The highlight here was really the CUDIMM preview. I can't wait for the Trident Z5 CK's to be available worldwide, hopefully sooner rather than later. The 9600 MT/s model got listed $389 on Newegg, so it's gonna be a bit expensive, but totally worth it. Just hope my CPU's IMC can take it, at least into the 8000's. 7600 was easy with my existing 6800 kit.
But why would you use it on a 14th gen CPU? The clock redriver will be useless on a platform that doesn't support it, and so far only ARL does so in desktop. Zen 5 doesn't work with it either (i mean, you can use the dimms, just not take advantage of the clock redriver part).
CUDIMMs should be compatible with Raptor Lake as well
Any source on that? AFAIK it does not, as I said above.
In this steaming mess that Windows has become, one is now forced to see the results on Linux, and results on Linux have spoken.
Kudos to Intel for being a generation behind in performance, and probably two generations behind in consumption. Kudos indeed, it was not easy.

www.phoronix.com
View attachment 368777
For some tasks in there the 285k was pretty okay with acceptable power consumption, like in compile workloads where it matched the 9950x.
However, it got wrecked in AVX-512 tests.
Here's the link for all the tests, with the mean per test suite right at the bottom:
In some it wins, in other it matches, in others it gets heavily beaten.
Given that it's priced higher, it's really not a better option compared to ryzen 9000.
Perhaps some form of high-speed on package memory could supplement trips to the system RAM, like what Apple is doing with M-class SOCs? 8-16GB might help offset system costs, even if that means CPU prices go up some. That really seems like the future to me, where system RAM takes a step back for intensive workloads. Sure, eventually an app needs to hit system RAM, but perhaps the next major gain is to keep more tasks on-package. X3Ds do this already, and if they could clock as high as non-3DV chips, there would be no losses.
On-package RAM is either HBM or LPDDR, and both have really high latency, so it'll make things even worse.
Just look at Lunar Lake, memory latency in there is awful and memory is on package.
Memory latency on M-chips is also bad because LPDDR as well.
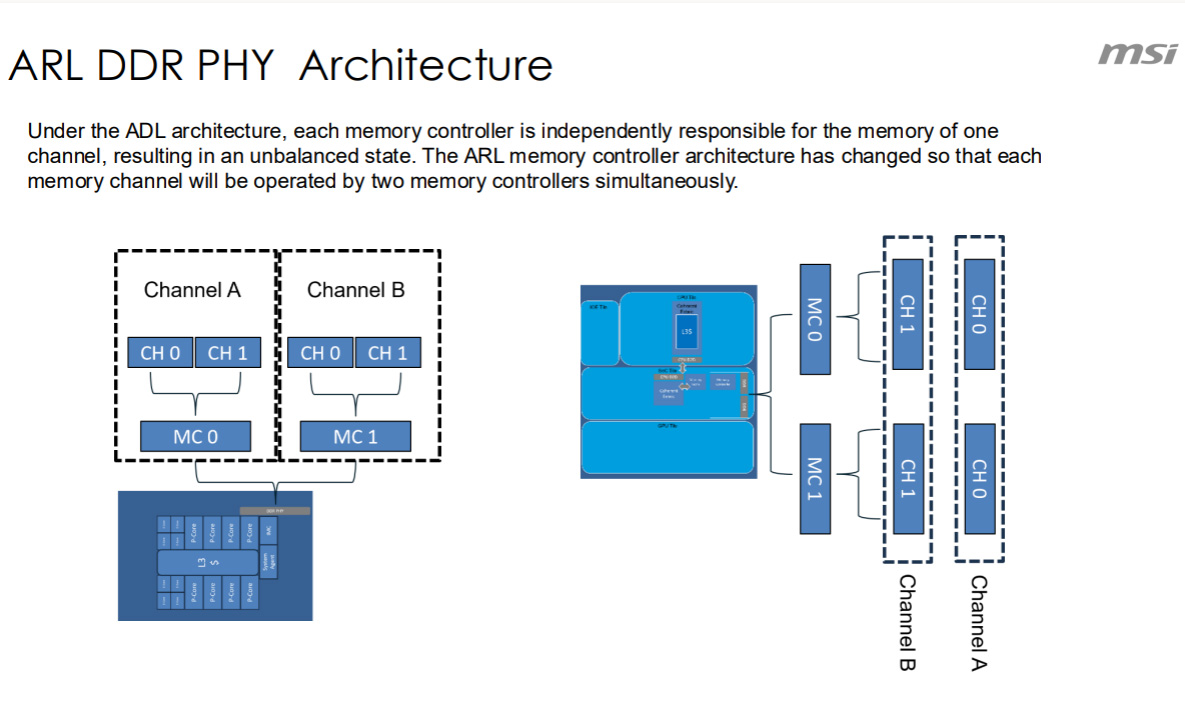
ARL allows one channel addressing sub-channel 1 on both sticks, and the other channel addressing sub-channel 2 on both sticks. I wonder if this means changing a value in each sub-channel could be done in one cycle, rather than taking two cycles with older MC.
It's 4 different, independent 32-bit (without counting the control pins) controllers, each going to a sub-channel in the DIMM.
You are assuming that the previous 64-bit controller was not able to do independent data transfers to each sub-channel, do you have any source on that? AFAIK, it was capable of doing so.
The main reason it's now 4x32-bit controllers instead of 2x64-bit it's because the SoC tile of ARL is pretty much a copy-paste from MTL.






{kind=link}