Mar 29th, 2025 07:52 EDT
change timezone
Latest GPU Drivers
New Forum Posts
- Upgrade from a AMD AM3+ to AM4 or AM5 chipset MB running W10? (17)
- Future-proofing my OLED (57)
- Windows 10 Vs 11, Which one too choose? (118)
- What are you playing? (23306)
- RTX 5080 - performance fluctuation (6)
- Did Nvidia purposely gimp the performance of 50xx series cards with drivers (114)
- AMD RX 9070 XT & RX 9070 non-XT thread (OC, undervolt, benchmarks, ...) (71)
- TPU's F@H Team (20414)
- Have you got pie today? (16650)
- Which thermal paste never pumps out? (67)
Popular Reviews
- Sapphire Radeon RX 9070 XT Pulse Review
- Samsung 9100 Pro 2 TB Review - The Best Gen 5 SSD
- ASRock Phantom Gaming B850 Riptide Wi-Fi Review - Amazing Price/Performance
- Assassin's Creed Shadows Performance Benchmark Review - 30 GPUs Compared
- be quiet! Pure Rock Pro 3 Black Review
- Sapphire Radeon RX 9070 XT Nitro+ Review - Beating NVIDIA
- ASRock Radeon RX 9070 XT Taichi OC Review - Excellent Cooling
- Palit GeForce RTX 5070 GamingPro OC Review
- Pulsar Feinmann F01 Review
- AMD Ryzen 7 9800X3D Review - The Best Gaming Processor
Controversial News Posts
- AMD RDNA 4 and Radeon RX 9070 Series Unveiled: $549 & $599 (260)
- MSI Doesn't Plan Radeon RX 9000 Series GPUs, Skips AMD RDNA 4 Generation Entirely (142)
- Microsoft Introduces Copilot for Gaming (123)
- AMD Radeon RX 9070 XT Reportedly Outperforms RTX 5080 Through Undervolting (118)
- NVIDIA Reportedly Prepares GeForce RTX 5060 and RTX 5060 Ti Unveil Tomorrow (115)
- Over 200,000 Sold Radeon RX 9070 and RX 9070 XT GPUs? AMD Says No Number was Given (100)
- NVIDIA GeForce RTX 5050, RTX 5060, and RTX 5060 Ti Specifications Leak (96)
- Retailers Anticipate Increased Radeon RX 9070 Series Prices, After Initial Shipments of "MSRP" Models (90)
News Posts matching #GB200
Return to Keyword Browsing
Micron SSDs Qualified for Recommended Vendor List on NVIDIA GB200 NVL72
Micron Technology, Inc., today announced that its 9550 PCIe Gen 5 E1.S data center SSDs have been added to the NVIDIA recommended vendor list (RVL) for the NVIDIA GB200 NVL72 system and its derivatives. The GB200 NVL72 uses the GB200 Grace Blackwell Superchip to deliver rack-scale, energy-efficient AI infrastructure. The enablement of PCIe Gen 5 storage in the system makes the Micron 9550 SSD an ideal fit for optimizing performance and power efficiency in AI workloads like large-scale training of AI models, real-time trillion-parameter language model inference and high-performance computing (HPC) tasks.
Micron 9550 delivers world-class AI workload performance and power efficiency:
Compared with other industry offerings, the 9550 SSD delivers up to 34% higher throughput for NVIDIA Magnum IO GPUDirect (GDS) and up to 33% faster workload completion times in graph neural network (GNN) training with Big Accelerator Memory (BaM). The Micron 9550 SSD saves energy and sets new sustainability benchmarks by consuming 81% less SSD energy per 1 TB transferred than other SSD offerings with NVIDIA Magnum IO GDS and up to 43% lower SSD power in GNN training with BaM.

Micron 9550 delivers world-class AI workload performance and power efficiency:
Compared with other industry offerings, the 9550 SSD delivers up to 34% higher throughput for NVIDIA Magnum IO GPUDirect (GDS) and up to 33% faster workload completion times in graph neural network (GNN) training with Big Accelerator Memory (BaM). The Micron 9550 SSD saves energy and sets new sustainability benchmarks by consuming 81% less SSD energy per 1 TB transferred than other SSD offerings with NVIDIA Magnum IO GDS and up to 43% lower SSD power in GNN training with BaM.


Meta Shows Open-Architecture NVIDIA "Blackwell" GB200 System for Data Center
During the Open Compute Project (OCP) Summit 2024, Meta, one of the prime members of the OCP project, showed its NVIDIA "Blackwell" GB200 systems for its massive data centers. We previously covered Microsoft's Azure server rack with GB200 GPUs featuring one-third of the rack space for computing and two-thirds for cooling. A few days later, Google showed off its smaller GB200 system, and today, Meta is showing off its GB200 system—the smallest of the bunch. To train a dense transformer large language model with 405B parameters and a context window of up to 128k tokens, like the Llama 3.1 405B, Meta must redesign its data center infrastructure to run a distributed training job on two 24,000 GPU clusters. That is 48,000 GPUs used for training a single AI model.
Called "Catalina," it is built on the NVIDIA Blackwell platform, emphasizing modularity and adaptability while incorporating the latest NVIDIA GB200 Grace Blackwell Superchip. To address the escalating power requirements of GPUs, Catalina introduces the Orv3, a high-power rack capable of delivering up to 140kW. The comprehensive liquid-cooled setup encompasses a power shelf supporting various components, including a compute tray, switch tray, the Orv3 HPR, Wedge 400 fabric switch with 12.8 Tbps switching capacity, management switch, battery backup, and a rack management controller. Interestingly, Meta also upgraded its "Grand Teton" system for internal usage, such as deep learning recommendation models (DLRMs) and content understanding with AMD Instinct MI300X. Those are used to inference internal models, and MI300X appears to provide the best performance per Dollar for inference. According to Meta, the computational demand stemming from AI will continue to increase exponentially, so more NVIDIA and AMD GPUs is needed, and we can't wait to see what the company builds.

