Monday, January 4th 2021

AMD Patents Chiplet Architecture for Radeon GPUs
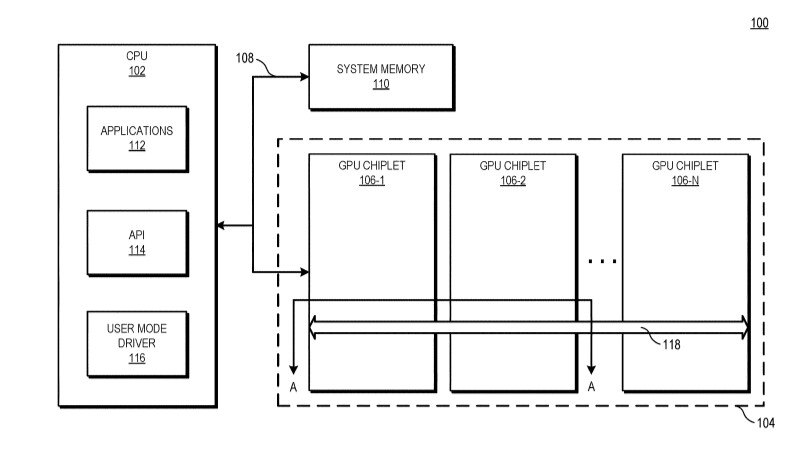
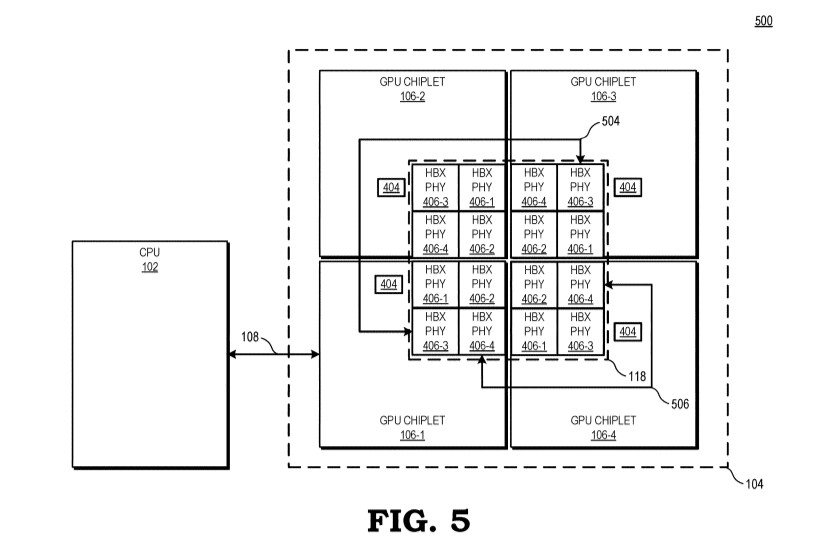
On December 31st, AMD's Radeon group has filed a patent for a chiplet architecture of the GPU, showing its vision about the future of Radeon GPUs. Currently, all of the GPUs available on the market utilize the monolithic approach, meaning that the graphics processing units are located on a single die. However, the current approach has its limitations. As the dies get bigger for high-performance GPU configurations, they are more expensive to manufacture and can not scale that well. Especially with modern semiconductor nodes, the costs of dies are rising. For example, it would be more economically viable to have two dies that are 100 mm² in size each than to have one at 200 mm². AMD realized that as well and has thus worked on a chiplet approach to the design.
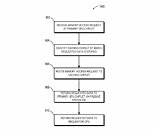
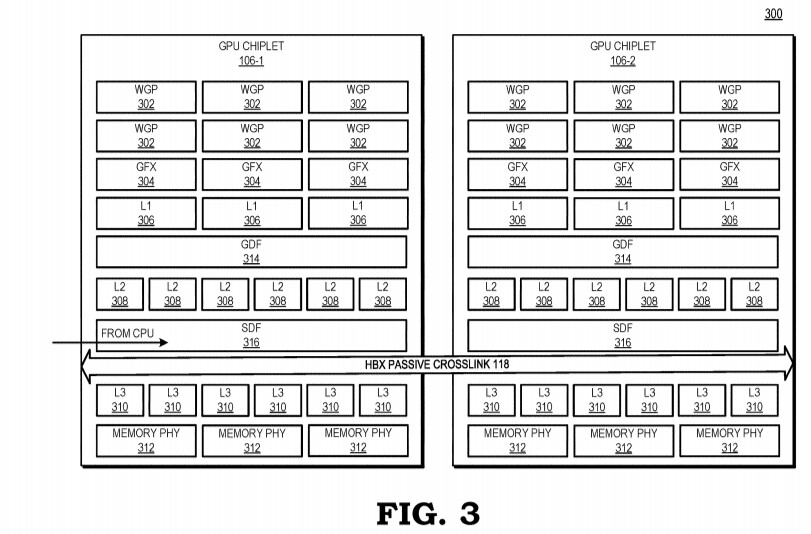
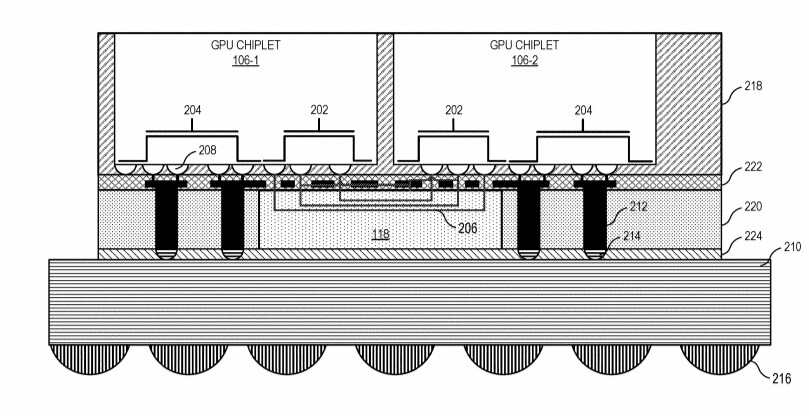
AMD reports that the use of multiple GPU configuration is inefficient due to limited software support, so that is the reason why GPUs were kept monolithic for years. However, it seems like the company has found a way to go past the limitations and implement a sufficient solution. AMD believes that by using its new high bandwidth passive crosslinks, it can achieve ideal chiplet-to-chiplet communication, where each GPU in the chiplet array would be coupled to the first GPU in the array. All the communication would go through an active interposer which would contain many layers of wires that are high bandwidth passive crosslinks. The company envisions that the first GPU in the array would communicably be coupled to the CPU, meaning that it will have to use the CPU possibly as a communication bridge for the GPU arrays. Such a thing would have big latency hit so it is questionable what it means really.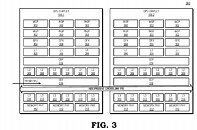
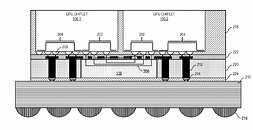
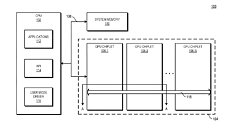 The patent also suggests that each GPU chiplet uses its own Last Level Cache (LLC), instead of separate LLCs for each GPU, so each of the LLCs is communicably coupled and the cache remains coherent across all chiplets. Rumors suggest that we are going to see the first chiplet-based architecture from AMD as successor to the RDNA3 generation, so it will happen in the coming years. AMD already has experience with chiplets from its processors, with Ryzen processors being the prime example. We just need to wait and see how it will look once it arrives for GPUs.
The patent also suggests that each GPU chiplet uses its own Last Level Cache (LLC), instead of separate LLCs for each GPU, so each of the LLCs is communicably coupled and the cache remains coherent across all chiplets. Rumors suggest that we are going to see the first chiplet-based architecture from AMD as successor to the RDNA3 generation, so it will happen in the coming years. AMD already has experience with chiplets from its processors, with Ryzen processors being the prime example. We just need to wait and see how it will look once it arrives for GPUs.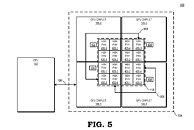

