- Joined
- Oct 9, 2007
- Messages
- 47,217 (7.55/day)
- Location
- Hyderabad, India
| System Name | RBMK-1000 |
|---|---|
| Processor | AMD Ryzen 7 5700G |
| Motherboard | ASUS ROG Strix B450-E Gaming |
| Cooling | DeepCool Gammax L240 V2 |
| Memory | 2x 8GB G.Skill Sniper X |
| Video Card(s) | Palit GeForce RTX 2080 SUPER GameRock |
| Storage | Western Digital Black NVMe 512GB |
| Display(s) | BenQ 1440p 60 Hz 27-inch |
| Case | Corsair Carbide 100R |
| Audio Device(s) | ASUS SupremeFX S1220A |
| Power Supply | Cooler Master MWE Gold 650W |
| Mouse | ASUS ROG Strix Impact |
| Keyboard | Gamdias Hermes E2 |
| Software | Windows 11 Pro |
AMD today held its "New Horizon" event for investors, offering guidance and "color" on what the company's near-future could look like. At the event, the company formally launched its Radeon Instinct MI60 GPU-based compute accelerator; and disclosed a few interesting tidbits on its next-generation "Zen 2" mircroarchitecture. The Instinct MI60 is the world's first GPU built on the 7 nanometer silicon fabrication process, and among the first commercially available products built on 7 nm. "Rome" is on track to becoming the first 7 nm processor, and is based on the Zen 2 architecture.
The Radeon Instinct MI60 is based on a 7 nm rendition of the "Vega" architecture. It is not an optical shrink of "Vega 10," and could have more number-crunching machinery, and an HBM2 memory interface that's twice as wide that can hold double the memory. It also features on-die logic that gives it hardware virtualization, which could be a boon for cloud-computing providers.





If you've been paying attention to our "Zen 2" coverage over the past couple of weeks, you would've read our recent article citing a Singapore-based VLSI engineer claiming that AMD could disintegrate the northbridge for its high core-count enterprise CPUs, in an attempt to make the memory I/O "truly" wide, without compromising on the idea of MCM CPU chiplets. All of that is true.
"Rome" is codename for a multi-chip module of four to eight 7 nm CPU dies, wired to a centralized die over InfinityFabric. This 14 nm die, called "I/O die," handles memory and PCIe, providing a monolithic 8-channel memory interface, overcoming the memory bandwidth bottlenecks of current-generation 4-die MCMs. The CPU dies and an I/O die probably share an interposer. Assuming each die has 8 CPU cores, "Rome" could have up to 64 cores, an 8-channel DDR4 memory interface, and a 96-lane PCI-Express gen 4.0 root-complex, per socket. If AMD has increased its core-count per CPU die, Rome's core count could be even higher.