Called "Catalina," it is built on the NVIDIA Blackwell platform, emphasizing modularity and adaptability while incorporating the latest NVIDIA GB200 Grace Blackwell Superchip. To address the escalating power requirements of GPUs, Catalina introduces the Orv3, a high-power rack capable of delivering up to 140kW. The comprehensive liquid-cooled setup encompasses a power shelf supporting various components, including a compute tray, switch tray, the Orv3 HPR, Wedge 400 fabric switch with 12.8 Tbps switching capacity, management switch, battery backup, and a rack management controller. Interestingly, Meta also upgraded its "Grand Teton" system for internal usage, such as deep learning recommendation models (DLRMs) and content understanding with AMD Instinct MI300X. Those are used to inference internal models, and MI300X appears to provide the best performance per Dollar for inference. According to Meta, the computational demand stemming from AI will continue to increase exponentially, so more NVIDIA and AMD GPUs is needed, and we can't wait to see what the company builds.



SK hynix Showcases Memory Solutions at the 2024 OCP Global Summit
SK hynix is showcasing its leading AI and data center memory products at the 2024 Open Compute Project (OCP) Global Summit held October 15-17 in San Jose, California. The annual summit brings together industry leaders to discuss advancements in open source hardware and data center technologies. This year, the event's theme is "From Ideas to Impact," which aims to foster the realization of theoretical concepts into real-world technologies.
In addition to presenting its advanced memory products at the summit, SK hynix is also strengthening key industry partnerships and sharing its AI memory expertise through insightful presentations. This year, the company is holding eight sessions—up from five in 2023—on topics including HBM and CMS.



In addition to presenting its advanced memory products at the summit, SK hynix is also strengthening key industry partnerships and sharing its AI memory expertise through insightful presentations. This year, the company is holding eight sessions—up from five in 2023—on topics including HBM and CMS.





MSI Unveils AI Servers Powered by NVIDIA MGX at OCP 2024
MSI, a leading global provider of high-performance server solutions, proudly announced it is showcasing new AI servers powered by the NVIDIA MGX platform—designed to address the increasing demand for scalable, energy-efficient AI workloads in modern data centers—at the OCP Global Summit 2024, booth A6. This collaboration highlights MSI's continued commitment to advancing server solutions, focusing on cutting-edge AI acceleration and high-performance computing (HPC).
The NVIDIA MGX platform offers a flexible architecture that enables MSI to deliver purpose-built solutions optimized for AI, HPC, and LLMs. By leveraging this platform, MSI's AI server solutions provide exceptional scalability, efficiency, and enhanced GPU density—key factors in meeting the growing computational demands of AI workloads. Tapping into MSI's engineering expertise and NVIDIA's advanced AI technologies, these AI servers based on the MGX architecture deliver unparalleled compute power, positioning data centers to maximize performance and power efficiency while paving the way for the future of AI-driven infrastructure.
The NVIDIA MGX platform offers a flexible architecture that enables MSI to deliver purpose-built solutions optimized for AI, HPC, and LLMs. By leveraging this platform, MSI's AI server solutions provide exceptional scalability, efficiency, and enhanced GPU density—key factors in meeting the growing computational demands of AI workloads. Tapping into MSI's engineering expertise and NVIDIA's advanced AI technologies, these AI servers based on the MGX architecture deliver unparalleled compute power, positioning data centers to maximize performance and power efficiency while paving the way for the future of AI-driven infrastructure.


Lenovo Announces New Liquid Cooled Servers for Intel Xeon and NVIDIA Blackwell Platforms
At Lenovo Tech World 2024, we announced new Supercomputing servers for HPC and AI workloads. These new water-cooled servers use the latest processor and accelerator technology from Intel and NVIDIA.
ThinkSystem SC750 V4
Engineered for large-scale cloud infrastructures and High Performance Computing (HPC), the Lenovo ThinkSystem SC750 V4 Neptune excels in intensive simulations and complex modeling. It's designed to handle technical computing, grid deployments, and analytics workloads in various fields such as research, life sciences, energy, engineering, and financial simulation.


ThinkSystem SC750 V4
Engineered for large-scale cloud infrastructures and High Performance Computing (HPC), the Lenovo ThinkSystem SC750 V4 Neptune excels in intensive simulations and complex modeling. It's designed to handle technical computing, grid deployments, and analytics workloads in various fields such as research, life sciences, energy, engineering, and financial simulation.




Google Shows Production NVIDIA "Blackwell" GB200 NVL System for Cloud
Last week, we got a preview of Microsoft's Azure production-ready NVIDIA "Blackwell" GB200 system, showing that only a third of the rack that goes in the data center is actually holding the compute elements, with the other two-thirds holding the cooling compartment to cool down the immense heat output from tens of GB200 GPUs. Today, Google is showing off a part of its own infrastructure ahead of the Google Cloud App Dev & Infrastructure Summit, taking place on October 30, digitally as an event. Shown below are two racks standing side by side, connecting NVIDIA "Blackwell" GB200 NVL cards with the rest of the Google infrastructure. Unlike Microsoft Azure, Google Cloud uses a different data center design in its facilities.
There is one rack with power distribution units, networking switches, and cooling distribution units, all connected to the compute rack, which houses power supplies, GPUs, and CPU servers. Networking equipment is present, and it connects to Google's "global" data center network, which is Google's own data center fabric. We are not sure what is the fabric connection of choice between these racks; as for optimal performance, NVIDIA recommends InfiniBand (Mellanox acquisition). However, given that Google's infrastructure is set up differently, there may be Ethernet switches present. Interestingly, Google's design of GB200 racks differs from Azure's, as it uses additional rack space to distribute the coolant to its local heat exchangers, i.e., coolers. We are curious to see if Google releases more information on infrastructure, as it has been known as the infrastructure king because of its ability to scale and keep everything organized.
There is one rack with power distribution units, networking switches, and cooling distribution units, all connected to the compute rack, which houses power supplies, GPUs, and CPU servers. Networking equipment is present, and it connects to Google's "global" data center network, which is Google's own data center fabric. We are not sure what is the fabric connection of choice between these racks; as for optimal performance, NVIDIA recommends InfiniBand (Mellanox acquisition). However, given that Google's infrastructure is set up differently, there may be Ethernet switches present. Interestingly, Google's design of GB200 racks differs from Azure's, as it uses additional rack space to distribute the coolant to its local heat exchangers, i.e., coolers. We are curious to see if Google releases more information on infrastructure, as it has been known as the infrastructure king because of its ability to scale and keep everything organized.

