Apr 18th, 2025 16:09 EDT
change timezone
Latest GPU Drivers
New Forum Posts
- How to relubricate a fan and/or service a troublesome/noisy fan. (242)
- It's happening again, melting 12v high pwr connectors (1027)
- RX 9000 series GPU Owners Club (393)
- Can Intel recover in DYI market anytime soon? (11)
- Place your bets, what node will rtx 6000/RDNA 5(UDNA 1?) use (8)
- TPU's Nostalgic Hardware Club (20257)
- GPU Pricing and Performance (15)
- What are you playing? (23396)
- Spoofer Modified SMBIOS/BIOS – Need Help Restoring Original Motherboard Info (TUF GAMING B550-PLUS WiFi II) (2)
- Tried installing 576.02 - installer window disappears (20)
Popular Reviews
- ASUS GeForce RTX 5060 Ti TUF OC 16 GB Review
- NVIDIA GeForce RTX 5060 Ti PCI-Express x8 Scaling
- Palit GeForce RTX 5060 Ti Infinity 3 16 GB Review
- G.SKILL Trident Z5 NEO RGB DDR5-6000 32 GB CL26 Review - AMD EXPO
- ASUS GeForce RTX 5060 Ti Prime OC 16 GB Review
- Teevolution Terra Pro Review
- MSI GeForce RTX 5060 Ti Gaming OC 16 GB Review
- Zotac GeForce RTX 5060 Ti AMP 16 GB Review
- MSI GeForce RTX 5060 Ti Gaming Trio OC 16 GB Review
- ASUS GeForce RTX 5080 TUF OC Review
Controversial News Posts
- NVIDIA GeForce RTX 5060 Ti 16 GB SKU Likely Launching at $499, According to Supply Chain Leak (182)
- NVIDIA Sends MSRP Numbers to Partners: GeForce RTX 5060 Ti 8 GB at $379, RTX 5060 Ti 16 GB at $429 (127)
- Nintendo Confirms That Switch 2 Joy-Cons Will Not Utilize Hall Effect Stick Technology (105)
- NVIDIA Launches GeForce RTX 5060 Series, Beginning with RTX 5060 Ti This Week (101)
- Over 200,000 Sold Radeon RX 9070 and RX 9070 XT GPUs? AMD Says No Number was Given (100)
- Nintendo Switch 2 Launches June 5 at $449.99 with New Hardware and Games (99)
- Sony Increases the PS5 Pricing in EMEA and ANZ by Around 25 Percent (85)
- NVIDIA PhysX and Flow Made Fully Open-Source (77)
News Posts matching #Grace
Return to Keyword BrowsingHuawei CloudMatrix 384 System Outperforms NVIDIA GB200 NVL72
Huawei announced its CloudMatrix 384 system super node, which the company touts as its own domestic alternative to NVIDIA's GB200 NVL72 system, with more overall system performance but worse per-chip performance and higher power consumption. While NVIDIA's GB200 NVL72 uses 36 Grace CPUs paired with 72 "Blackwell" GB200 GPUs, the Huawei CloudMatrix 384 system employs 384 Huawei Ascend 910C accelerators to beat NVIDIA's GB200 NVL72 system. It takes roughly five times more Ascend 910C accelerators to deliver nearly twice the GB200 NVL system performance, which is not good on per-accelerator bias, but excellent on per-system level of deployment. SemiAnalysis argues that Huawei is a generation behind in chip performance but ahead of NVIDIA in scale-up system design and deployment.
When you look at individual chips, NVIDIA's GB200 NVL72 clearly outshines Huawei's Ascend 910C, delivering over three times the BF16 performance (2,500 TeraFLOPS vs. 780 TeraFLOPS), more on‑chip memory (192 GB vs. 128 GB), and faster bandwidth (8 TB/s vs. 3.2 TB/s). In other words, NVIDIA has the raw power and efficiency advantage at the chip level. But flip the switch to the system level, and Huawei's CloudMatrix CM384 takes the lead. It cranks out 1.7× the overall PetaFLOPS, packs in 3.6× more total HBM capacity, and supports over five times the number of GPUs and the associated bandwidth of NVIDIA's NVL72 cluster. However, that scalability does come with a trade‑off, as Huawei's setup draws nearly four times more total power. A single GB200 NVL72 draws 145 kW of power, while a single Huawei CloudMatrix 384 draws ~560 kW. So, NVIDIA is your go-to if you need peak efficiency in a single GPU. If you're building a massive AI supercluster where total throughput and interconnect speed matter most, Huawei's solution actually makes a lot of sense. Thanks to its all-to-all topology, Huawei has delivered an AI training and inference system worth purchasing. When SMIC, the maker of Huawei's chips, gets to a more advanced manufacturing node, the efficiency of these systems will also increase.