Sources:
Free Patents Online, via VideoCardz
AMD reports that the use of multiple GPU configuration is inefficient due to limited software support, so that is the reason why GPUs were kept monolithic for years. However, it seems like the company has found a way to go past the limitations and implement a sufficient solution. AMD believes that by using its new high bandwidth passive crosslinks, it can achieve ideal chiplet-to-chiplet communication, where each GPU in the chiplet array would be coupled to the first GPU in the array. All the communication would go through an active interposer which would contain many layers of wires that are high bandwidth passive crosslinks. The company envisions that the first GPU in the array would communicably be coupled to the CPU, meaning that it will have to use the CPU possibly as a communication bridge for the GPU arrays. Such a thing would have big latency hit so it is questionable what it means really.


69 Comments on AMD Patents Chiplet Architecture for Radeon GPUs
But, When?
They also need something clever to avoid the latency hits, the memory duplication issues etc.
GPUs aren't CPUs where core to core communication happens all the time.
CUs might not need to communicate more than they do right now but chiplets definitely need to, which is the point of the patent.
But if that is the case, what is the point of this patent? Using a faster interconnect? I do not recall if AMD has released something with fast interconnect but Nvidia's attempts with NVLink are not too encouraging, effectively leaving leading to the same issues as Crossfire/SLI always had.
Point of the patent ? I don't know, go ask their lawyers. Apple patented a rectangle with rounded edges so I don't think there is much point in wondering why something gets patented.
I would not be surprised if AMD's chiplet based GPUs also had cache coherency between the dies. Being able to ensure that data is in the caches closest to where it's needed across multiple dies is huge for a chiplet architecture. On top of that you also avoid duplicates in L1 / L2 caches across dies and CU groups.Not sure on stacking (as in vertically) in regards to high power dies. If the surface area of a vertically stacked die is smaller than a monolithic one, you are looking at more heat in a smaller area. The bottom die is basically insulated under the top die and does not get direct contact either. I feel like you need to make some serious design considerations for vertical stacking, much more so than AMD's chiplet based approach.
--
One of the last/bigger Nvidia papers on MCM GPU is from a couple years ago - research.nvidia.com/sites/default/files/publications/ISCA_2017_MCMGPU.pdf. The current rumor is that Hopper will be MCM.
Intel showed/leaked the MCM Xe HP pictures earlier this year.
AMD has been talking about MCM on and off since... R600 back in 2007? There is always hope that this gets a good working implementation.
Intel is going for MCM in HPC segment. Nvidia's Hopper details are scarce but entirely possible that it will be a compute-focused things (like Volta). AMD is the odd one out that doesn't have any specific enough rumors.
What has changed now is interconnects and more recently - packaging technologies. NVLink and IF have existed for a while. Now 2.5D packaging and things like EMIB are becoming "mainstream" enough to use. All that helps immensely with setting up the required communication.
MCM was specifically stated as a possible goal with R600 and small chips strategy. It didn't pan out too well (for any manufacturer so far).
Notably, before they've acquired Xilinx.You are essentially saying "we could have had chiplet based GPUs for ages", which... is not really true, I thought.
Perhaps things have changed with that "infinity cache" bit.
Thrilling if true.