Supermicro's Liquid-Cooled SuperClusters for AI Data Centers Powered by NVIDIA GB200 NVL72 and NVIDIA HGX B200 Systems
Supermicro, Inc., a Total IT Solution Provider for AI, Cloud, Storage, and 5G/Edge, is accelerating the industry's transition to liquid-cooled data centers with the NVIDIA Blackwell platform to deliver a new paradigm of energy-efficiency for the rapidly heightened energy demand of new AI infrastructures. Supermicro's industry-leading end-to-end liquid-cooling solutions are powered by the NVIDIA GB200 NVL72 platform for exascale computing in a single rack and have started sampling to select customers for full-scale production in late Q4. In addition, the recently announced Supermicro X14 and H14 4U liquid-cooled systems and 10U air-cooled systems are production-ready for the NVIDIA HGX B200 8-GPU system.
"We're driving the future of sustainable AI computing, and our liquid-cooled AI solutions are rapidly being adopted by some of the most ambitious AI Infrastructure projects in the world with over 2000 liquid-cooled racks shipped since June 2024," said Charles Liang, president and CEO of Supermicro. "Supermicro's end-to-end liquid-cooling solution, with the NVIDIA Blackwell platform, unlocks the computational power, cost-effectiveness, and energy-efficiency of the next generation of GPUs, such as those that are part of the NVIDIA GB200 NVL72, an exascale computer contained in a single rack. Supermicro's extensive experience in deploying liquid-cooled AI infrastructure, along with comprehensive on-site services, management software, and global manufacturing capacity, provides customers a distinct advantage in transforming data centers with the most powerful and sustainable AI solutions."
"We're driving the future of sustainable AI computing, and our liquid-cooled AI solutions are rapidly being adopted by some of the most ambitious AI Infrastructure projects in the world with over 2000 liquid-cooled racks shipped since June 2024," said Charles Liang, president and CEO of Supermicro. "Supermicro's end-to-end liquid-cooling solution, with the NVIDIA Blackwell platform, unlocks the computational power, cost-effectiveness, and energy-efficiency of the next generation of GPUs, such as those that are part of the NVIDIA GB200 NVL72, an exascale computer contained in a single rack. Supermicro's extensive experience in deploying liquid-cooled AI infrastructure, along with comprehensive on-site services, management software, and global manufacturing capacity, provides customers a distinct advantage in transforming data centers with the most powerful and sustainable AI solutions."


NVIDIA Contributes Blackwell Platform Design to Open Hardware Ecosystem, Accelerating AI Infrastructure Innovation
To drive the development of open, efficient and scalable data center technologies, NVIDIA today announced that it has contributed foundational elements of its NVIDIA Blackwell accelerated computing platform design to the Open Compute Project (OCP) and broadened NVIDIA Spectrum-X support for OCP standards.
At this year's OCP Global Summit, NVIDIA will be sharing key portions of the NVIDIA GB200 NVL72 system electro-mechanical design with the OCP community — including the rack architecture, compute and switch tray mechanicals, liquid-cooling and thermal environment specifications, and NVIDIA NVLink cable cartridge volumetrics — to support higher compute density and networking bandwidth.
At this year's OCP Global Summit, NVIDIA will be sharing key portions of the NVIDIA GB200 NVL72 system electro-mechanical design with the OCP community — including the rack architecture, compute and switch tray mechanicals, liquid-cooling and thermal environment specifications, and NVIDIA NVLink cable cartridge volumetrics — to support higher compute density and networking bandwidth.


Western Digital Enterprise SSDs Certified to Support NVIDIA GB200 NVL72 System for Compute-Intensive AI Environments
Western Digital Corp. today announced that its PCIe Gen 5 DC SN861 E.1S enterprise-class NVMe SSDs have been certified to support the NVIDIA GB200 NVL72 rack-scale system.
The rapid rise of AI, ML, and large language models (LLMs) is creating a challenge for companies with two opposing forces. Data generation and consumption are accelerating, while organizations face pressure to quickly derive value from this data. Performance, scalability, and efficiency are essential for AI technology stacks as storage demands rise. Certified to be compatible with the GB200 NVL72 system, Western Digital's enterprise SSD addresses the growing needs of the AI market for high-speed accelerated computing combined with low latency to serve compute-intensive AI environments.

The rapid rise of AI, ML, and large language models (LLMs) is creating a challenge for companies with two opposing forces. Data generation and consumption are accelerating, while organizations face pressure to quickly derive value from this data. Performance, scalability, and efficiency are essential for AI technology stacks as storage demands rise. Certified to be compatible with the GB200 NVL72 system, Western Digital's enterprise SSD addresses the growing needs of the AI market for high-speed accelerated computing combined with low latency to serve compute-intensive AI environments.


NVIDIA "Blackwell" GPUs are Sold Out for 12 Months, Customers Ordering in 100K GPU Quantities
NVIDIA's "Blackwell" series of GPUs, including B100, B200, and GB200, are reportedly sold out for 12 months or an entire year. This directly means that if a new customer is willing to order a new Blackwell GPU now, there is a 12-month waitlist to get that GPU. Analyst from Morgan Stanley Joe Moore confirmed that in a meeting with NVIDIA and its investors, NVIDIA executives confirmed that the demand for "Blackwell" is so great that there is a 12-month backlog to fulfill first before shipping to anyone else. We expect that this includes customers like Amazon, META, Microsoft, Google, Oracle, and others, who are ordering GPUs in insane quantities to keep up with the demand from their customers.
The previous generation of "Hopper" GPUs was ordered in 10s of thousands of GPUs, while this "Blackwell" generation was ordered in 100s of thousands of GPUs simultaneously. For NVIDIA, that is excellent news, as that demand is expected to continue. The only one standing in the way of customers is TSMC, which manufactures these GPUs as fast as possible to meet demand. NVIDIA is one of TSMC's largest customers, so wafer allocation at TSMC's facilities is only expected to grow. We are now officially in the era of the million-GPU data centers, and we can only question at what point this massive growth stops or if it will stop at all in the near future.
The previous generation of "Hopper" GPUs was ordered in 10s of thousands of GPUs, while this "Blackwell" generation was ordered in 100s of thousands of GPUs simultaneously. For NVIDIA, that is excellent news, as that demand is expected to continue. The only one standing in the way of customers is TSMC, which manufactures these GPUs as fast as possible to meet demand. NVIDIA is one of TSMC's largest customers, so wafer allocation at TSMC's facilities is only expected to grow. We are now officially in the era of the million-GPU data centers, and we can only question at what point this massive growth stops or if it will stop at all in the near future.

