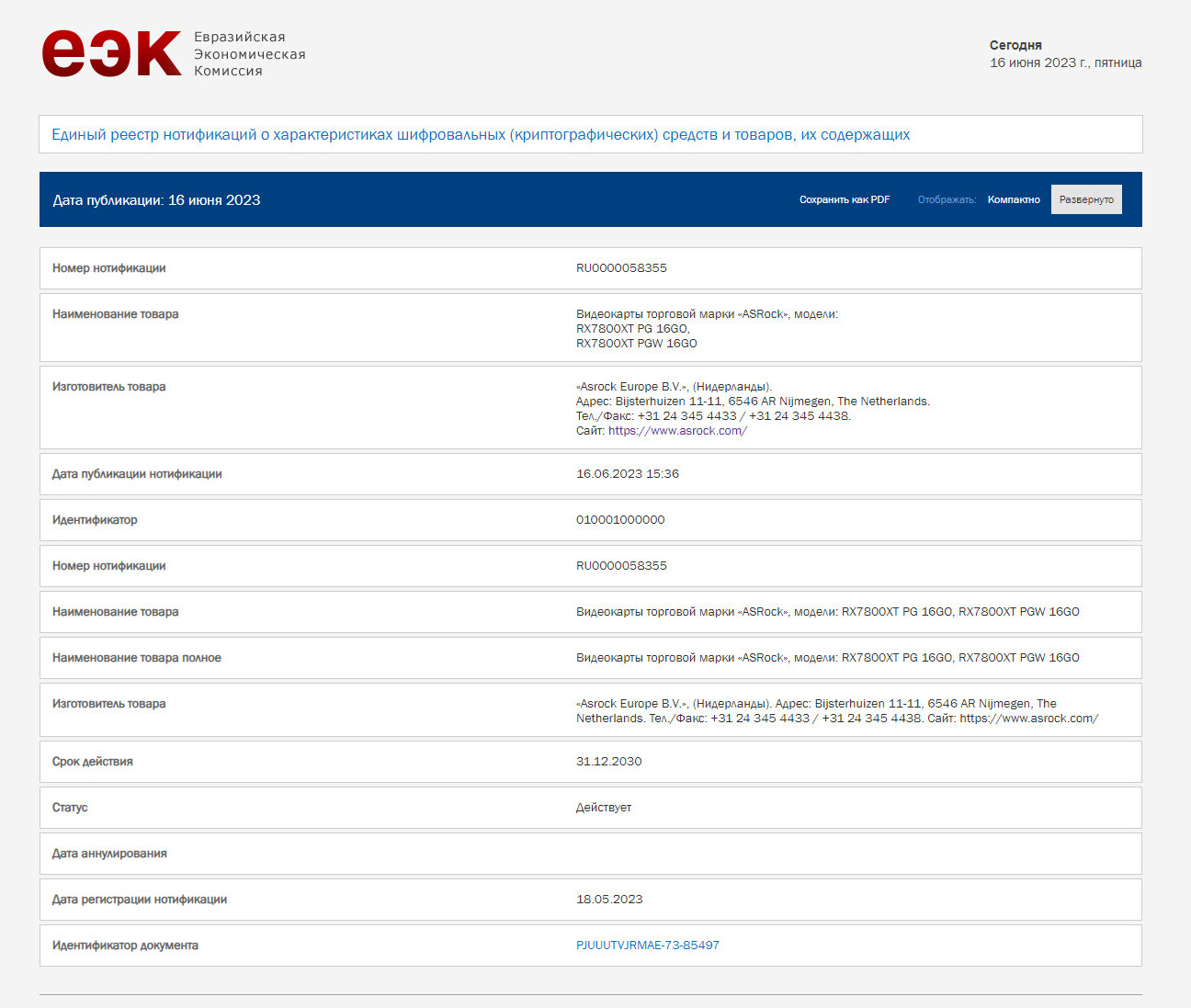
Am I the only one that thinks that the Igor's Lab simulation, while fascinating for how it was contrived, is kind of misleading for several reasons?
I haven't looked into if this is still the case, but pro parts used to run at a fixed clock. On top of that, they're likely using the parts with lowest leakage (the opposite of what they need for a gaming part).
I understand it's a rough approx., and value that he does stuff like this, but still.
IMO, and I could be wrong, Navi32 will be clocked pretty high (relatively speaking). I think ideally they would like/would have liked 2900mhz on 5nm. Who knows what it is ACTUALLY using. Let me explain.
5nm has shown to yield somewhere >2500-<2850mhz @ ~.88-.99v for a gpu reliably before power consumption goes bananas.
I think AMD was planning for 1.1v(~+) scaling (like Apples's 3.24ghz) on 5nm. So was nVIDIA, but it's more-so important for AMD.
