Ayar Labs Unveils World's First UCIe Optical Chiplet for AI Scale-Up Architectures
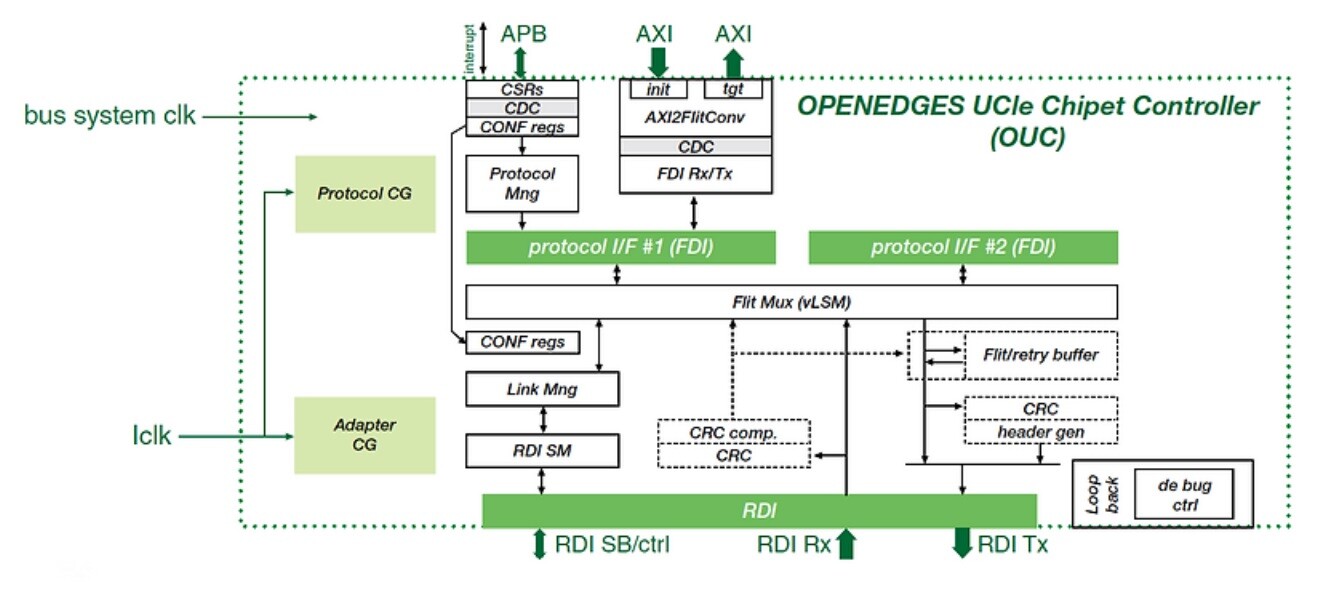
Ayar Labs, the leader in optical interconnect solutions for large-scale AI workloads, today announced the industry's first Universal Chiplet Interconnect Express (UCIe) optical interconnect chiplet to maximize AI infrastructure performance and efficiency while reducing latency and power consumption. By incorporating a UCIe electrical interface, this solution is designed to eliminate data bottlenecks and integrate easily into customer chip designs.
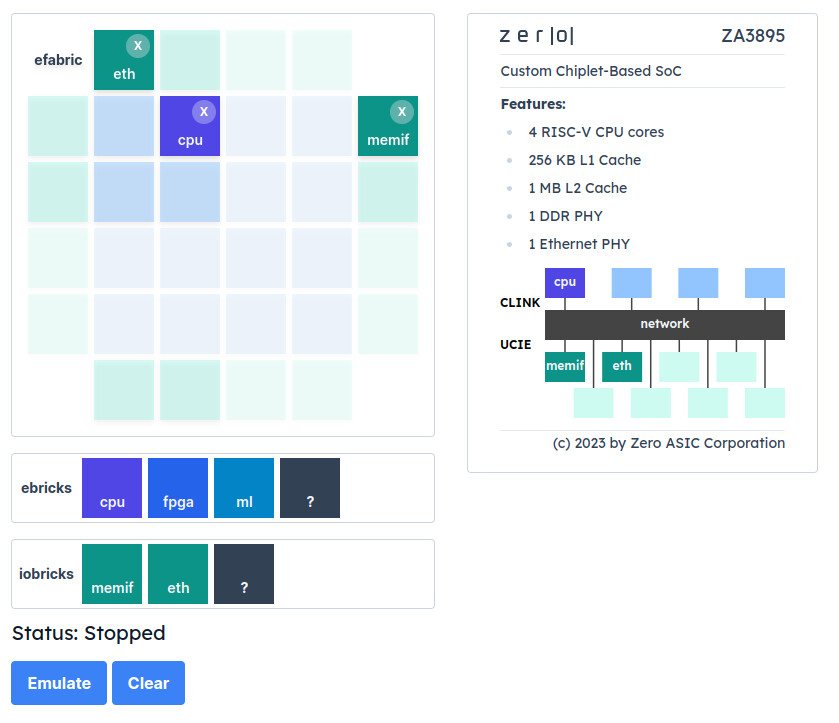
Capable of achieving 8 Tbps bandwidth, the TeraPHY optical I/O chiplet is powered by Ayar Labs' 16-wavelength SuperNova light source. The integration of a UCIe interface means this solution not only delivers high performance and efficiency but also enables interoperability among chiplets from different vendors. This compatibility with the UCIe standard creates a more accessible, cost-effective ecosystem, which streamlines the adoption of advanced optical technologies necessary for scaling AI workloads and overcoming the limitations of traditional copper interconnects.
Capable of achieving 8 Tbps bandwidth, the TeraPHY optical I/O chiplet is powered by Ayar Labs' 16-wavelength SuperNova light source. The integration of a UCIe interface means this solution not only delivers high performance and efficiency but also enables interoperability among chiplets from different vendors. This compatibility with the UCIe standard creates a more accessible, cost-effective ecosystem, which streamlines the adoption of advanced optical technologies necessary for scaling AI workloads and overcoming the limitations of traditional copper interconnects.