NVIDIA Might Consider Major Design Shift for Future 300 GPU Series
NVIDIA is reportedly considering a significant design change for its GPU products, shifting from the current on-board solution to an independent GPU socket design following the GB200 shipment in Q4, according to reports from MoneyDJ and the Economic Daily News quoted by TrendForce. This move is not new in the industry, AMD has already introduced socket design in 2023 with their MI300A series via Supermicro dedicated servers. The B300 series, expected to become NVIDIA's mainstream product in the second half of 2025, is rumored to be the main beneficiary of this design change that could improve yield rates, though it may come with some performance trade-offs.
According to the Economic Daily News, the socket design will simplify after-sales service and server board maintenance, allowing users to replace or upgrade the GPUs quickly. The report also pointed out that based on the slot design, boards will contain up to four NVIDIA GPUs and a CPU, with each GPU having its dedicated slot. This will bring benefits for Taiwanese manufacturers like Foxconn and LOTES, who will supply different components and connectors. The move seems logical since with the current on-board design, once a GPU becomes faulty, the entire motherboard needs to be replaced, leading to significant downtime and high operational and maintenance costs.
According to the Economic Daily News, the socket design will simplify after-sales service and server board maintenance, allowing users to replace or upgrade the GPUs quickly. The report also pointed out that based on the slot design, boards will contain up to four NVIDIA GPUs and a CPU, with each GPU having its dedicated slot. This will bring benefits for Taiwanese manufacturers like Foxconn and LOTES, who will supply different components and connectors. The move seems logical since with the current on-board design, once a GPU becomes faulty, the entire motherboard needs to be replaced, leading to significant downtime and high operational and maintenance costs.

NVIDIA "Blackwell" GB200 Server Dedicates Two-Thirds of Space to Cooling at Microsoft Azure
Late Tuesday, Microsoft Azure shared an interesting picture on its social media platform X, showcasing the pinnacle of GPU-accelerated servers—NVIDIA "Blackwell" GB200-powered AI systems. Microsoft is one of NVIDIA's largest customers, and the company often receives products first to integrate into its cloud and company infrastructure. Even NVIDIA listens to feedback from companies like Microsoft about designing future products, especially those like the now-canceled NVL36x2 system. The picture below shows a massive cluster that roughly divides the compute area into a single-third of the entire system, with a gigantic two-thirds of the system dedicated to closed-loop liquid cooling.
The entire system is connected using Infiniband networking, a standard for GPU-accelerated systems due to its lower latency in packet transfer. While the details of the system are scarce, we can see that the integrated closed-loop liquid cooling allows the GPU racks to be in a 1U form for increased density. Given that these systems will go into the wider Microsoft Azure data centers, a system needs to be easily maintained and cooled. There are indeed limits in power and heat output that Microsoft's data centers can handle, so these types of systems often fit inside internal specifications that Microsoft designs. There are more compute-dense systems, of course, like NVIDIA's NVL72, but hyperscalers should usually opt for other custom solutions that fit into their data center specifications. Finally, Microsoft noted that we can expect to see more details at the upcoming Microsoft Ignite conference in November and learn more about its GB200-powered AI systems.
The entire system is connected using Infiniband networking, a standard for GPU-accelerated systems due to its lower latency in packet transfer. While the details of the system are scarce, we can see that the integrated closed-loop liquid cooling allows the GPU racks to be in a 1U form for increased density. Given that these systems will go into the wider Microsoft Azure data centers, a system needs to be easily maintained and cooled. There are indeed limits in power and heat output that Microsoft's data centers can handle, so these types of systems often fit inside internal specifications that Microsoft designs. There are more compute-dense systems, of course, like NVIDIA's NVL72, but hyperscalers should usually opt for other custom solutions that fit into their data center specifications. Finally, Microsoft noted that we can expect to see more details at the upcoming Microsoft Ignite conference in November and learn more about its GB200-powered AI systems.


Foxconn to Build Taiwan's Fastest AI Supercomputer With NVIDIA Blackwell
NVIDIA and Foxconn are building Taiwan's largest supercomputer, marking a milestone in the island's AI advancement. The project, Hon Hai Kaohsiung Super Computing Center, revealed Tuesday at Hon Hai Tech Day, will be built around NVIDIA's groundbreaking Blackwell architecture and feature the GB200 NVL72 platform, which includes a total of 64 racks and 4,608 Tensor Core GPUs. With an expected performance of over 90 exaflops of AI performance, the machine would easily be considered the fastest in Taiwan.
Foxconn plans to use the supercomputer, once operational, to power breakthroughs in cancer research, large language model development and smart city innovations, positioning Taiwan as a global leader in AI-driven industries. Foxconn's "three-platform strategy" focuses on smart manufacturing, smart cities and electric vehicles. The new supercomputer will play a pivotal role in supporting Foxconn's ongoing efforts in digital twins, robotic automation and smart urban infrastructure, bringing AI-assisted services to urban areas like Kaohsiung.



Foxconn plans to use the supercomputer, once operational, to power breakthroughs in cancer research, large language model development and smart city innovations, positioning Taiwan as a global leader in AI-driven industries. Foxconn's "three-platform strategy" focuses on smart manufacturing, smart cities and electric vehicles. The new supercomputer will play a pivotal role in supporting Foxconn's ongoing efforts in digital twins, robotic automation and smart urban infrastructure, bringing AI-assisted services to urban areas like Kaohsiung.





ASUS Presents Comprehensive AI Server Lineup
ASUS today announced its ambitious All in AI initiative, marking a significant leap into the server market with a complete AI infrastructure solution, designed to meet the evolving demands of AI-driven applications from edge, inference and generative AI the new, unparalleled wave of AI supercomputing. ASUS has proven its expertise lies in striking the perfect balance between hardware and software, including infrastructure and cluster architecture design, server installation, testing, onboarding, remote management and cloud services - positioning the ASUS brand and AI server solutions to lead the way in driving innovation and enabling the widespread adoption of AI across industries.
Meeting diverse AI needs
In partnership with NVIDIA, Intel and AMD, ASUS offer comprehensive AI-infrastructure solutions with robust software platforms and services, from entry-level AI servers and machine-learning solutions to full racks and data centers for large-scale supercomputing. At the forefront is the ESC AI POD with NVIDIA GB200 NVL72, a cutting-edge rack designed to accelerate trillion-token LLM training and real-time inference operations. Complemented by the latest NVIDIA Blackwell GPUs, NVIDIA Grace CPUs and 5th Gen NVIDIA NVLink technology, ASUS servers ensure unparalleled computing power and efficiency.



