- Joined
- Oct 9, 2007
- Messages
- 47,670 (7.43/day)
- Location
- Dublin, Ireland
| System Name | RBMK-1000 |
|---|---|
| Processor | AMD Ryzen 7 5700G |
| Motherboard | Gigabyte B550 AORUS Elite V2 |
| Cooling | DeepCool Gammax L240 V2 |
| Memory | 2x 16GB DDR4-3200 |
| Video Card(s) | Galax RTX 4070 Ti EX |
| Storage | Samsung 990 1TB |
| Display(s) | BenQ 1440p 60 Hz 27-inch |
| Case | Corsair Carbide 100R |
| Audio Device(s) | ASUS SupremeFX S1220A |
| Power Supply | Cooler Master MWE Gold 650W |
| Mouse | ASUS ROG Strix Impact |
| Keyboard | Gamdias Hermes E2 |
| Software | Windows 11 Pro |
In case you missed it, AMD's new madcap enthusiast silicon engineering effort, the "Strix Halo," is real, and comes with the Ryzen AI Max 300 series branding. These are chiplet-based mobile processors with one or two "Zen 5" CCDs—same ones found in "Granite Ridge" desktop processors—paired with a large SoC die that has an oversized iGPU. This arrangement lets AMD give the processor up to 16 full-sized "Zen 5" CPU cores, and an iGPU with as many as 40 RDNA 3.5 compute units (2,560 stream processors), and a 256-bit LPDDR5/x memory interface for UMA.
"Strix Halo" is designed for ultraportable gaming notebooks or mobile workstations where low PCB footprint is of the essence, and discrete GPU is not an option. For enthusiast gaming notebooks with discrete GPUs, AMD is designing the "Fire Range" processor, which is essentially a mobile BGA version of "Granite Ridge," and a successor to the Ryzen 7045 series "Dragon Range." The Ryzen AI Max series has three models based on CPU and iGPU CU counts—the Ryzen AI Max 395+ (16-core/32-thread with 40 CU), the Ryzen AI Max 390 (12-core/24-thread with 40 CU), and the Ryzen AI Max 385 (8-core/16-thread, 32 CU). An alleged Ryzen AI Max 390 engineering sample surfaced on the Geekbench AI benchmark online database.
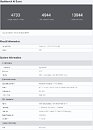
The online database entry for this Geekbench AI benchmark submission mentions a processor that identifies itself as "AMD Eng Sample: 100-000001421-50_Y," which corresponds with the Ryzen AI Max 390 (12-core/24-thread, 40 CU). The processor has a CPU base frequency of 3.20 GHz, and maximum boost frequency of 5.00 GHz, at least for this engineering sample (the retail chip could differ). This processor is driving a prototype HP ZBook Ultra 14 G1a mobile workstation, and is wired to 64 GB of memory.
The processor yielded a single-precision Geekbench AI score of 4733 points, half-precision score of 4944 points, and quantized score of 13944 points. HotHardware notes that this is a rather large 60% delta with the desktop Ryzen 9 9900X processor. There could be several reasons behind this. The screenshot shows that the notebook is running on a Balanced power plan; and the benchmark uses 256-bit AVX2 SIMD instructions, and not the newer AVX512. The "Zen 5" cores on the "Strix Halo" are carried over from "Granite Ridge" and EPYC "Turin," since they're the same 8-core CCD, and feature full 512-bit FP data-paths. This is unlike the "Zen 5" cores on the "Strix Point" monolithic silicon, which are restricted to a dual-pumped 256-bit FP data-path even when executing AVX512 or VNNI instructions. Therefore, AI benchmarks that use AVX512/VNNI could yield different results. Then there's the fact that this is an engineering sample, and AMD could be deliberately nerfing its performance.
View at TechPowerUp Main Site | Source
"Strix Halo" is designed for ultraportable gaming notebooks or mobile workstations where low PCB footprint is of the essence, and discrete GPU is not an option. For enthusiast gaming notebooks with discrete GPUs, AMD is designing the "Fire Range" processor, which is essentially a mobile BGA version of "Granite Ridge," and a successor to the Ryzen 7045 series "Dragon Range." The Ryzen AI Max series has three models based on CPU and iGPU CU counts—the Ryzen AI Max 395+ (16-core/32-thread with 40 CU), the Ryzen AI Max 390 (12-core/24-thread with 40 CU), and the Ryzen AI Max 385 (8-core/16-thread, 32 CU). An alleged Ryzen AI Max 390 engineering sample surfaced on the Geekbench AI benchmark online database.

The online database entry for this Geekbench AI benchmark submission mentions a processor that identifies itself as "AMD Eng Sample: 100-000001421-50_Y," which corresponds with the Ryzen AI Max 390 (12-core/24-thread, 40 CU). The processor has a CPU base frequency of 3.20 GHz, and maximum boost frequency of 5.00 GHz, at least for this engineering sample (the retail chip could differ). This processor is driving a prototype HP ZBook Ultra 14 G1a mobile workstation, and is wired to 64 GB of memory.
The processor yielded a single-precision Geekbench AI score of 4733 points, half-precision score of 4944 points, and quantized score of 13944 points. HotHardware notes that this is a rather large 60% delta with the desktop Ryzen 9 9900X processor. There could be several reasons behind this. The screenshot shows that the notebook is running on a Balanced power plan; and the benchmark uses 256-bit AVX2 SIMD instructions, and not the newer AVX512. The "Zen 5" cores on the "Strix Halo" are carried over from "Granite Ridge" and EPYC "Turin," since they're the same 8-core CCD, and feature full 512-bit FP data-paths. This is unlike the "Zen 5" cores on the "Strix Point" monolithic silicon, which are restricted to a dual-pumped 256-bit FP data-path even when executing AVX512 or VNNI instructions. Therefore, AI benchmarks that use AVX512/VNNI could yield different results. Then there's the fact that this is an engineering sample, and AMD could be deliberately nerfing its performance.
View at TechPowerUp Main Site | Source