When you look at individual chips, NVIDIA's GB200 NVL72 clearly outshines Huawei's Ascend 910C, delivering over three times the BF16 performance (2,500 TeraFLOPS vs. 780 TeraFLOPS), more on‑chip memory (192 GB vs. 128 GB), and faster bandwidth (8 TB/s vs. 3.2 TB/s). In other words, NVIDIA has the raw power and efficiency advantage at the chip level. But flip the switch to the system level, and Huawei's CloudMatrix CM384 takes the lead. It cranks out 1.7× the overall PetaFLOPS, packs in 3.6× more total HBM capacity, and supports over five times the number of GPUs and the associated bandwidth of NVIDIA's NVL72 cluster. However, that scalability does come with a trade‑off, as Huawei's setup draws nearly four times more total power. A single GB200 NVL72 draws 145 kW of power, while a single Huawei CloudMatrix 384 draws ~560 kW. So, NVIDIA is your go-to if you need peak efficiency in a single GPU. If you're building a massive AI supercluster where total throughput and interconnect speed matter most, Huawei's solution actually makes a lot of sense. Thanks to its all-to-all topology, Huawei has delivered an AI training and inference system worth purchasing. When SMIC, the maker of Huawei's chips, gets to a more advanced manufacturing node, the efficiency of these systems will also increase.



Thousands of NVIDIA Grace Blackwell GPUs Now Live at CoreWeave
CoreWeave today became one of the first cloud providers to bring NVIDIA GB200 NVL72 systems online for customers at scale, and AI frontier companies Cohere, IBM and Mistral AI are already using them to train and deploy next-generation AI models and applications. CoreWeave, the first cloud provider to make NVIDIA Grace Blackwell generally available, has already shown incredible results in MLPerf benchmarks with NVIDIA GB200 NVL72 - a powerful rack-scale accelerated computing platform designed for reasoning and AI agents. Now, CoreWeave customers are gaining access to thousands of NVIDIA Blackwell GPUs.
"We work closely with NVIDIA to quickly deliver to customers the latest and most powerful solutions for training AI models and serving inference," said Mike Intrator, CEO of CoreWeave. "With new Grace Blackwell rack-scale systems in hand, many of our customers will be the first to see the benefits and performance of AI innovators operating at scale."
"We work closely with NVIDIA to quickly deliver to customers the latest and most powerful solutions for training AI models and serving inference," said Mike Intrator, CEO of CoreWeave. "With new Grace Blackwell rack-scale systems in hand, many of our customers will be the first to see the benefits and performance of AI innovators operating at scale."

Quantum Machines Anticipates Collaborative Breakthroughs at NVIDIA's New Research Center
Quantum Machines (QM), a leading provider of advanced quantum control solutions, today announced its intention to work with NVIDIA at its newly established NVIDIA Accelerated Quantum Research Center (NVAQC), unveiled at the GTC global AI conference. The Boston-based center aims to advance quantum computing research with accelerated computing, including integrating quantum processors with AI- supercomputing to overcome significant challenges in the quantum computing space. As quantum computing rapidly evolves, the integration of quantum processors with powerful AI supercomputers becomes increasingly essential. These accelerated quantum supercomputers are pivotal for advancing quantum error correction, device control, and algorithm development.
Quantum Machines joins other quantum computing pioneers, including Quantinuum and QuEra, along with academic partners from Harvard and MIT, in working with NVIDIA at the NVAQC to develop pioneering research. Quantum Machines will work with NVIDIA to integrate its NVIDIA GB200 Grace Blackwell Superchips with QM's advanced quantum control technologies, including the OPX1000. This integration will facilitate rapid, high-bandwidth communication between quantum processors and classical supercomputers. QM and NVIDIA thereby lay the essential foundations for quantum error correction and robust quantum algorithm execution. By reducing latency and enhancing processing efficiency, QM and NVIDIA solutions will significantly accelerate practical applications of quantum computing.


Quantum Machines joins other quantum computing pioneers, including Quantinuum and QuEra, along with academic partners from Harvard and MIT, in working with NVIDIA at the NVAQC to develop pioneering research. Quantum Machines will work with NVIDIA to integrate its NVIDIA GB200 Grace Blackwell Superchips with QM's advanced quantum control technologies, including the OPX1000. This integration will facilitate rapid, high-bandwidth communication between quantum processors and classical supercomputers. QM and NVIDIA thereby lay the essential foundations for quantum error correction and robust quantum algorithm execution. By reducing latency and enhancing processing efficiency, QM and NVIDIA solutions will significantly accelerate practical applications of quantum computing.