The broader memory I/O, assuming InfinityFabric does its job, could significantly improve performance of multi-threaded workloads that can scale across as many cores as you can throw at them, utilizing a truly broader memory interface. AMD also speaks of "increased IPC," which bodes well for the client-segment. AMD has managed to increase IPC (per-core performance), with several on-die enhancements to the core design.
With "Zen" and "Zen+," AMD recognized several components on the core that could be broadened or made faster, which could bring about tangible IPC improvements. This includes a significantly redesigned front-end. Zen/Zen+ feature a front-end that's not much different than AMD's past micro-architectures. The new front-end includes an improved branch-predictor, a faster instruction prefetcher, an improved/enlarged L1 instruction cache, and an improved prefetcher cache (L2).
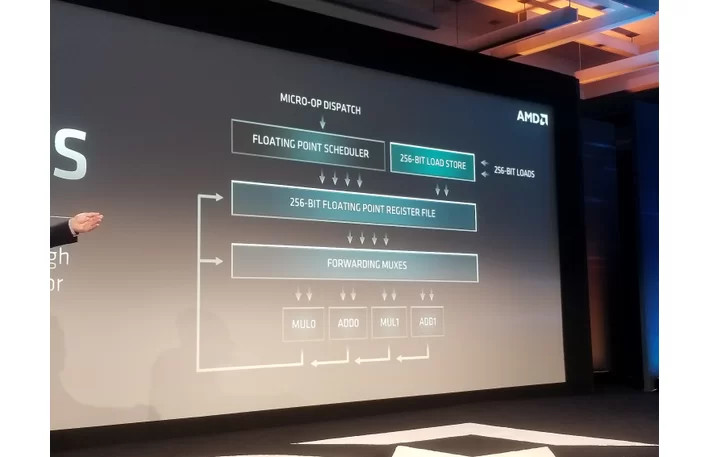
The number-crunching machinery, the floating point unit, also receives a massive overhaul. "Zen 2" features 256-bit FPUs, which are doubled in width compared to Zen. load/store/dispatch/retire bandwidths have been doubled over the current generation. These changes are massive. Given that even without these core-level changes, by simply improving cache latencies, AMD managed to eke out a ~3% IPC uplift with "Zen+," one can expect double-digit percentage IPC gains with "Zen 2." Higher IPC, combined with possible increased core counts, higher clock speeds, and power benefits of switching to 7 nm, complete AMD's "Zen 2" proposition.
View at TechPowerUp Main Site
The Radeon Instinct MI60 is based on a 7 nm rendition of the "Vega" architecture. It is not an optical shrink of "Vega 10," and could have more number-crunching machinery, and an HBM2 memory interface that's twice as wide that can hold double the memory. It also features on-die logic that gives it hardware virtualization, which could be a boon for cloud-computing providers.




If you've been paying attention to our "Zen 2" coverage over the past couple of weeks, you would've read our recent article citing a Singapore-based VLSI engineer claiming that AMD could disintegrate the northbridge for its high core-count enterprise CPUs, in an attempt to make the memory I/O "truly" wide, without compromising on the idea of MCM CPU chiplets. All of that is true.
"Rome" is codename for a multi-chip module of four to eight 7 nm CPU dies, wired to a centralized die over InfinityFabric. This 14 nm die, called "I/O die," handles memory and PCIe, providing a monolithic 8-channel memory interface, overcoming the memory bandwidth bottlenecks of current-generation 4-die MCMs. The CPU dies and an I/O die probably share an interposer. Assuming each die has 8 CPU cores, "Rome" could have up to 64 cores, an 8-channel DDR4 memory interface, and a 96-lane PCI-Express gen 4.0 root-complex, per socket. If AMD has increased its core-count per CPU die, Rome's core count could be even higher.

The broader memory I/O, assuming InfinityFabric does its job, could significantly improve performance of multi-threaded workloads that can scale across as many cores as you can throw at them, utilizing a truly broader memory interface. AMD also speaks of "increased IPC," which bodes well for the client-segment. AMD has managed to increase IPC (per-core performance), with several on-die enhancements to the core design.
With "Zen" and "Zen+," AMD recognized several components on the core that could be broadened or made faster, which could bring about tangible IPC improvements. This includes a significantly redesigned front-end. Zen/Zen+ feature a front-end that's not much different than AMD's past micro-architectures. The new front-end includes an improved branch-predictor, a faster instruction prefetcher, an improved/enlarged L1 instruction cache, and an improved prefetcher cache (L2).
The number-crunching machinery, the floating point unit, also receives a massive overhaul. "Zen 2" features 256-bit FPUs, which are doubled in width compared to Zen. load/store/dispatch/retire bandwidths have been doubled over the current generation. These changes are massive. Given that even without these core-level changes, by simply improving cache latencies, AMD managed to eke out a ~3% IPC uplift with "Zen+," one can expect double-digit percentage IPC gains with "Zen 2." Higher IPC, combined with possible increased core counts, higher clock speeds, and power benefits of switching to 7 nm, complete AMD's "Zen 2" proposition.
View at TechPowerUp Main Site














") (1.25x performance = frequency = 4.5 allcore possibility ~)
(1.25x performance = frequency = 4.5 allcore possibility ~)


")
