Some Intel Nova Lake CPUs Rumored to Challenge AMD's 3D V-Cache in Desktop Gaming
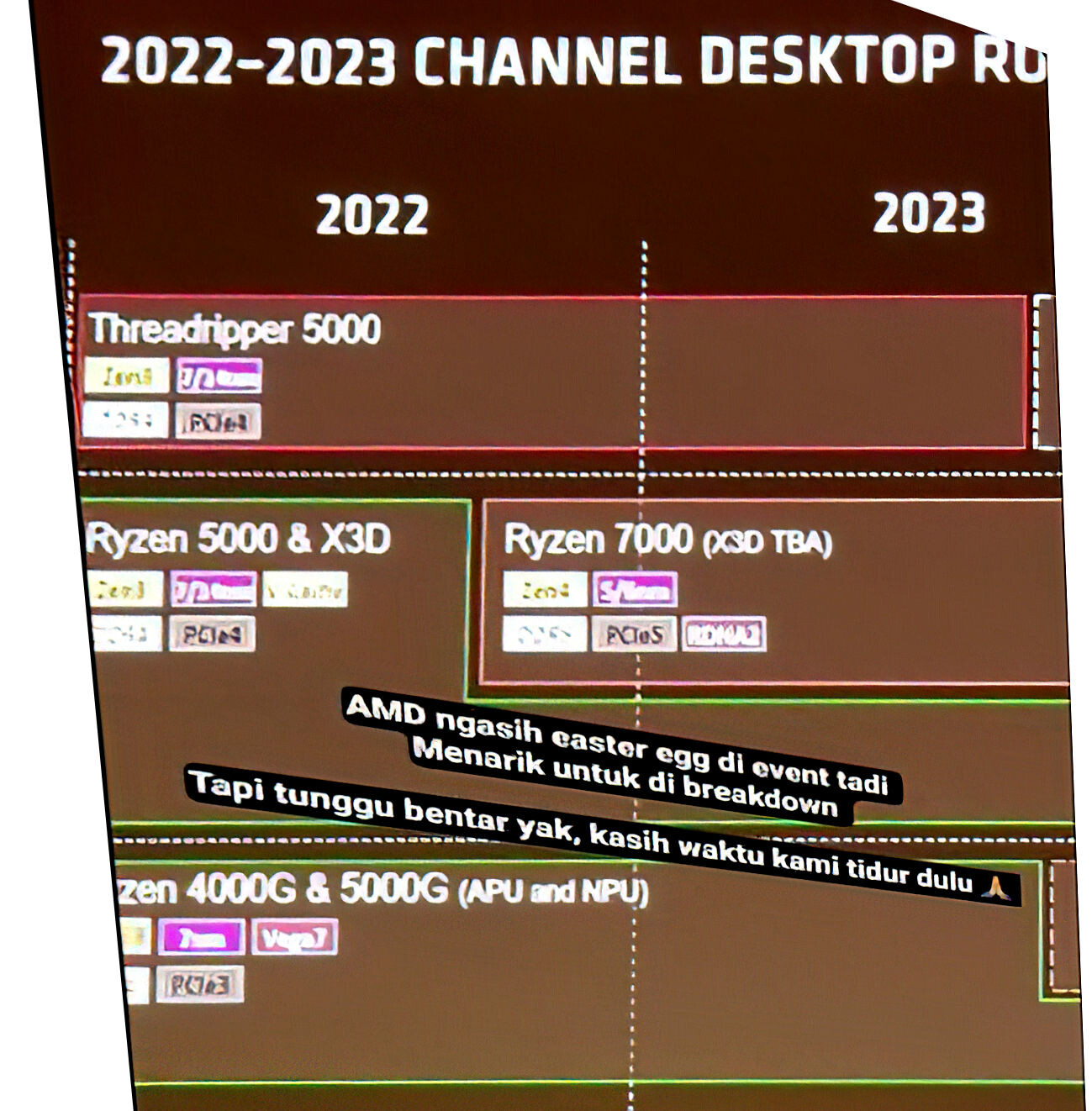
Looking to challenge AMD's gaming CPU supremacy, Intel is reportedly developing Nova Lake processors with enhanced cache technology that could rival the popular 3D V-Cache found in X3D chips. According to leaker @Haze2K1, Intel plans to add "bLLC" (big Last Line Cache) to at least two Nova Lake models. This improved L3 cache is similar to AMD's 3D V-Cache, which has made X3D chips the top pick for enthusiast gamers since 2022. The new processors with bLLC will have 8 P-cores and 4 LP-E-Cores. One version will include 20 E-cores, while another will have 12 E-cores. Both are expected to keep a 125 W TDP rating.