Supermicro Adds Portfolio for Next Wave of AI with NVIDIA Blackwell Ultra Solutions
Supermicro, Inc., a Total IT Solution Provider for AI, Cloud, Storage, and 5G/Edge, is announcing new systems and rack solutions powered by the NVIDIA's Blackwell Ultra platform, featuring the NVIDIA HGX B300 NVL16 and NVIDIA GB300 NVL72 platforms. Supermicro and NVIDIA's new AI solutions strengthen leadership in AI by delivering breakthrough performance for the most compute-intensive AI workloads, including AI reasoning, agentic AI, and video inference applications.
"At Supermicro, we are excited to continue our long-standing partnership with NVIDIA to bring the latest AI technology to market with the NVIDIA Blackwell Ultra Platforms," said Charles Liang, president and CEO, Supermicro. "Our Data Center Building Block Solutions approach has streamlined the development of new air and liquid-cooled systems, optimized to the thermals and internal topology of the NVIDIA HGX B300 NVL16 and GB300 NVL72. Our advanced liquid-cooling solution delivers exceptional thermal efficiency, operating with 40℃ warm water in our 8-node rack configuration, or 35℃ warm water in double-density 16-node rack configuration, leveraging our latest CDUs. This innovative solution reduces power consumption by up to 40% while conserving water resources, providing both environmental and operational cost benefits for enterprise data centers."

"At Supermicro, we are excited to continue our long-standing partnership with NVIDIA to bring the latest AI technology to market with the NVIDIA Blackwell Ultra Platforms," said Charles Liang, president and CEO, Supermicro. "Our Data Center Building Block Solutions approach has streamlined the development of new air and liquid-cooled systems, optimized to the thermals and internal topology of the NVIDIA HGX B300 NVL16 and GB300 NVL72. Our advanced liquid-cooling solution delivers exceptional thermal efficiency, operating with 40℃ warm water in our 8-node rack configuration, or 35℃ warm water in double-density 16-node rack configuration, leveraging our latest CDUs. This innovative solution reduces power consumption by up to 40% while conserving water resources, providing both environmental and operational cost benefits for enterprise data centers."



Lenovo Announces Hybrid AI Advantage with NVIDIA Blackwell Support
Today, at NVIDIA GTC, Lenovo unveiled new Lenovo Hybrid AI Advantage with NVIDIA solutions designed to accelerate AI adoption and boost business productivity by fast-tracking agentic AI that can reason, plan and take action to reach goals faster. The validated, full-stack AI solutions enable enterprises to quickly build and deploy AI agents for a broad range of high-demand use cases, increasing productivity, agility and trust while accelerating the next wave of AI reasoning for the new era of agentic AI.
New global IDC research commissioned by Lenovo reveals that ROI remains the greatest AI adoption barrier, despite a three-fold spend increase. AI agents are revolutionizing enterprise workflows and lowering barriers to ROI by supporting employees with complex problem-solving, coding, and multistep planning that drives speed, innovation and productivity. As CIOs and business leaders seek tangible return on AI investment, Lenovo is delivering hybrid AI solutions that unleash and customize agentic AI at every scale.

New global IDC research commissioned by Lenovo reveals that ROI remains the greatest AI adoption barrier, despite a three-fold spend increase. AI agents are revolutionizing enterprise workflows and lowering barriers to ROI by supporting employees with complex problem-solving, coding, and multistep planning that drives speed, innovation and productivity. As CIOs and business leaders seek tangible return on AI investment, Lenovo is delivering hybrid AI solutions that unleash and customize agentic AI at every scale.



Giga Computing Showcases Rack Scale Solutions at NVIDIA GTC 2025
Giga Computing, a subsidiary of GIGABYTE and an industry leader in generative AI servers and advanced cooling technologies, today announced participation at NVIDIA GTC 2025 to bring to the market the best in GPU-based solutions for generative AI, media acceleration, and large language models (LLM). To this end, GIGABYTE booth #1409 at NVIDIA GTC showcases a rack-scale turnkey AI solution, GIGAPOD, that offers both air and liquid-cooling designs for the NVIDIA HGX B300 NVL16 system. Also, on display at the booth is a compute node from the newly announced NVIDIA GB300 NVL72 rack-scale solution. And for modularized compute architecture are two servers supporting the newly announced NVIDIA RTX PRO 6000 Blackwell Server Edition.
Complete AI solution - GIGAPOD
With the depth of expertise in hardware and system design, Giga Computing has combined infrastructure hardware, platform software, and architecting service to deliver scalable units composed of GIGABYTE GPU servers with NVIDIA GPU baseboards, while running GIGABYTE POD Manager, a powerful software suite designed to enhance operational efficiency, streamline management, and optimize resource utilization. GIGAPOD's scalable unit is designed for either nine air-cooled racks or five liquid-cooled racks. Giga Computing offers two approaches for the same goal, one powerful GPU cluster using NVIDIA HGX Hopper and Blackwell GPU platforms at scale to meet demand for all AI data centers.



