Giga Computing Unveils Liquid and Air-Cooled GIGABYTE AI Servers Accelerated by NVIDIA HGX B200 Platform
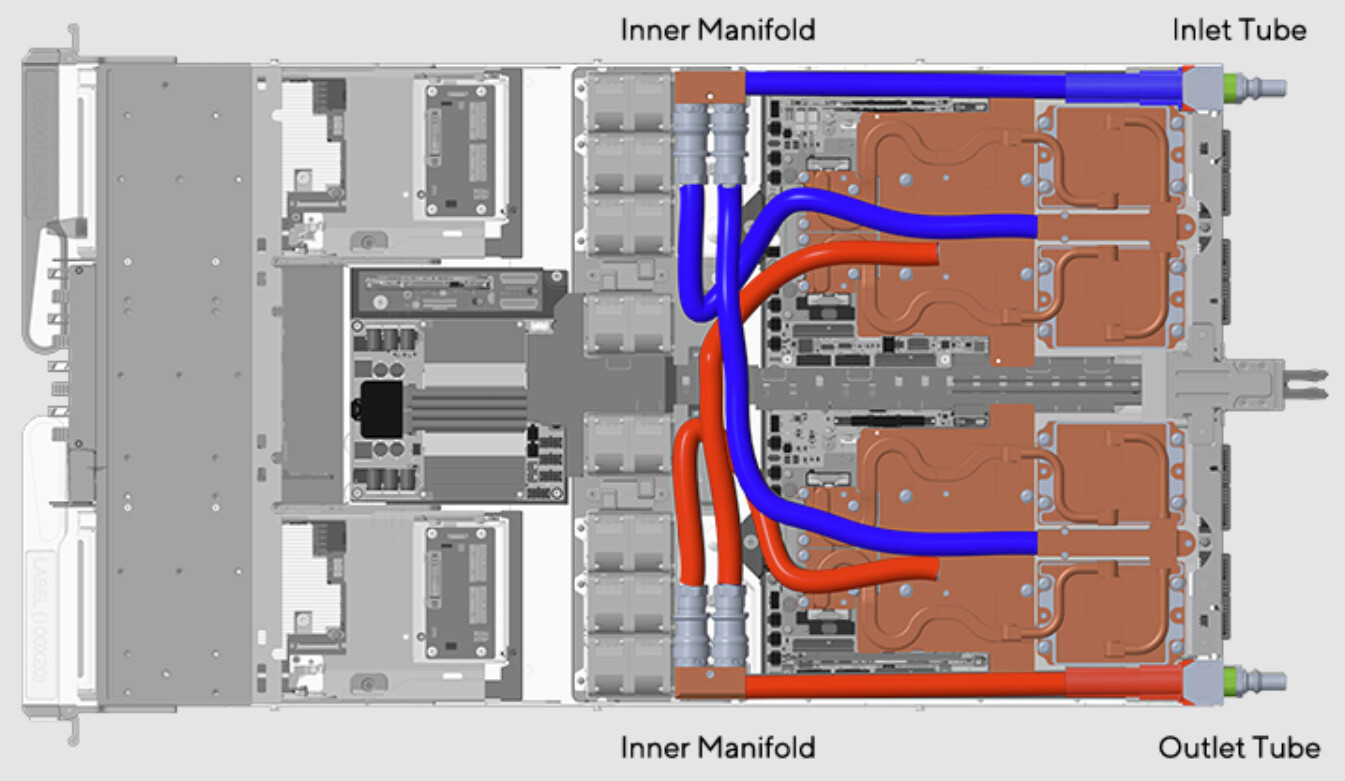
Giga Computing, an industry innovator and leader in enterprise hardware and advanced cooling solutions, today announced four new GIGABYTE servers built on the NVIDIA HGX B200 platform. This expansion of the GIGABYTE GPU server portfolio brings greater thermal design flexibility and support for the latest processors, including the new AI-optimized Intel Xeon 6 CPUs, giving customers more options as they tailor their systems for workloads and efficiency.
NVIDIA HGX B200 propels the data center into a new era of accelerating computing and generative AI. Built on NVIDIA Blackwell GPUs, the HGX B200 platform features 15X faster real-time inference on trillion-parameter models.


NVIDIA HGX B200 propels the data center into a new era of accelerating computing and generative AI. Built on NVIDIA Blackwell GPUs, the HGX B200 platform features 15X faster real-time inference on trillion-parameter models.