Winbond Joins UCIe Consortium to Support High-performance Chiplet Interface Standardisation
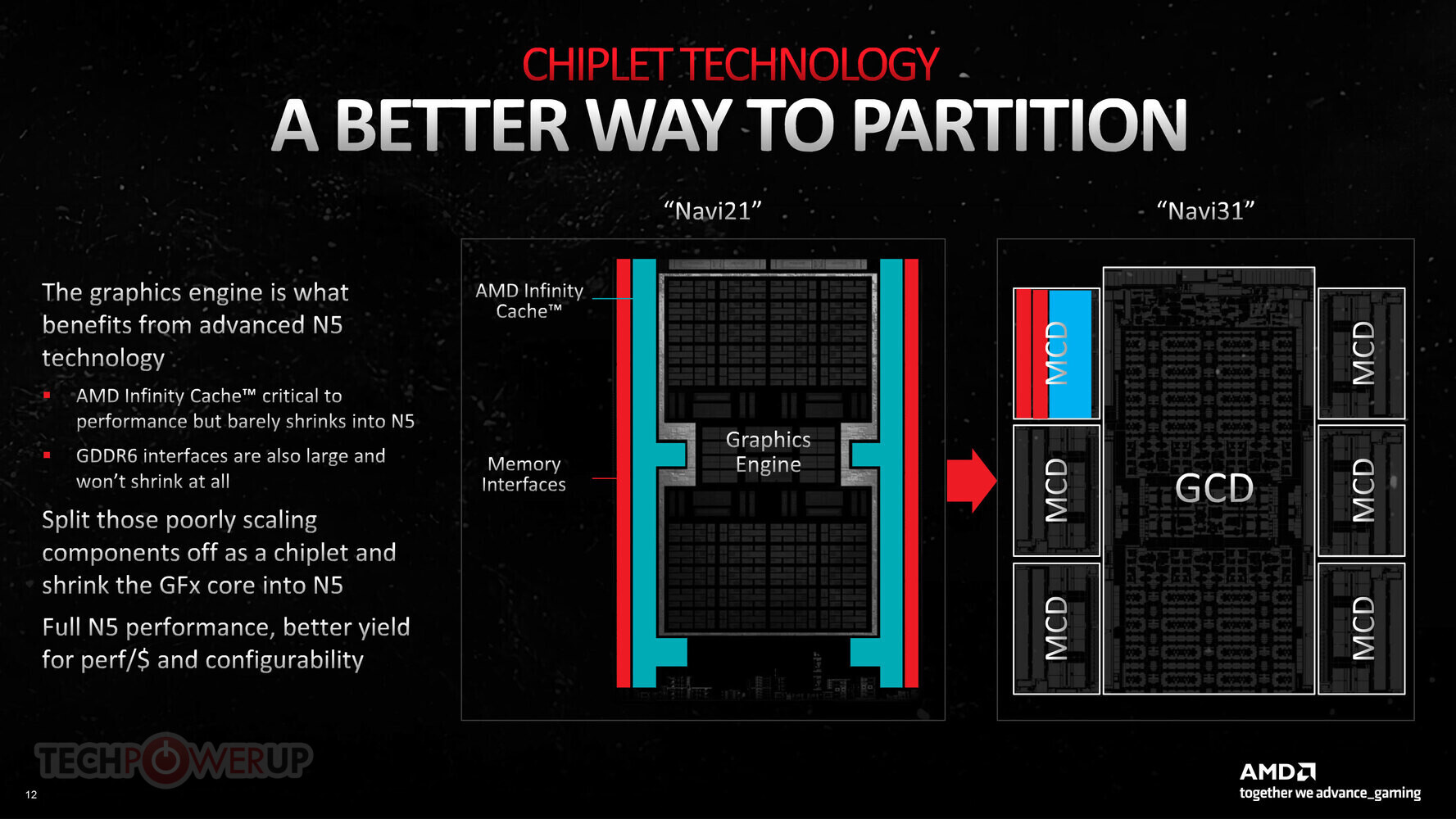
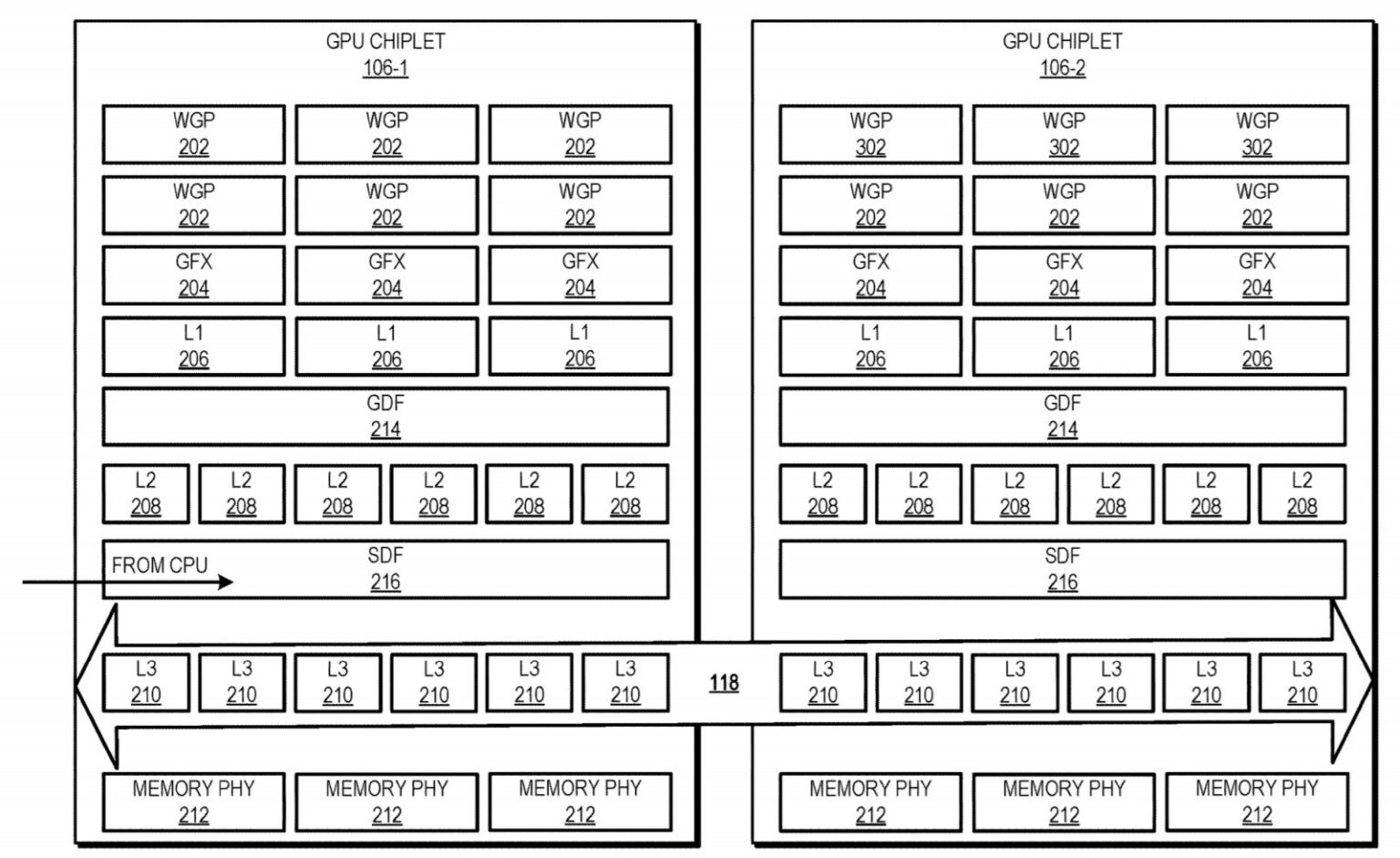
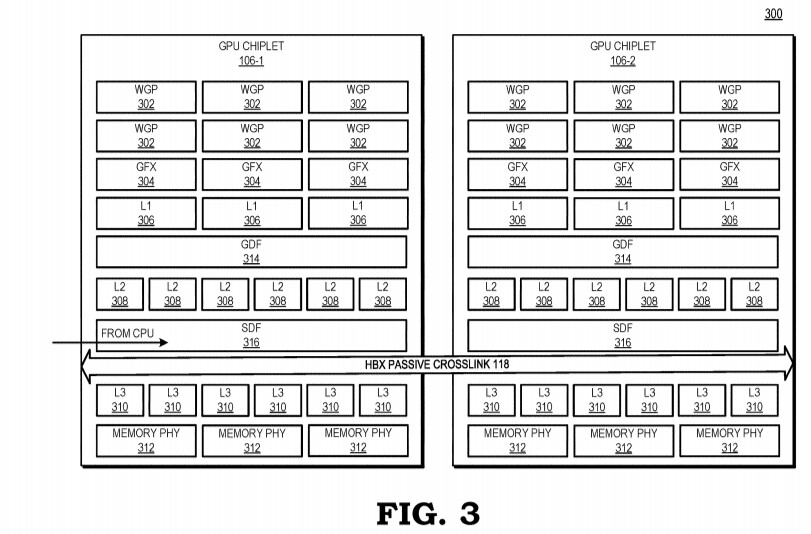
Winbond has joined the UCIe (Universal Chiplet Interconnect Express) Consortium, the industry Consortium dedicated to advancing UCIe technology. This open industry standard defines interconnect between chiplets within a package, enabling an open chiplet ecosystem and facilitating the development of advanced 2.5D/3D devices.
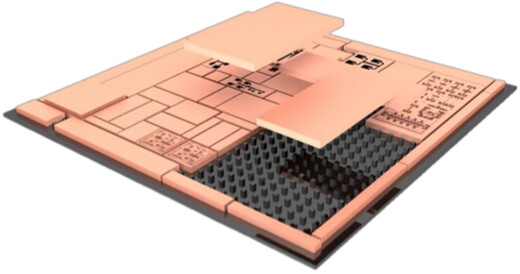
A leader in high-performance memory ICs, Winbond is an established supplier of known good die (KGD) needed to assure end-of-line yield in 2.5D/3D assembly. 2.5D/3D multichip devices are needed to realize the exponential improvements in performance, power efficiency, and miniaturization, demanded by the explosion of technologies such as 5G, Automotive, and Artificial Intelligence (AI).
A leader in high-performance memory ICs, Winbond is an established supplier of known good die (KGD) needed to assure end-of-line yield in 2.5D/3D assembly. 2.5D/3D multichip devices are needed to realize the exponential improvements in performance, power efficiency, and miniaturization, demanded by the explosion of technologies such as 5G, Automotive, and Artificial Intelligence (AI).