MangoBoost Achieves Record-Breaking MLPerf Inference v5.0 Results with AMD Instinct MI300X
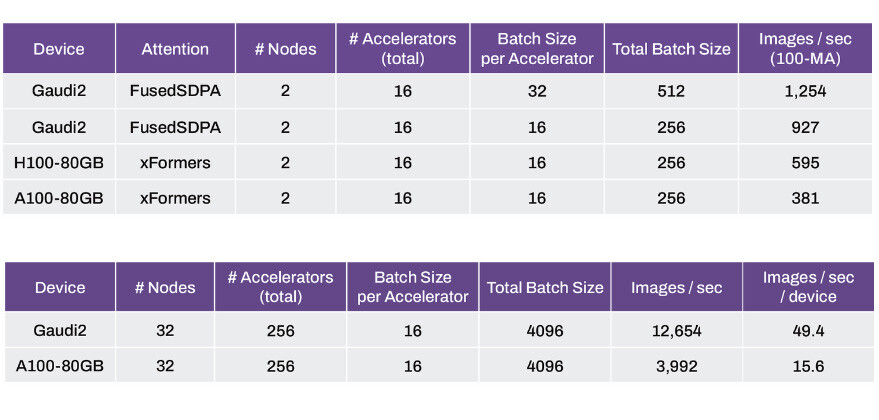
MangoBoost, a provider of cutting-edge system solutions designed to maximize AI data center efficiency, has set a new industry benchmark with its latest MLPerf Inference v5.0 submission. The company's Mango LLMBoost AI Enterprise MLOps software has demonstrated unparalleled performance on AMD Instinct MI300X GPUs, delivering the highest-ever recorded results for Llama2-70B in the offline inference category. This milestone marks the first-ever multi-node MLPerf inference result on AMD Instinct MI300X GPUs. By harnessing the power of 32 MI300X GPUs across four server nodes, Mango LLMBoost has surpassed all previous MLPerf inference results, including those from competitors using NVIDIA H100 GPUs.
Unmatched Performance and Cost Efficiency
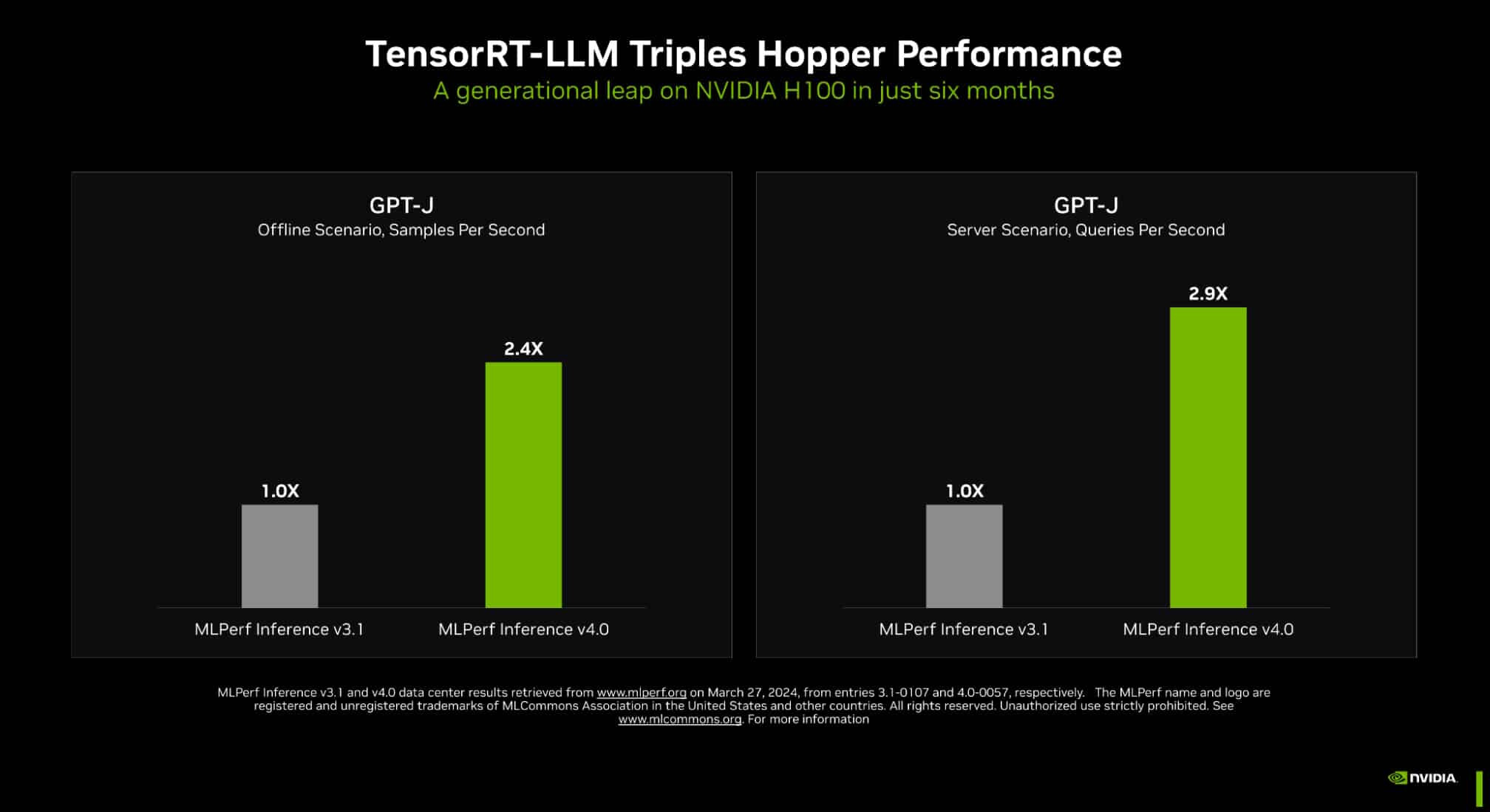
MangoBoost's MLPerf submission demonstrates a 24% performance advantage over the best-published MLPerf result from Juniper Networks utilizing 32 NVIDIA H100 GPUs. Mango LLMBoost achieved 103,182 tokens per second (TPS) in the offline scenario and 93,039 TPS in the server scenario on AMD MI300X GPUs, outperforming the previous best result of 82,749 TPS on NVIDIA H100 GPUs. In addition to superior performance, Mango LLMBoost + MI300X offers significant cost advantages. With AMD MI300X GPUs priced between $15,000 and $17,000—compared to the $32,000-$40,000 cost of NVIDIA H100 GPUs (source: Tom's Hardware—H100 vs. MI300X Pricing)—Mango LLMBoost delivers up to 62% cost savings while maintaining industry-leading inference throughput.

Unmatched Performance and Cost Efficiency
MangoBoost's MLPerf submission demonstrates a 24% performance advantage over the best-published MLPerf result from Juniper Networks utilizing 32 NVIDIA H100 GPUs. Mango LLMBoost achieved 103,182 tokens per second (TPS) in the offline scenario and 93,039 TPS in the server scenario on AMD MI300X GPUs, outperforming the previous best result of 82,749 TPS on NVIDIA H100 GPUs. In addition to superior performance, Mango LLMBoost + MI300X offers significant cost advantages. With AMD MI300X GPUs priced between $15,000 and $17,000—compared to the $32,000-$40,000 cost of NVIDIA H100 GPUs (source: Tom's Hardware—H100 vs. MI300X Pricing)—Mango LLMBoost delivers up to 62% cost savings while maintaining industry-leading inference throughput.