People chastise AMD for the '3ghz+' design, but I truly think this philosophy included 5nm scaling with voltage/power consumption to 1.1v with a planned shrink to N4P/X (1.2v). Look at die size for a clue: If N31/N32 utilized these processes they would be the smallest 256-bit/384-bit designs possible (192mm for N32, just like RV670). The clock speed/pipeline is already in place, no need for extra decap; just a shrink to capitalize on better power characteristics and voltage scaling (22% better power scaling according to TSMC, which probably equates to 11% higher on the curve). I think AMD planned for 1.1v and then refreshing to 1.2v. In reality they got 1v for decent power scaling, N4P may ACTUALLY be 1.1v (or so), and N4X 1.2v for GPU/HPC designs.
While N4X may or may not come too late, N4P has been in production for quite some time. Apple achieved what would equate to 2930mhz @ 1v (efficient) and 3460mhz @ 1.2v (max).
If we are to believe what TSMC is saying, N4X would smooth the line to be something like 3000mhz @ 1v, 3300mhz @ 1.1v, 3600mhz @ 1.2v.
It would make sense if 5nm doesn't yield 2900+ reliably with decent power scaling/yield to put N32 on N4P, as it would then not only be more power efficient/yield better but actually, you know, be possible.
This way, they could use the same chip for both ~2900/20000 and/or as high as they can clock it reliably paired with 24000 GDDR6 (probably the intention for refresh on both parts).
For reference this is my personal belief on optimal 'pairing'. Numbers are approximate, but pretty close wrt bandwidth limitations:
12288sp/96MB L3/384-bit/20000: 2720mhz. Theoretically a very achievable clock/yield on 5nm. It is, in-fact, the Ada stock clock. In reality (MBA) 7900XTX was 2631 avg according to Wiz' review.
12288sp/192MB L3/384-bit/20000: As high as 5nm was ever going to clock. Cancelled because it didn't clock/yield (scale with decent power consumption) well-enough to need it.
12288sp/96MB L3/384-bit/24000: 3264mhz. This would work if 5nm scaled well-enough OR for a N4P/N4X refresh, depending on time table of manufacturing. Tons of options to get there. The 'ideal'.
10240sp/80MB L3/320-bit/20000: The same ratio as full N31 because 5/6 design. Very similar to a full AD103 but using larger bus/cache instead of faster ram. We never got this part.
10752sp/80MB L3/320-bit/20000: 2591mhz. This is close to what we got with 7900 XT. Probably set up this way because clock yields and/or power consumption/clock scaling was bad.
7680sp/64MB/256-bit/20000: 2900mhz. This works theoretically both as best-case (realistically) on 5nm or worse-case on N4P/X. Since it is a smaller chip, makes sense to put it high on the curve or test with.
7680sp/64MB/256-bit/24000: 3480mhz. A clock in this vicinity would have always required N4P/N4X. It would be very similar to a 4070ti/6950XT.
I think when you look at it like that, it all starts to make sense...especially if you figure that designs would've been plotted before they knew what 5nm would actually achieve.
I'm not trying to start rumors, get anyone's hopes up with copium/hopium, nor be a conspiracy theorist. Only trying to put things in perspective. This is the only way it makes sense.
It's possible N4P too doesn't perform to expectations for the high-end; it's possible N4X came too late compared to N3E (and what's possible there with early yields). It's possible N32 ended up a successful or unsuccessful pipe-cleaner for N31. It's possible it's not. It's possible they could get N5 to the ideal 20000 N32 level with what they believe is acceptable power/yield. It's possible the part will be clocked low; in reality while ~4070ti/6950xt is an ideal for the design, they really only NEED an ~6800xt/4070 (a PC equivalent to the PS5pro) at an equal/lesser and sustainable price, which they can't do with N21. nVIDIA made this clear with how they positioned the 4070 in performance. AMD may make this clear with price (in which a lower avg perf = lower cost to make). It's sad, but I think everyone knows this chip has to compete in price with 4060 ti in price even though it will perform much better.
Who knows what will happen, but I hope AMD is able to capitalize on the promise of the design before it becomes irrelevant, because it *could* be quite clever if it ever works out, process/time permitting, and prove their design methodology. Small chips, high clocks, but not at the expense of ridiculous power consumption. Split processes, same performance tier, and cheap. Sadly, allowing the lower price ratio people will pay for AMD GPUs with similar performance to one from nvidia (essentially they have to compete one tier down).
That timetable too is arguable, especially since they just released a 6nm GPU and are releasing a 7nm CPU which do (7600 being similar to a PS5 gpu) and likely will (allow budget stock AM4 users to use a high-end GPU) fulfill their purpose. Perhaps those refreshes/performance levels will still happen with these designs, simply later. One must admit, it would be quite welcome to see at AMD's price ratios, whenever it could occur.
Thank you for coming to my Ted Talk.