsuitable for linking cores to cores in a mesh topology as is needed when random cores want to address each other. To work, you'd need to create a QPI link from every core to every other core on the chip, and that would be a waste of resources. Historically, to fill that gap Intel has used a "Ring bus." A ring bus functions similar to a token ring bus if you want to think of it in simple "old networking" terms. Basically, when data is transmitted, it must be passed around the bus like a token going from one speaker to the next. Each clock cycle, the bus can shift the data one way or another, but if you want to go say for example from one core to the farthest away one possible, latency suffers. In other words: This works fine for small dies, but as Intel seeks to create some true monsters, it's no longer enough.
There are some caveats to the above explanation (Intel's ring bus can have more than one "token" at a time in the analogy, and it's bidirectional, meaning data can travel both ways), but it still doesn't change the fact Intel is feeling this designs limits.
Enter the Mesh Interconnect:
Technically, this new Mesh Interconnect tech from Intel was introduced with the Xeon Phi Knight's Landing based products, but those are very exclusive, high end parts even for us mere enthusiast mortals. This launch represents the technology trickling down to a more mainstream market. To explain the tech, you simply have to forget everything you know about the ring bus chips used to use, and realize that now in the simplest chip implementations, each core has a direct "phone line" to every neighboring chip. It's a full mesh topology with all its benefits. In more complex arrangements, the "direct line to every chip" arrangement of course becomes uneconomical again, being it would require a harsh amount of resources for any chip maker to implement on massive chips the likes of which Naples and Xeon Scalable talk about. So instead, we go back to a simpler mesh topology, rows and columns.
Take this graphic, from Xeon Phi, to get an idea of how it works:
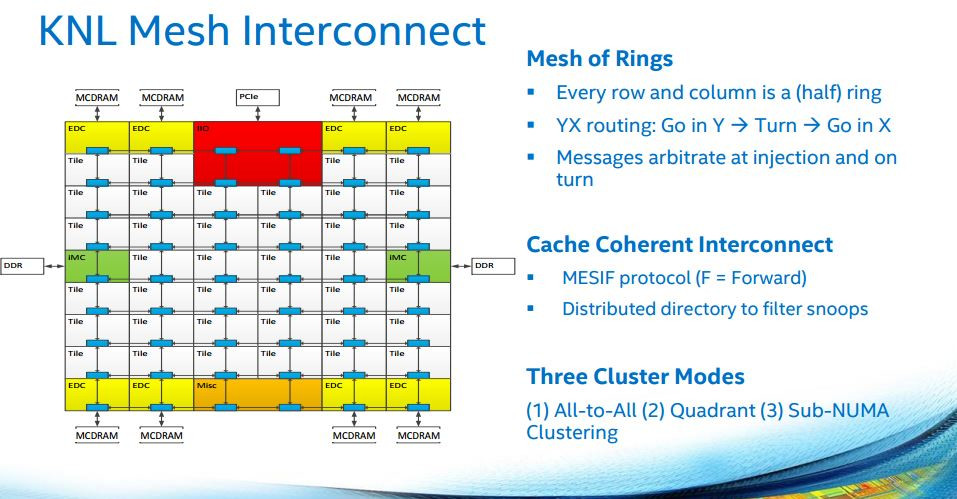
Basically, it's a grid with a full XY routing system. This means rather than run around a huge bus-like circle, they can go through a much more compact "cube" topology and save time. In a simple 3x3 cube example, whereas it would take a total of 8 clock cycles on an equivalent ringbus for communications to reach the farthest core, the most it can take on a Mesh Interconnect based core is 4. (-X-X+Y+Y is how the worst case routing would look, if you've been following this in that level of detail).
If a lot of this goes over your head, don't worry, it's pretty technical low level stuff. The bottom line is Intel has an Interconnect that can compete roughly with AMD's Infinity Fabric in its own respect, and given Intel's larger core count on each die, AMD may be wise to keep a watchful eye on that fact.
The Mesh interconnect is scheduled to debut in the much more "mainstream" (if you can call them that) markets of Xeon Scalable and Skylake-X, due to launch soon this year.
View at TechPowerUp Main Site
Last edited:




") ) and they need to push some technical stuff to the surface. Enough to generate topics like this one, but not very technical, so that you don't have to be a physicist or electrical engineer to participate in a discussion.
) and they need to push some technical stuff to the surface. Enough to generate topics like this one, but not very technical, so that you don't have to be a physicist or electrical engineer to participate in a discussion.