Meeting diverse AI needs
In partnership with NVIDIA, Intel and AMD, ASUS offer comprehensive AI-infrastructure solutions with robust software platforms and services, from entry-level AI servers and machine-learning solutions to full racks and data centers for large-scale supercomputing. At the forefront is the ESC AI POD with NVIDIA GB200 NVL72, a cutting-edge rack designed to accelerate trillion-token LLM training and real-time inference operations. Complemented by the latest NVIDIA Blackwell GPUs, NVIDIA Grace CPUs and 5th Gen NVIDIA NVLink technology, ASUS servers ensure unparalleled computing power and efficiency.




Global AI Server Demand Surge Expected to Drive 2024 Market Value to US$187 Billion; Represents 65% of Server Market
TrendForce's latest industry report on AI servers reveals that high demand for advanced AI servers from major CSPs and brand clients is expected to continue in 2024. Meanwhile, TSMC, SK hynix, Samsung, and Micron's gradual production expansion has significantly eased shortages in 2Q24. Consequently, the lead time for NVIDIA's flagship H100 solution has decreased from the previous 40-50 weeks to less than 16 weeks.
TrendForce estimates that AI server shipments in the second quarter will increase by nearly 20% QoQ, and has revised the annual shipment forecast up to 1.67 million units—marking a 41.5% YoY growth.
TrendForce estimates that AI server shipments in the second quarter will increase by nearly 20% QoQ, and has revised the annual shipment forecast up to 1.67 million units—marking a 41.5% YoY growth.

Blackwell Shipments Imminent, Total CoWoS Capacity Expected to Surge by Over 70% in 2025
TrendForce reports that NVIDIA's Hopper H100 began to see a reduction in shortages in 1Q24. The new H200 from the same platform is expected to gradually ramp in Q2, with the Blackwell platform entering the market in Q3 and expanding to data center customers in Q4. However, this year will still primarily focus on the Hopper platform, which includes the H100 and H200 product lines. The Blackwell platform—based on how far supply chain integration has progressed—is expected to start ramping up in Q4, accounting for less than 10% of the total high-end GPU market.
The die size of Blackwell platform chips like the B100 is twice that of the H100. As Blackwell becomes mainstream in 2025, the total capacity of TSMC's CoWoS is projected to grow by 150% in 2024 and by over 70% in 2025, with NVIDIA's demand occupying nearly half of this capacity. For HBM, the NVIDIA GPU platform's evolution sees the H100 primarily using 80 GB of HBM3, while the 2025 B200 will feature 288 GB of HBM3e—a 3-4 fold increase in capacity per chip. The three major manufacturers' expansion plans indicate that HBM production volume will likely double by 2025.
The die size of Blackwell platform chips like the B100 is twice that of the H100. As Blackwell becomes mainstream in 2025, the total capacity of TSMC's CoWoS is projected to grow by 150% in 2024 and by over 70% in 2025, with NVIDIA's demand occupying nearly half of this capacity. For HBM, the NVIDIA GPU platform's evolution sees the H100 primarily using 80 GB of HBM3, while the 2025 B200 will feature 288 GB of HBM3e—a 3-4 fold increase in capacity per chip. The three major manufacturers' expansion plans indicate that HBM production volume will likely double by 2025.

HBM3e Production Surge Expected to Make Up 35% of Advanced Process Wafer Input by End of 2024
TrendForce reports that the three largest DRAM suppliers are increasing wafer input for advanced processes. Following a rise in memory contract prices, companies have boosted their capital investments, with capacity expansion focusing on the second half of this year. It is expected that wafer input for 1alpha nm and above processes will account for approximately 40% of total DRAM wafer input by the end of the year.
HBM production will be prioritized due to its profitability and increasing demand. However, limited yields of around 50-60% and a wafer area 60% larger than DRAM products mean a higher proportion of wafer input is required. Based on the TSV capacity of each company, HBM is expected to account for 35% of advanced process wafer input by the end of this year, with the remaining wafer capacity used for LPDDR5(X) and DDR5 products.

HBM production will be prioritized due to its profitability and increasing demand. However, limited yields of around 50-60% and a wafer area 60% larger than DRAM products mean a higher proportion of wafer input is required. Based on the TSV capacity of each company, HBM is expected to account for 35% of advanced process wafer input by the end of this year, with the remaining wafer capacity used for LPDDR5(X) and DDR5 products.


NVIDIA Blackwell GB200 Superchip to Cost up to 70,000 US Dollars
According to analysts at HSBC, NVIDIA's upcoming Blackwell GPUs for AI workloads are expected to carry premium pricing significantly higher than the company's current Hopper-based processors. The analysts estimate that NVIDIA's "entry-level" Blackwell GPU, the B100, will have an average selling price between $30,000 and $35,000 per chip. That's already on par with the flagship H100 GPU from the previous Hopper generation. But the real premium lies with the top-end GB200 "superchip" that combines a Grace CPU with two enhanced B200 GPUs. HSBC analysts peg pricing for this monster chip at a staggering $60,000 to $70,000 per unit. NVIDIA may opt to primarily sell complete servers powered by Blackwell rather than individual chips. The estimates suggest a fully-loaded GB200 NVL72 server with 72 GB200 Superchips could fetch around $3 million.
The sky-high pricing continues NVIDIA's aggressive strategy of charging a premium for its leading AI and accelerator hardware. With rivals like AMD and Intel still lagging in this space, NVIDIA can essentially name its price for now. The premium pricing reflects the massive performance uplift promised by Blackwell. A single GB200 Superchip is rated for five PetaFLOPs at TF32 of AI compute power with sparsity, a 5x increase over the H100's one PetaFLOP. Of course, actual street pricing will depend on volume and negotiating power. Hyperscalers like Amazon and Microsoft may secure significant discounts, while smaller players could pay even more than these eye-watering analyst projections. NVIDIA is betting that the industry's insatiable demand for more AI compute power will make these premium price tags palatable, at least for a while. But it's also raising the stakes for competitors to catch up quickly before losing too much ground.
The sky-high pricing continues NVIDIA's aggressive strategy of charging a premium for its leading AI and accelerator hardware. With rivals like AMD and Intel still lagging in this space, NVIDIA can essentially name its price for now. The premium pricing reflects the massive performance uplift promised by Blackwell. A single GB200 Superchip is rated for five PetaFLOPs at TF32 of AI compute power with sparsity, a 5x increase over the H100's one PetaFLOP. Of course, actual street pricing will depend on volume and negotiating power. Hyperscalers like Amazon and Microsoft may secure significant discounts, while smaller players could pay even more than these eye-watering analyst projections. NVIDIA is betting that the industry's insatiable demand for more AI compute power will make these premium price tags palatable, at least for a while. But it's also raising the stakes for competitors to catch up quickly before losing too much ground.

