Raevenlord
News Editor
- Joined
- Aug 12, 2016
- Messages
- 3,755 (1.18/day)
- Location
- Portugal
| System Name | The Ryzening |
|---|---|
| Processor | AMD Ryzen 9 5900X |
| Motherboard | MSI X570 MAG TOMAHAWK |
| Cooling | Lian Li Galahad 360mm AIO |
| Memory | 32 GB G.Skill Trident Z F4-3733 (4x 8 GB) |
| Video Card(s) | Gigabyte RTX 3070 Ti |
| Storage | Boot: Transcend MTE220S 2TB, Kintson A2000 1TB, Seagate Firewolf Pro 14 TB |
| Display(s) | Acer Nitro VG270UP (1440p 144 Hz IPS) |
| Case | Lian Li O11DX Dynamic White |
| Audio Device(s) | iFi Audio Zen DAC |
| Power Supply | Seasonic Focus+ 750 W |
| Mouse | Cooler Master Masterkeys Lite L |
| Keyboard | Cooler Master Masterkeys Lite L |
| Software | Windows 10 x64 |
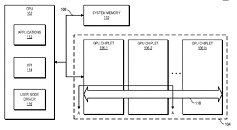
AMD on April 1st published a new patent application that seems to show the way its chiplet GPU design is moving towards. Before you say it, it's a patent application; there's no possibility for an April Fool's joke on this sort of move. The new patent develops on AMD's previous one, which only featured a passive bridge connecting the different GPU chiplets and their processing resources. If you want to read a slightly deeper dive of sorts on what chiplets are and why they are important for the future of graphics (and computing in general), look to this article here on TPU.
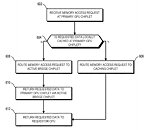
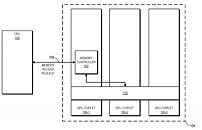
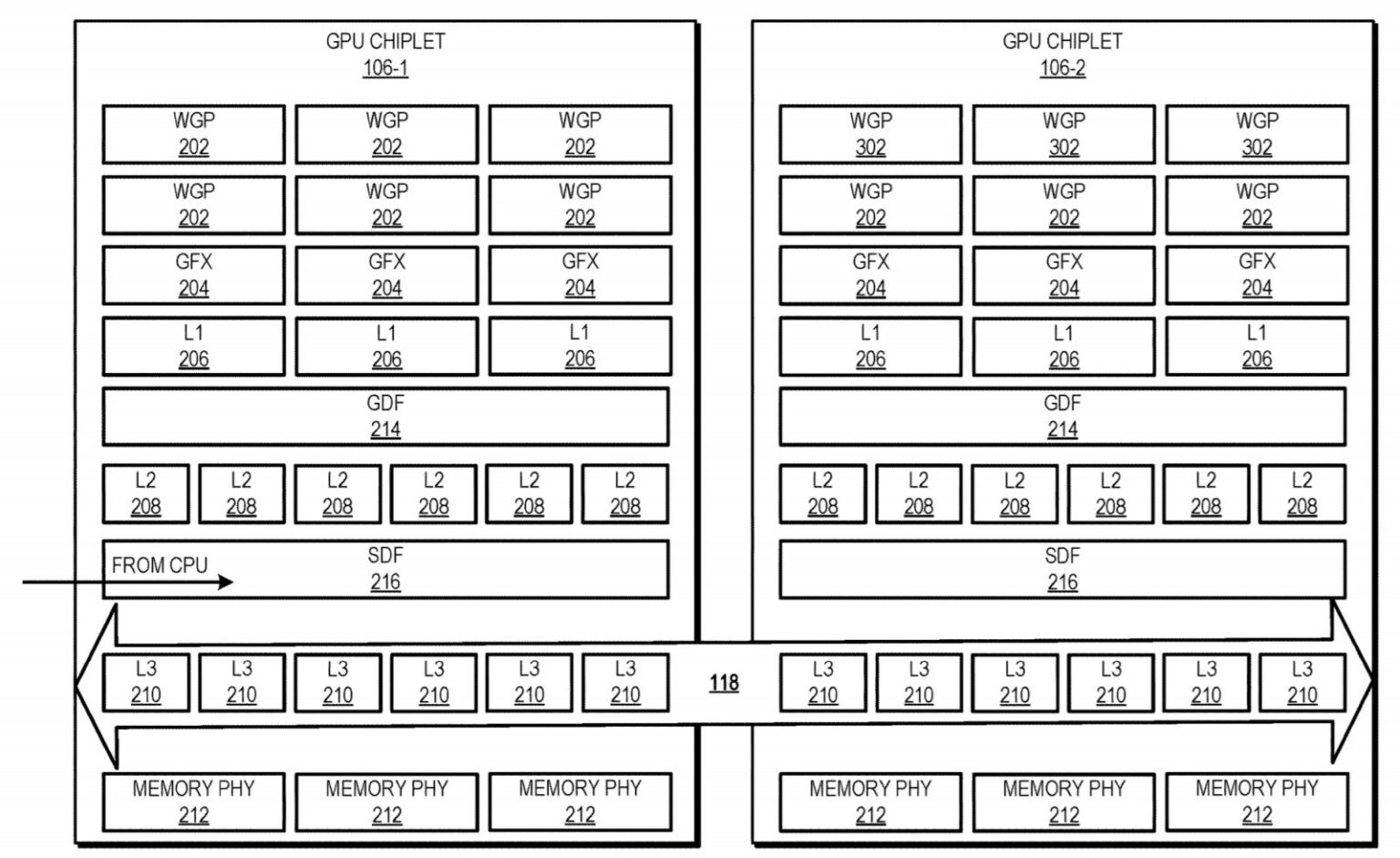
The new design interprets the active bridge connecting the chiplets as a last-level cache - think of it as L3, a unifying highway of data that is readily exposed to all the chiplets (in this patent, a three-chiplet design). It's essentially AMD's RDNA 2 Infinity Cache, though it's not only used as a cache here (and for good effect, if the Infinity Cache design on RDNA 2 and its performance uplift is anything to go by); it also serves as an active interconnect between the GPU chiplets that allow for the exchange and synchronization of information, whenever and however required. This also allows for the registry and cache to be exposed as a unified block for developers, abstracting them from having to program towards a system with a tri-way cache design. There are also of course yield benefits to be taken here, as there are with AMD's Zen chiplet designs, and the ability to scale up performance without any monolithic designs that are heavy in power requirements. The integrated, active cache bridge would also certainly help in reducing latency and maintaining chiplet processing coherency.

View at TechPowerUp Main Site
The new design interprets the active bridge connecting the chiplets as a last-level cache - think of it as L3, a unifying highway of data that is readily exposed to all the chiplets (in this patent, a three-chiplet design). It's essentially AMD's RDNA 2 Infinity Cache, though it's not only used as a cache here (and for good effect, if the Infinity Cache design on RDNA 2 and its performance uplift is anything to go by); it also serves as an active interconnect between the GPU chiplets that allow for the exchange and synchronization of information, whenever and however required. This also allows for the registry and cache to be exposed as a unified block for developers, abstracting them from having to program towards a system with a tri-way cache design. There are also of course yield benefits to be taken here, as there are with AMD's Zen chiplet designs, and the ability to scale up performance without any monolithic designs that are heavy in power requirements. The integrated, active cache bridge would also certainly help in reducing latency and maintaining chiplet processing coherency.



View at TechPowerUp Main Site





