Tuesday, March 19th 2024

Unwrapping the NVIDIA B200 and GB200 AI GPU Announcements
NVIDIA on Monday, at the 2024 GTC conference, unveiled the "Blackwell" B200 and GB200 AI GPUs. These are designed to offer an incredible 5X the AI inferencing performance gain over the current-gen "Hopper" H100, and come with four times the on-package memory. The B200 "Blackwell" is the largest chip physically possible using existing foundry tech, according to its makers. The chip is an astonishing 208 billion transistors, and is made up of two chiplets, which by themselves are the largest possible chips.
Each chiplet is built on the TSMC N4P foundry node, which is the most advanced 4 nm-class node by the Taiwanese foundry. Each chiplet has 104 billion transistors. The two chiplets have a high degree of connectivity with each other, thanks to a 10 TB/s custom interconnect. This is enough bandwidth and latency for the two to maintain cache coherency (i.e. address each other's memory as if they're their own). Each of the two "Blackwell" chiplets has a 4096-bit memory bus, and is wired to 96 GB of HBM3E spread across four 24 GB stacks; which totals to 192 GB for the B200 package. The GPU has a staggering 8 TB/s of memory bandwidth on tap. The B200 package features a 1.8 TB/s NVLink interface for host connectivity, and connectivity to another B200 chip.


 NVIDIA also announced the Grace-Blackwell GB200 Superchip. This is a module that has two B200 GPUs wired to an NVIDIA Grace CPU that offers superior serial processing performance than x86-64 based CPUs from Intel or AMD; and an ISA that's highly optimized for NVIDIA's AI GPUs. The biggest advantage of the Grace CPU over an Intel Xeon Scalable or AMD EPYC has to be its higher bandwidth NVLink interconnect to the GPUs, compared to PCIe connections for x86-64 hosts. NVIDIA appears to be carrying over the Grace CPU from the GH200 Grace-Hopper Superchip.
NVIDIA also announced the Grace-Blackwell GB200 Superchip. This is a module that has two B200 GPUs wired to an NVIDIA Grace CPU that offers superior serial processing performance than x86-64 based CPUs from Intel or AMD; and an ISA that's highly optimized for NVIDIA's AI GPUs. The biggest advantage of the Grace CPU over an Intel Xeon Scalable or AMD EPYC has to be its higher bandwidth NVLink interconnect to the GPUs, compared to PCIe connections for x86-64 hosts. NVIDIA appears to be carrying over the Grace CPU from the GH200 Grace-Hopper Superchip.


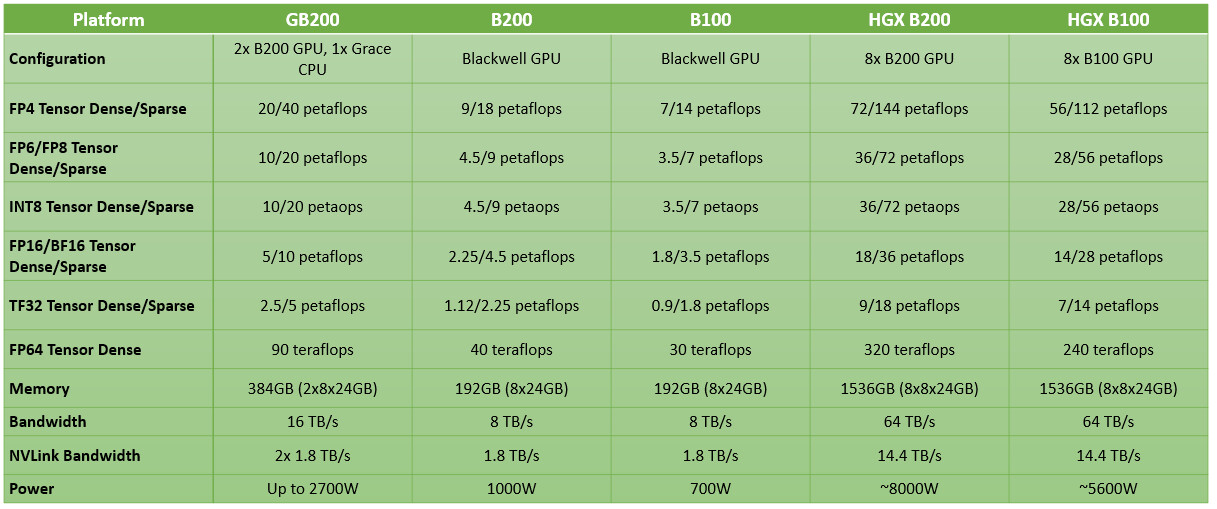