NVIDIA Blackwell Platform Pushes the Boundaries of Scientific Computing
Quantum computing. Drug discovery. Fusion energy. Scientific computing and physics-based simulations are poised to make giant steps across domains that benefit humanity as advances in accelerated computing and AI drive the world's next big breakthroughs. NVIDIA unveiled at GTC in March the NVIDIA Blackwell platform, which promises generative AI on trillion-parameter large language models (LLMs) at up to 25x less cost and energy consumption than the NVIDIA Hopper architecture.
Blackwell has powerful implications for AI workloads, and its technology capabilities can also help to deliver discoveries across all types of scientific computing applications, including traditional numerical simulation. By reducing energy costs, accelerated computing and AI drive sustainable computing. Many scientific computing applications already benefit. Weather can be simulated at 200x lower cost and with 300x less energy, while digital twin simulations have 65x lower cost and 58x less energy consumption versus traditional CPU-based systems and others.



Blackwell has powerful implications for AI workloads, and its technology capabilities can also help to deliver discoveries across all types of scientific computing applications, including traditional numerical simulation. By reducing energy costs, accelerated computing and AI drive sustainable computing. Many scientific computing applications already benefit. Weather can be simulated at 200x lower cost and with 300x less energy, while digital twin simulations have 65x lower cost and 58x less energy consumption versus traditional CPU-based systems and others.

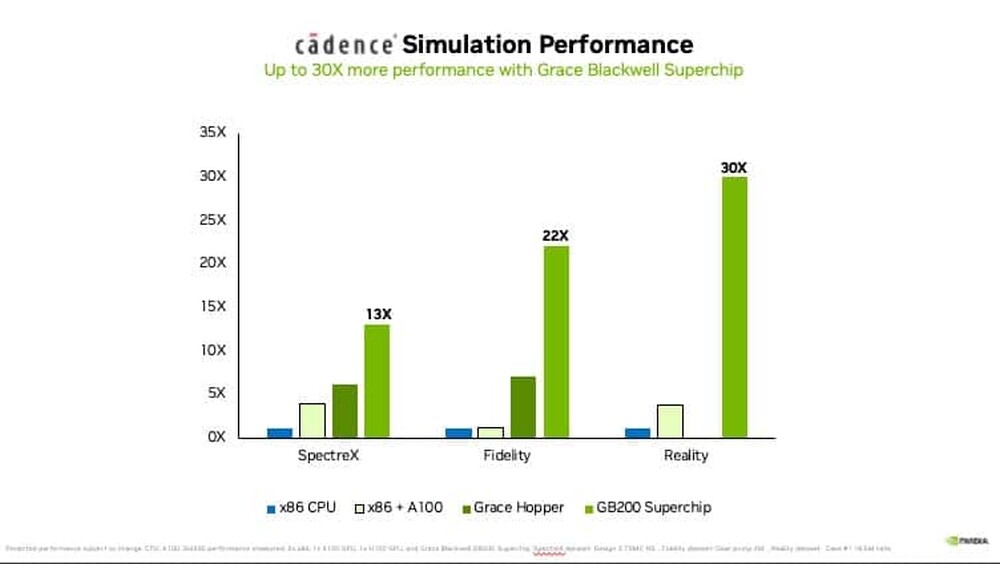
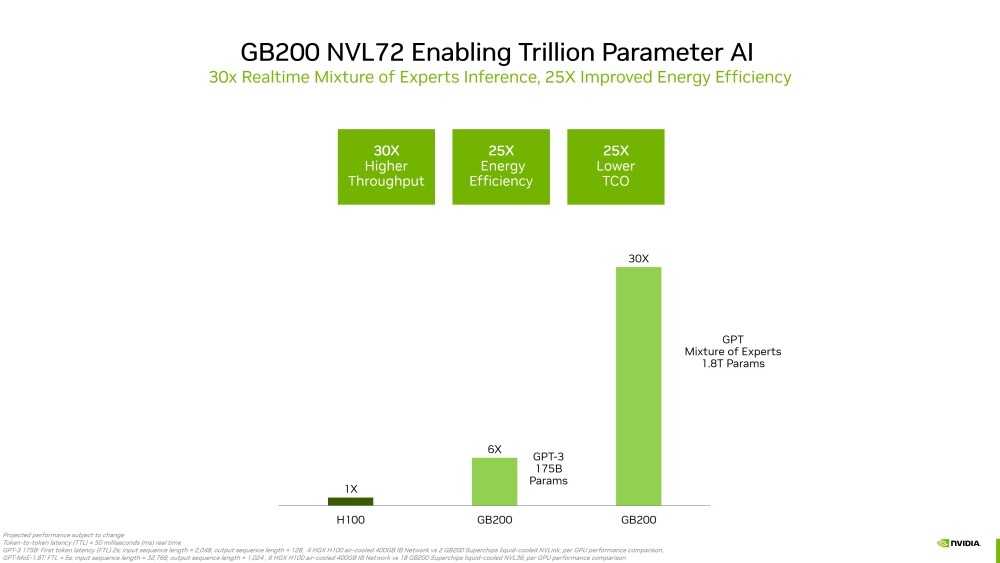

Demand for NVIDIA's Blackwell Platform Expected to Boost TSMC's CoWoS Total Capacity by Over 150% in 2024
NVIDIA's next-gen Blackwell platform, which includes B-series GPUs and integrates NVIDIA's own Grace Arm CPU in models such as the GB200, represents a significant development. TrendForce points out that the GB200 and its predecessor, the GH200, both feature a combined CPU+GPU solution, primarily equipped with the NVIDIA Grace CPU and H200 GPU. However, the GH200 accounted for only approximately 5% of NVIDIA's high-end GPU shipments. The supply chain has high expectations for the GB200, with projections suggesting that its shipments could exceed millions of units by 2025, potentially making up nearly 40 to 50% of NVIDIA's high-end GPU market.
Although NVIDIA plans to launch products such as the GB200 and B100 in the second half of this year, upstream wafer packaging will need to adopt more complex and high-precision CoWoS-L technology, making the validation and testing process time-consuming. Additionally, more time will be required to optimize the B-series for AI server systems in aspects such as network communication and cooling performance. It is anticipated that the GB200 and B100 products will not see significant production volumes until 4Q24 or 1Q25.
Although NVIDIA plans to launch products such as the GB200 and B100 in the second half of this year, upstream wafer packaging will need to adopt more complex and high-precision CoWoS-L technology, making the validation and testing process time-consuming. Additionally, more time will be required to optimize the B-series for AI server systems in aspects such as network communication and cooling performance. It is anticipated that the GB200 and B100 products will not see significant production volumes until 4Q24 or 1Q25.

