MSI Released AGESA COMBO PI V2 1.2.0.1 Beta BIOS for AMD 500 Series Motherboards
MSI, a world-leading motherboard manufacturer, announces the release of AGESA COMBO PI V2 1.2.0.1 beta BIOS for its AMD 500 series motherboards to add SMART ACCESS MEMORY support to AMD RYZEN 3000 desktop processors. Now both RYZEN 5000 and RYZEN 3000* desktop processors support SMART ACCESS MEMORY. AGESA COMBO PI V2 1.2.0.1 BIOS also improves L3 Cache bandwidth in AIDA64 for RYZEN 5000 desktop processors.
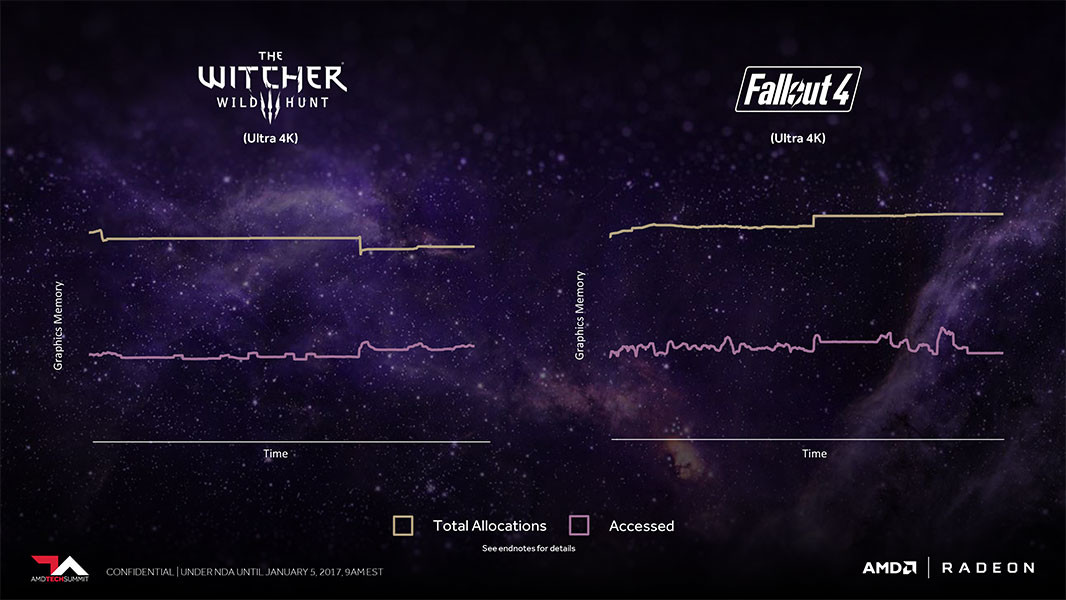
SMART ACCESS MEMORY is an innovative feature that allows the system to access the full capacity of the VRAM on the graphics card. Compare to the current solution which has a 256 MB access limitation, this feature will provide the users a better gaming experience.
SMART ACCESS MEMORY is an innovative feature that allows the system to access the full capacity of the VRAM on the graphics card. Compare to the current solution which has a 256 MB access limitation, this feature will provide the users a better gaming experience.