Huawei CloudMatrix 384 System Outperforms NVIDIA GB200 NVL72
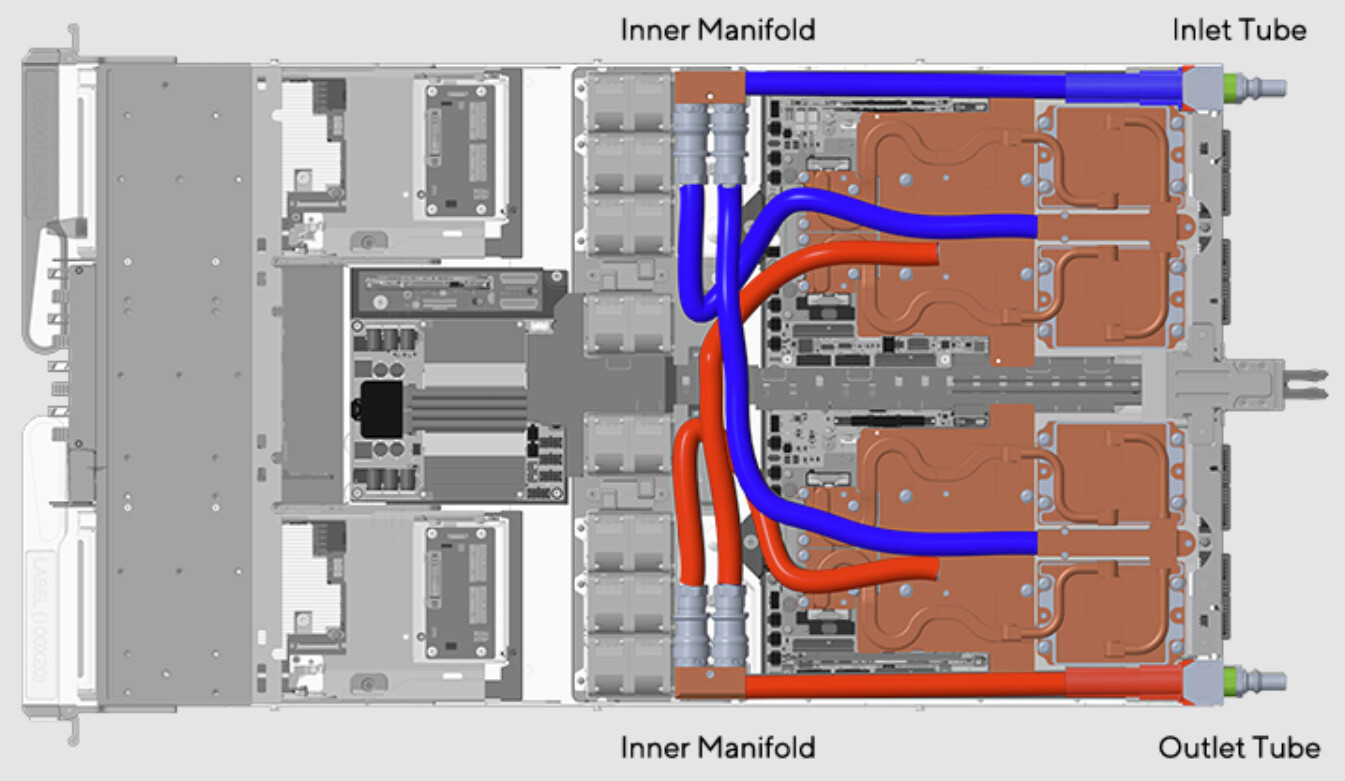
Huawei announced its CloudMatrix 384 system super node, which the company touts as its own domestic alternative to NVIDIA's GB200 NVL72 system, with more overall system performance but worse per-chip performance and higher power consumption. While NVIDIA's GB200 NVL72 uses 36 Grace CPUs paired with 72 "Blackwell" GB200 GPUs, the Huawei CloudMatrix 384 system employs 384 Huawei Ascend 910C accelerators to beat NVIDIA's GB200 NVL72 system. It takes roughly five times more Ascend 910C accelerators to deliver nearly twice the GB200 NVL system performance, which is not good on per-accelerator bias, but excellent on per-system level of deployment. SemiAnalysis argues that Huawei is a generation behind in chip performance but ahead of NVIDIA in scale-up system design and deployment.
When you look at individual chips, NVIDIA's GB200 NVL72 clearly outshines Huawei's Ascend 910C, delivering over three times the BF16 performance (2,500 TeraFLOPS vs. 780 TeraFLOPS), more on‑chip memory (192 GB vs. 128 GB), and faster bandwidth (8 TB/s vs. 3.2 TB/s). In other words, NVIDIA has the raw power and efficiency advantage at the chip level. But flip the switch to the system level, and Huawei's CloudMatrix CM384 takes the lead. It cranks out 1.7× the overall PetaFLOPS, packs in 3.6× more total HBM capacity, and supports over five times the number of GPUs and the associated bandwidth of NVIDIA's NVL72 cluster. However, that scalability does come with a trade‑off, as Huawei's setup draws nearly four times more total power. A single GB200 NVL72 draws 145 kW of power, while a single Huawei CloudMatrix 384 draws ~560 kW. So, NVIDIA is your go-to if you need peak efficiency in a single GPU. If you're building a massive AI supercluster where total throughput and interconnect speed matter most, Huawei's solution actually makes a lot of sense. Thanks to its all-to-all topology, Huawei has delivered an AI training and inference system worth purchasing. When SMIC, the maker of Huawei's chips, gets to a more advanced manufacturing node, the efficiency of these systems will also increase.

When you look at individual chips, NVIDIA's GB200 NVL72 clearly outshines Huawei's Ascend 910C, delivering over three times the BF16 performance (2,500 TeraFLOPS vs. 780 TeraFLOPS), more on‑chip memory (192 GB vs. 128 GB), and faster bandwidth (8 TB/s vs. 3.2 TB/s). In other words, NVIDIA has the raw power and efficiency advantage at the chip level. But flip the switch to the system level, and Huawei's CloudMatrix CM384 takes the lead. It cranks out 1.7× the overall PetaFLOPS, packs in 3.6× more total HBM capacity, and supports over five times the number of GPUs and the associated bandwidth of NVIDIA's NVL72 cluster. However, that scalability does come with a trade‑off, as Huawei's setup draws nearly four times more total power. A single GB200 NVL72 draws 145 kW of power, while a single Huawei CloudMatrix 384 draws ~560 kW. So, NVIDIA is your go-to if you need peak efficiency in a single GPU. If you're building a massive AI supercluster where total throughput and interconnect speed matter most, Huawei's solution actually makes a lot of sense. Thanks to its all-to-all topology, Huawei has delivered an AI training and inference system worth purchasing. When SMIC, the maker of Huawei's chips, gets to a more advanced manufacturing node, the efficiency of these systems will also increase.