U.S. Updates Advanced Semiconductor Ban, Actual Impact on the Industry Will Be Insignificant
On March 29th, the United States announced another round of updates to its export controls, targeting advanced computing, supercomputers, semiconductor end-uses, and semiconductor manufacturing products. These new regulations, which took effect on April 4th, are designed to prevent certain countries and businesses from circumventing U.S. restrictions to access sensitive chip technologies and equipment. Despite these tighter controls, TrendForce believes the practical impact on the industry will be minimal.
The latest updates aim to refine the language and parameters of previous regulations, tightening the criteria for exports to Macau and D:5 countries (China, North Korea, Russia, Iran, etc.). They require a detailed examination of all technology products' Total Processing Performance (TPP) and Performance Density (PD). If a product exceeds certain computing power thresholds, it must undergo a case-by-case review. Nevertheless, a new provision, Advanced Computing Authorized (ACA), allows for specific exports and re-exports among selected countries, including the transshipment of particular products between Macau and D:5 countries.
The latest updates aim to refine the language and parameters of previous regulations, tightening the criteria for exports to Macau and D:5 countries (China, North Korea, Russia, Iran, etc.). They require a detailed examination of all technology products' Total Processing Performance (TPP) and Performance Density (PD). If a product exceeds certain computing power thresholds, it must undergo a case-by-case review. Nevertheless, a new provision, Advanced Computing Authorized (ACA), allows for specific exports and re-exports among selected countries, including the transshipment of particular products between Macau and D:5 countries.

Nvidia CEO Reiterates Solid Partnership with TSMC
One key takeaway from the ongoing GTC is that Nvidia's AI empire has taken shape with strong partnerships from TSMC and other Taiwanese makers, such as those major server ODMs.
According to the news report from the technology-focused media DIGITIMES Asia, during his keynote at GTC on March 18, Huang underscored his company's partnerships with TSMC, as well as the supply chain in Taiwan. Speaking to the press later, Huang said Nvidia will have a very strong demand for CoWoS, the advanced packaging services TSMC offers.
According to the news report from the technology-focused media DIGITIMES Asia, during his keynote at GTC on March 18, Huang underscored his company's partnerships with TSMC, as well as the supply chain in Taiwan. Speaking to the press later, Huang said Nvidia will have a very strong demand for CoWoS, the advanced packaging services TSMC offers.

Jensen Huang Discloses NVIDIA Blackwell GPU Pricing: $30,000 to $40,000
Jensen Huang has been talking to media outlets following the conclusion of his keynote presentation at NVIDIA's GTC 2024 conference—an NBC TV "exclusive" interview with the Team Green boss has caused a stir in tech circles. Jim Cramer's long-running "Squawk on the Street" trade segment hosted Huang for just under five minutes—NBC's presenter labelled the latest edition of GTC the "Woodstock of AI." NVIDIA's leader reckoned that around $1 trillion of industry was in attendance at this year's event—folks turned up to witness the unveiling of "Blackwell" B200 and GB200 AI GPUs. In the interview, Huang estimated that his company had invested around $10 billion into the research and development of its latest architecture: "we had to invent some new technology to make it possible."
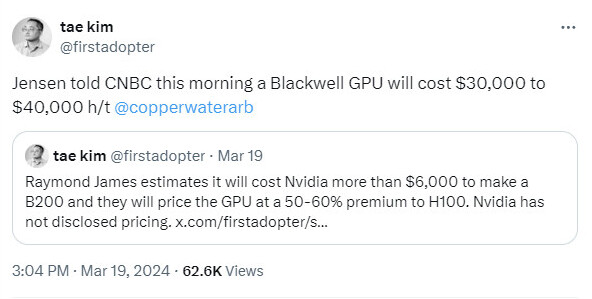
Industry watchdogs have seized on a major revelation—as disclosed during the televised NBC report—Huang revealed that his next-gen AI GPUs "will cost between $30,000 and $40,000 per unit." NVIDIA (and its rivals) are not known to publicly announce price ranges for AI and HPC chips—leaks from hardware partners and individuals within industry supply chains are the "usual" sources. An investment banking company has already delved into alleged Blackwell production costs—as shared by Tae Kim/firstadopter: "Raymond James estimates it will cost NVIDIA more than $6000 to make a B200 and they will price the GPU at a 50-60% premium to H100...(the bank) estimates it costs NVIDIA $3320 to make the H100, which is then sold to customers for $25,000 to $30,000." Huang's disclosure should be treated as an approximation, since his company (normally) deals with the supply of basic building blocks.


Industry watchdogs have seized on a major revelation—as disclosed during the televised NBC report—Huang revealed that his next-gen AI GPUs "will cost between $30,000 and $40,000 per unit." NVIDIA (and its rivals) are not known to publicly announce price ranges for AI and HPC chips—leaks from hardware partners and individuals within industry supply chains are the "usual" sources. An investment banking company has already delved into alleged Blackwell production costs—as shared by Tae Kim/firstadopter: "Raymond James estimates it will cost NVIDIA more than $6000 to make a B200 and they will price the GPU at a 50-60% premium to H100...(the bank) estimates it costs NVIDIA $3320 to make the H100, which is then sold to customers for $25,000 to $30,000." Huang's disclosure should be treated as an approximation, since his company (normally) deals with the supply of basic building blocks.

