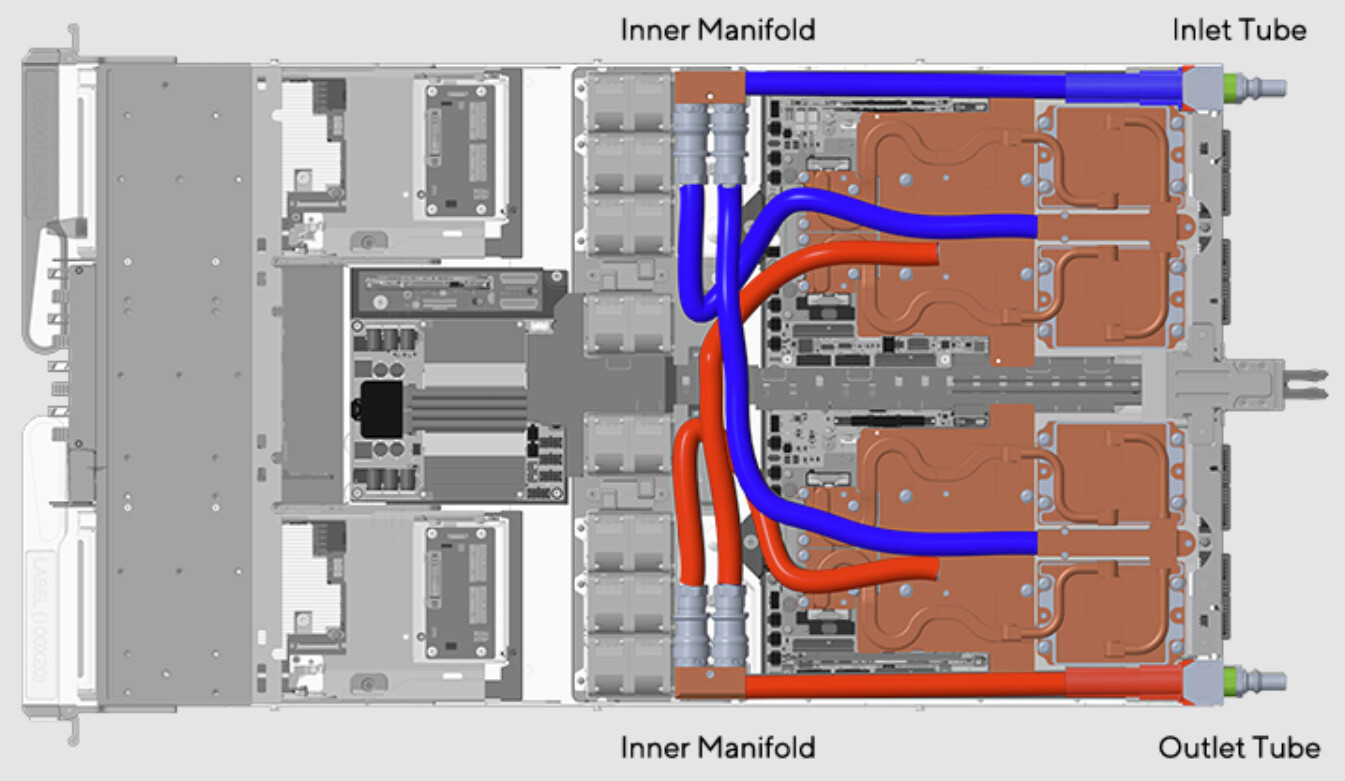
Thousands of NVIDIA Grace Blackwell GPUs Now Live at CoreWeave
CoreWeave today became one of the first cloud providers to bring NVIDIA GB200 NVL72 systems online for customers at scale, and AI frontier companies Cohere, IBM and Mistral AI are already using them to train and deploy next-generation AI models and applications. CoreWeave, the first cloud provider to make NVIDIA Grace Blackwell generally available, has already shown incredible results in MLPerf benchmarks with NVIDIA GB200 NVL72 - a powerful rack-scale accelerated computing platform designed for reasoning and AI agents. Now, CoreWeave customers are gaining access to thousands of NVIDIA Blackwell GPUs.
"We work closely with NVIDIA to quickly deliver to customers the latest and most powerful solutions for training AI models and serving inference," said Mike Intrator, CEO of CoreWeave. "With new Grace Blackwell rack-scale systems in hand, many of our customers will be the first to see the benefits and performance of AI innovators operating at scale."
"We work closely with NVIDIA to quickly deliver to customers the latest and most powerful solutions for training AI models and serving inference," said Mike Intrator, CEO of CoreWeave. "With new Grace Blackwell rack-scale systems in hand, many of our customers will be the first to see the benefits and performance of AI innovators operating at scale."