 NVIDIA did not disclose the counts of the various SIMD components such as streaming multiprocessors per chiplet, CUDA cores, Tensor cores, or on-die cache sizes, but made performance claims. Each B200 chip provides 20 PFLOPs (that's 20,000 TFLOPs) of AI inferencing performance. "Blackwell" introduces NVIDIA's 2nd generation Transformer engine, and 6th generation Tensor core, which supports FP4 and FP6. The 5th Gen NVLink interface not just scales up within the node, but also scales out to up to 576 GPUs. Among NVIDIA's performance claims for the GB200 are 20 PFLOPs FP4 Tensor (dense), and 40 PFLOPs FP4 Tensor (sparse); 10 PFLOPs FP8 Tensor (dense); and 20 PFLOPs FP8 Tensor (sparse); 5 PFLOPs Bfloat16 and FP16 (10 PFLOPs with sparsity); and 2.5 PFLOPs TF32 Tensor (dense) with 5 PFLOPs (sparse). As a high-precision compute accelerator (FP64), the B200 provides 90 TFLOPs, which is a 3x increase over that of the GH200 "Hopper."
NVIDIA did not disclose the counts of the various SIMD components such as streaming multiprocessors per chiplet, CUDA cores, Tensor cores, or on-die cache sizes, but made performance claims. Each B200 chip provides 20 PFLOPs (that's 20,000 TFLOPs) of AI inferencing performance. "Blackwell" introduces NVIDIA's 2nd generation Transformer engine, and 6th generation Tensor core, which supports FP4 and FP6. The 5th Gen NVLink interface not just scales up within the node, but also scales out to up to 576 GPUs. Among NVIDIA's performance claims for the GB200 are 20 PFLOPs FP4 Tensor (dense), and 40 PFLOPs FP4 Tensor (sparse); 10 PFLOPs FP8 Tensor (dense); and 20 PFLOPs FP8 Tensor (sparse); 5 PFLOPs Bfloat16 and FP16 (10 PFLOPs with sparsity); and 2.5 PFLOPs TF32 Tensor (dense) with 5 PFLOPs (sparse). As a high-precision compute accelerator (FP64), the B200 provides 90 TFLOPs, which is a 3x increase over that of the GH200 "Hopper." NVIDIA is expected to ship the B100, B200, and GB200, and their first-party derivatives, such as the SuperPODs, later this year.
NVIDIA is expected to ship the B100, B200, and GB200, and their first-party derivatives, such as the SuperPODs, later this year.
Source:
Tom's Hardware
Each chiplet is built on the TSMC N4P foundry node, which is the most advanced 4 nm-class node by the Taiwanese foundry. Each chiplet has 104 billion transistors. The two chiplets have a high degree of connectivity with each other, thanks to a 10 TB/s custom interconnect. This is enough bandwidth and latency for the two to maintain cache coherency (i.e. address each other's memory as if they're their own). Each of the two "Blackwell" chiplets has a 4096-bit memory bus, and is wired to 96 GB of HBM3E spread across four 24 GB stacks; which totals to 192 GB for the B200 package. The GPU has a staggering 8 TB/s of memory bandwidth on tap. The B200 package features a 1.8 TB/s NVLink interface for host connectivity, and connectivity to another B200 chip.