NVIDIA "Blackwell" GeForce RTX to Feature Same 5nm-based TSMC 4N Foundry Node as GB100 AI GPU
Following Monday's blockbuster announcements of the "Blackwell" architecture and NVIDIA's B100, B200, and GB200 AI GPUs, all eyes are now on its client graphics derivatives, or the GeForce RTX GPUs that implement "Blackwell" as a graphics architecture. Leading the effort will be the new GB202 ASIC, a successor to the AD102 powering the current RTX 4090. This will be NVIDIA's biggest GPU with raster graphics and ray tracing capabilities. The GB202 is rumored to be followed by the GB203 in the premium segment, the GB205 a notch lower, and the GB206 further down the stack. Kopite7kimi, a reliable source with NVIDIA leaks, says that the GB202 silicon will be built on the same TSMC 4N foundry node as the GB100.
TSMC 4N is a derivative of the company's mainline N4P node, the "N" in 4N stands for NVIDIA. This is a nodelet that TSMC designed with optimization for NVIDIA SoCs. TSMC still considers the 4N as a derivative of the 5 nm EUV node. There is very little public information on the power- and transistor density improvements of the TSMC 4N over TSMC N5. For reference, the N4P, which TSMC regards as a 5 nm derivative, offers a 6% transistor-density improvement, and a 22% power efficiency improvement. In related news, Kopite7kimi says that with "Blackwell," NVIDIA is focusing on enlarging the L1 caches of the streaming multiprocessors (SM), which suggests a design focus on increasing the performance at an SM-level.
TSMC 4N is a derivative of the company's mainline N4P node, the "N" in 4N stands for NVIDIA. This is a nodelet that TSMC designed with optimization for NVIDIA SoCs. TSMC still considers the 4N as a derivative of the 5 nm EUV node. There is very little public information on the power- and transistor density improvements of the TSMC 4N over TSMC N5. For reference, the N4P, which TSMC regards as a 5 nm derivative, offers a 6% transistor-density improvement, and a 22% power efficiency improvement. In related news, Kopite7kimi says that with "Blackwell," NVIDIA is focusing on enlarging the L1 caches of the streaming multiprocessors (SM), which suggests a design focus on increasing the performance at an SM-level.

Unwrapping the NVIDIA B200 and GB200 AI GPU Announcements
NVIDIA on Monday, at the 2024 GTC conference, unveiled the "Blackwell" B200 and GB200 AI GPUs. These are designed to offer an incredible 5X the AI inferencing performance gain over the current-gen "Hopper" H100, and come with four times the on-package memory. The B200 "Blackwell" is the largest chip physically possible using existing foundry tech, according to its makers. The chip is an astonishing 208 billion transistors, and is made up of two chiplets, which by themselves are the largest possible chips.
Each chiplet is built on the TSMC N4P foundry node, which is the most advanced 4 nm-class node by the Taiwanese foundry. Each chiplet has 104 billion transistors. The two chiplets have a high degree of connectivity with each other, thanks to a 10 TB/s custom interconnect. This is enough bandwidth and latency for the two to maintain cache coherency (i.e. address each other's memory as if they're their own). Each of the two "Blackwell" chiplets has a 4096-bit memory bus, and is wired to 96 GB of HBM3E spread across four 24 GB stacks; which totals to 192 GB for the B200 package. The GPU has a staggering 8 TB/s of memory bandwidth on tap. The B200 package features a 1.8 TB/s NVLink interface for host connectivity, and connectivity to another B200 chip.



Each chiplet is built on the TSMC N4P foundry node, which is the most advanced 4 nm-class node by the Taiwanese foundry. Each chiplet has 104 billion transistors. The two chiplets have a high degree of connectivity with each other, thanks to a 10 TB/s custom interconnect. This is enough bandwidth and latency for the two to maintain cache coherency (i.e. address each other's memory as if they're their own). Each of the two "Blackwell" chiplets has a 4096-bit memory bus, and is wired to 96 GB of HBM3E spread across four 24 GB stacks; which totals to 192 GB for the B200 package. The GPU has a staggering 8 TB/s of memory bandwidth on tap. The B200 package features a 1.8 TB/s NVLink interface for host connectivity, and connectivity to another B200 chip.




Mar 29th, 2025 07:52 EDT
change timezone
Latest GPU Drivers
New Forum Posts
- Upgrade from a AMD AM3+ to AM4 or AM5 chipset MB running W10? (17)
- Future-proofing my OLED (57)
- Windows 10 Vs 11, Which one too choose? (118)
- What are you playing? (23306)
- RTX 5080 - performance fluctuation (6)
- Did Nvidia purposely gimp the performance of 50xx series cards with drivers (114)
- AMD RX 9070 XT & RX 9070 non-XT thread (OC, undervolt, benchmarks, ...) (71)
- TPU's F@H Team (20414)
- Have you got pie today? (16650)
- Which thermal paste never pumps out? (67)
Popular Reviews
- Sapphire Radeon RX 9070 XT Pulse Review
- Samsung 9100 Pro 2 TB Review - The Best Gen 5 SSD
- ASRock Phantom Gaming B850 Riptide Wi-Fi Review - Amazing Price/Performance
- Assassin's Creed Shadows Performance Benchmark Review - 30 GPUs Compared
- be quiet! Pure Rock Pro 3 Black Review
- Sapphire Radeon RX 9070 XT Nitro+ Review - Beating NVIDIA
- ASRock Radeon RX 9070 XT Taichi OC Review - Excellent Cooling
- Palit GeForce RTX 5070 GamingPro OC Review
- Pulsar Feinmann F01 Review
- AMD Ryzen 7 9800X3D Review - The Best Gaming Processor
Controversial News Posts
- AMD RDNA 4 and Radeon RX 9070 Series Unveiled: $549 & $599 (260)
- MSI Doesn't Plan Radeon RX 9000 Series GPUs, Skips AMD RDNA 4 Generation Entirely (142)
- Microsoft Introduces Copilot for Gaming (123)
- AMD Radeon RX 9070 XT Reportedly Outperforms RTX 5080 Through Undervolting (118)
- NVIDIA Reportedly Prepares GeForce RTX 5060 and RTX 5060 Ti Unveil Tomorrow (115)
- Over 200,000 Sold Radeon RX 9070 and RX 9070 XT GPUs? AMD Says No Number was Given (100)
- NVIDIA GeForce RTX 5050, RTX 5060, and RTX 5060 Ti Specifications Leak (96)
- Retailers Anticipate Increased Radeon RX 9070 Series Prices, After Initial Shipments of "MSRP" Models (90)