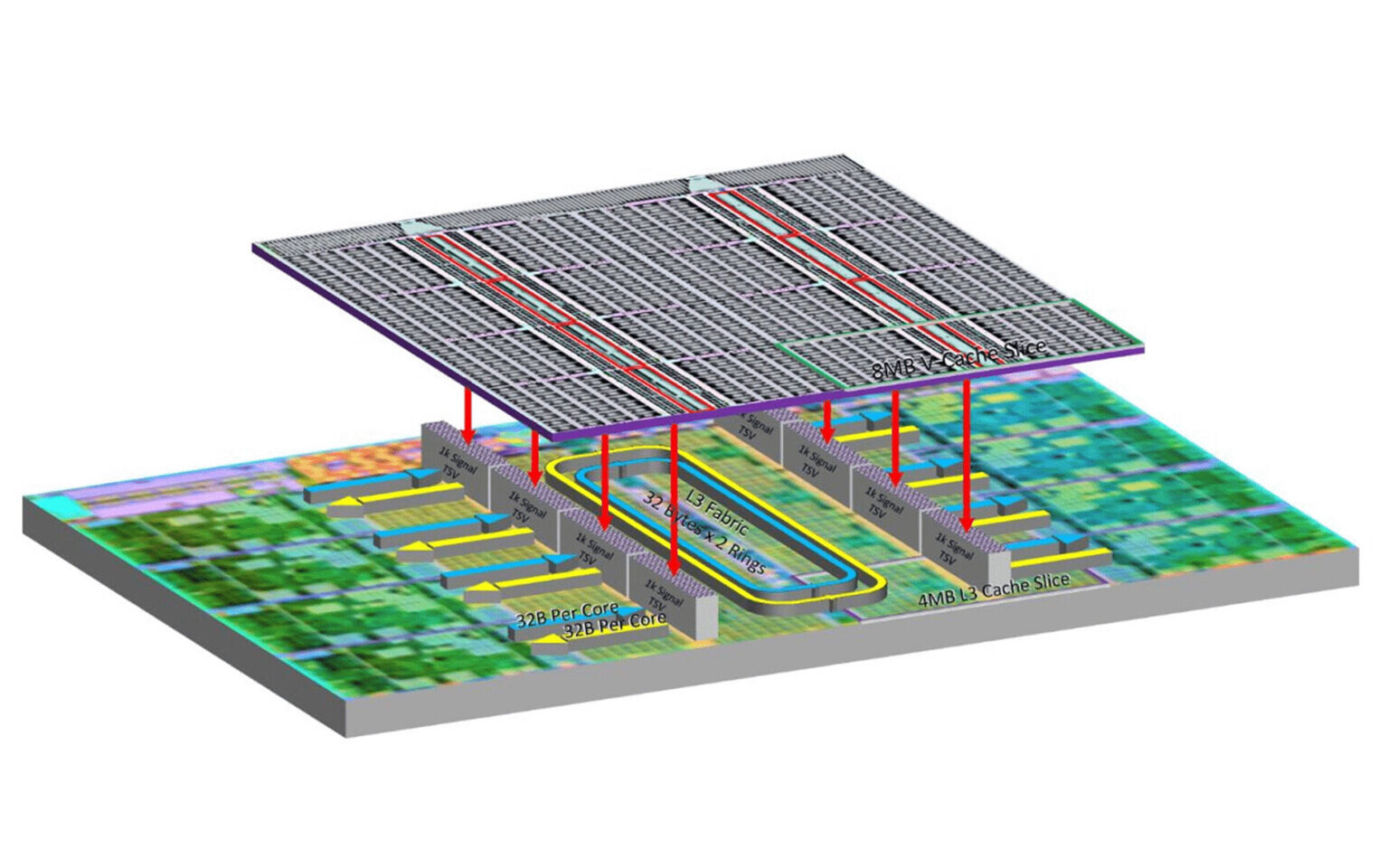
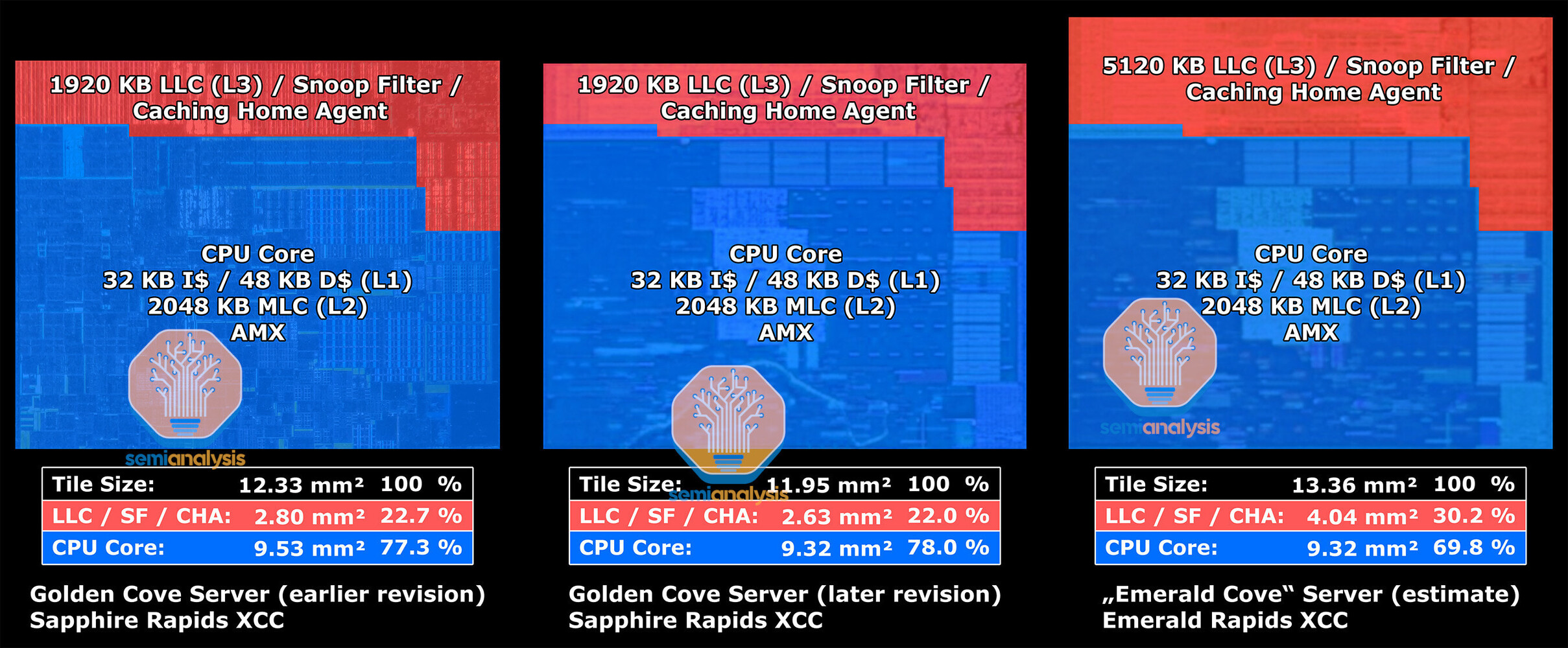
Intel's bLLC technology already exists in Clearwater Forest server processors where local cache integrates into the base tile positioned beneath active tiles. This structural approach mirrors AMD's current 9000-series X3D design, where V-Cache attaches to the bottom of CPU dies—a significant improvement over earlier generations that placed cache on top, causing thermal issues and clock speed limitations. Yet, Intel said no to consumer plans for a technology similar to AMD's 3D V-Cache. In November 2024, Intel's Tech Communications Manager Florian Maislinger told YouTubers der8auer and Bens Hardware that they didn't plan such a desktop version. The Nova Lake-S family is set to hit the market in late 2026 or early 2027, with at least six desktop models using new LGA 1954 packaging. The lineup will start from the top-end Core Ultra 9 485K with 52 cores and 150 W TDP and go down to the basic Core Ultra 3 415K offering 12 cores at 125 W TDP.

Intel's bLLC technology already exists in Clearwater Forest server processors where local cache integrates into the base tile positioned beneath active tiles. This structural approach mirrors AMD's current 9000-series X3D design, where V-Cache attaches to the bottom of CPU dies—a significant improvement over earlier generations that placed cache on top, causing thermal issues and clock speed limitations. Yet, Intel said no to consumer plans for a technology similar to AMD's 3D V-Cache. In November 2024, Intel's Tech Communications Manager Florian Maislinger told YouTubers der8auer and Bens Hardware that they didn't plan such a desktop version. The Nova Lake-S family is set to hit the market in late 2026 or early 2027, with at least six desktop models using new LGA 1954 packaging. The lineup will start from the top-end Core Ultra 9 485K with 52 cores and 150 W TDP and go down to the basic Core Ultra 3 415K offering 12 cores at 125 W TDP.