27 Comments on Unwrapping the NVIDIA B200 and GB200 AI GPU Announcements
One thing is 10 different hardware announcements about the same product in one day. One way to make me turn green, from sickness. Someone needs to peruse Nvidia's payroll!
..and the Pc Gamer FOMO sucker crowd, will lap them up.
...well, apart from quality streamers whom oh so naively use these overpowered PCs to create the ultimate viewing experience instead of the ever so popular formulae of Tits&Asses.
reticle limit is haved again for N1.x node so this interconnect really paves the way for big dies like the 90-class in the future.
it may even explain why 5080 is exactly the half of 5090, the latter is two 5080s with 12288 CUDA/256 bit memory glued together.
So, I expect the RTX5090 to pull around 500W, thus the new power connector makes sense, which supplies 600W, which leaves just a little headroom for overclocking while still being within the specified limits. (I still don't like the new connector, it doesn't inspire confidence, and the old 8-pins work)
I am rambling; that is a lot of money power-wise, never mind having to sit in an oven, sure it's comfy in the winter, but not so much in the summer, AC's are expensive to run in some countries, so I always look for the best Priced/Power/Performance GPU near the 200-250W mark. I have to take into account the wattage from my CPU and other components, the whole PC itself should not draw more than 500W under full load, it's why I like to under-volt and get the best clocks for said under-volt, it's more fun too than overclocking in my opinion. :DI am not so much up to date with the new A.I business side of things, but I wonder if one can use the said A.I, to take an old game that is loved and re-render the game, say, in the U5 engine?
Would love for this to happen to some golden oldies that haven't received re-makes yet and are dear to my heart, all raytraced, the light that got baked in has become much better over time in games, however, I always notice the inconsistencies, so I just love that this is finally a thing, hopefully, leatherjacket man will give us more Tensor cores so the raytracing tasks can be managed easier, reminds me of the tesselation days.
Games like:
Deus-Ex 1999
Freelancer
KotoR 1 & 2
Vampire: The Masquerade Bloodlines
The Prince of Persia Trilogy
Max Payne 1 & 2
Commandos 1, 2 & 3 (Who remembers these? So much fun)
Unreal
American McGee's Alice
Neverwinter Nights 1 & 2
Damn, I miss the EAX audio days too, it's miles ahead of the crap we have today. Who remembers F.E.A.R? Or the first Bioshock with EAX? Damn, I still have my soundcard today, just to listen to those all games SING!
Rambling, why am I rambling today? :S
"We are making this impractically expensive because we bet you will pay anything we ask."
This applies to gamers too. Dark times are coming, especially without competition at the high end. I place a prediction right now that 5090 shall be $2599.00 MSRP and the same perf/$ as 40 series.
Think of them like the H100 datacenter accelerators that Nvidia currently makes which are also impossibly expensive and not a reflection on the RTX 40-series.
Y'all need to chill... ;)
Edit: and right on cue
videocardz.com/newz/nvidia-rtx-50-gb202-gaming-gpu-reportedly-features-the-same-tsmc-4np-process-as-b100
I'll pretend it's not a lie. The whole presentation is full of make-up to make it look bigger and better. lol
This does not bode well for RTX 5000 series. I very much doubt those will use 3nm either.
Now I remember
Voodoo 5Be like the voodoo 5 6000 with a power supply outside the box.
I remember when Nvidia roadmaps said in 2017 they were going to build lower power GPU's with higher graphics power. To help climate change and environment. Then with 3000 Series the idea went out the window down the stream into oceans and lost forever. Jensen said screw that more power let get 1000 watt video cards instead.
Also look at slide NV link now which is basically SLI on a single board. I said that's what they were going to do 2 years ago. Guess what I was right. Following the 3dfx path to ruin all over again.
A100
RTX 3090