Wednesday, March 2nd 2022

NVIDIA Increases Caches for Ada Lovelace, to Catch Up with AMD
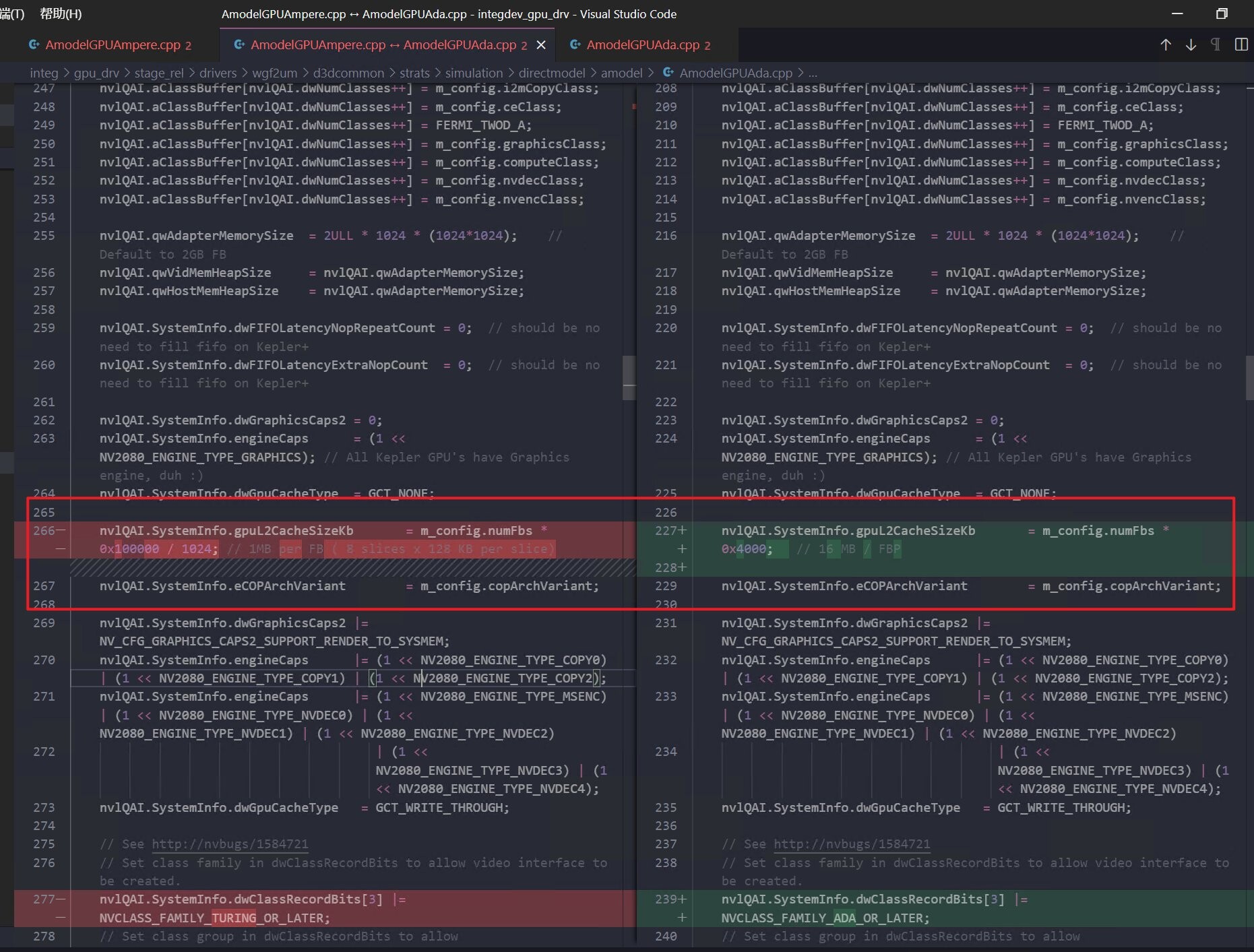
The next-generation "Ada Lovelace" graphics architecture powering NVIDIA's GeForce RTX 40-series graphics cards, could see a significant increase in on-die cache memory, according to leaked source-code related to drivers or firmware, seen by XinoAssassin on Twitter. The source-code leak emanates from the recent large-scale cyber-attack on NVIDIA. When comparing source files related to Ampere and Ada architectures, XinoAssassin noticed lines that reference large cache slices.
From this, it was analyzed that the top-of-the-line AD102 silicon will have 96 MB of last-level cache on the silicon; the AD103 and AD104 chips have 64 MB; the AD106 has 48 MB, and the smallest AD107 has 32 MB. Compare this to the 6 MB on the GA102, puny 4 MB on the GA103 and GA104; 3 MB on the GA106, and 2 MB on the GA107. NVIDIA is known to make innovations in generational memory bandwidth increase and memory management, with each new architecture. The company could tap into even faster versions of GDDR6X memory it co-developed with Micron (GDDR6 with PAM4 signaling). AMD credits its engineering choices with Infinity Cache (large on-die caches on RDNA2 GPUs) to play a key role in lubricating the memory sub-system. Since this is much cheaper than going for wider memory buses or using exotic HBM solutions; and since AMD gathered knowhow on 3D-stacked cache memory with its "Zen 3" CCDs that have 3D Vertical Caches; we expect the company to double down on Infinity Cache with RDNA3.
AMD credits its engineering choices with Infinity Cache (large on-die caches on RDNA2 GPUs) to play a key role in lubricating the memory sub-system. Since this is much cheaper than going for wider memory buses or using exotic HBM solutions; and since AMD gathered knowhow on 3D-stacked cache memory with its "Zen 3" CCDs that have 3D Vertical Caches; we expect the company to double down on Infinity Cache with RDNA3.
Sources:
XinoAssassin (Twitter), VideoCardz
From this, it was analyzed that the top-of-the-line AD102 silicon will have 96 MB of last-level cache on the silicon; the AD103 and AD104 chips have 64 MB; the AD106 has 48 MB, and the smallest AD107 has 32 MB. Compare this to the 6 MB on the GA102, puny 4 MB on the GA103 and GA104; 3 MB on the GA106, and 2 MB on the GA107. NVIDIA is known to make innovations in generational memory bandwidth increase and memory management, with each new architecture. The company could tap into even faster versions of GDDR6X memory it co-developed with Micron (GDDR6 with PAM4 signaling).
9 Comments on NVIDIA Increases Caches for Ada Lovelace, to Catch Up with AMD
That will mostly help reducing the need for large memory bus/high frequency memory and it will reduce the efficiency loss of high core frequency. Since each clock last shorter the higher the frequency, having to wait for the memory is increasingly costly. Cache help to reduce that by having the possibility to return the data way faster. Limiting the number of wasted clock cycle.
Looking at frametimes AMD clearly has a large advantage, the real question is do you notice it, some people seem to be more sensitive to it.