Complete AI solution - GIGAPOD
With the depth of expertise in hardware and system design, Giga Computing has combined infrastructure hardware, platform software, and architecting service to deliver scalable units composed of GIGABYTE GPU servers with NVIDIA GPU baseboards, while running GIGABYTE POD Manager, a powerful software suite designed to enhance operational efficiency, streamline management, and optimize resource utilization. GIGAPOD's scalable unit is designed for either nine air-cooled racks or five liquid-cooled racks. Giga Computing offers two approaches for the same goal, one powerful GPU cluster using NVIDIA HGX Hopper and Blackwell GPU platforms at scale to meet demand for all AI data centers.





ASUS Introduces Ascent GX10 AI Supercomputer Powered by NVIDIA GB10 Grace Blackwell Superchip
ASUS today announces its groundbreaking AI supercomputer, ASUS Ascent GX10, powered by the state-of-the-art NVIDIA GB10 Grace Blackwell Superchip. This revolutionary device places the formidable capabilities of a petaFLOP-scale AI supercomputer directly onto the desks of developers, AI researchers and data scientists around the globe.
As the size and complexity of generative AI models grow, local development efforts face increasing challenges. Prototyping, tuning and inferencing large models require substantial memory and compute performance. To address these needs, Ascent GX10 is designed to provide developers with a powerful, economical desktop solution for AI development.
As the size and complexity of generative AI models grow, local development efforts face increasing challenges. Prototyping, tuning and inferencing large models require substantial memory and compute performance. To address these needs, Ascent GX10 is designed to provide developers with a powerful, economical desktop solution for AI development.

NVIDIA to Consume 77% of Silicon Wafers Dedicated to AI Accelerators in 2025
Investment bank Morgan Stanley has estimated that an astonishing 77% of all globally produced silicon wafers dedicated to AI accelerators will be consumed by none other than NVIDIA. Often, investment research by large investment banks like Morgan Stanley includes information from the semiconductor supply chain, which is constantly expanding to meet NVIDIA's demands. When looking at wafer volume for AI accelerators, it is estimated that in 2024, NVIDIA captured nearly 51% of wafer consumption for its chips, more than half of all demand. With NVIDIA's volume projected to grow to 77%, this represents more than a 50% year-over-year increase, which is incredible for a company of NVIDIA's size. Right now, NVIDIA is phasing out its H100 accelerators in favor of Blackwell 100/200 and the upcoming 300 series of GPUs paired with Grace CPUs.
NVIDIA is accelerating its product deployment timeline and investing a lot in its internal research and development. Morgan Stanley also projects that NVIDIA will invest almost $16 billion in its R&D budget, enough to endure four to five years of development cycles running three design teams sequentially and still delivering new products on an 18-24 month cadence. The scale of this efficiency and development rivals everyone else in the industry. With all this praise, NVIDIA's Q4 revenue report is coming in exactly a week on February 26, so we have to see what its CEO, Jensen Huang, will deliver and show some estimates for the coming months.

NVIDIA is accelerating its product deployment timeline and investing a lot in its internal research and development. Morgan Stanley also projects that NVIDIA will invest almost $16 billion in its R&D budget, enough to endure four to five years of development cycles running three design teams sequentially and still delivering new products on an 18-24 month cadence. The scale of this efficiency and development rivals everyone else in the industry. With all this praise, NVIDIA's Q4 revenue report is coming in exactly a week on February 26, so we have to see what its CEO, Jensen Huang, will deliver and show some estimates for the coming months.


NVIDIA GB300 "Blackwell Ultra" Will Feature 288 GB HBM3E Memory, 1400 W TDP
NVIDIA "Blackwell" series is barely out with B100, B200, and GB200 chips shipping to OEMs and hyperscalers, but the company is already setting in its upgraded "Blackwell Ultra" plans with its upcoming GB300 AI server. According to UDN, the next generation NVIDIA system will be powered by the B300 GPU chip, operating at 1400 W and delivering a remarkable 1.5x improvement in FP4 performance per card compared to its B200 predecessor. One of the most notable upgrades is the memory configuration, with each GPU now sporting 288 GB of HBM3e memory, a substantial increase from the previous 192 GB of GB200. The new design implements a 12-layer stack architecture, advancing from the GB200's 8-layer configuration. The system's cooling infrastructure has been completely reimagined, incorporating advanced water cooling plates and enhanced quick disconnects in the liquid cooling system.
Networking capabilities have also seen a substantial upgrade, with the implementation of ConnectX 8 network cards replacing the previous ConnectX 7 generation, while optical modules have been upgraded from 800G to 1.6T, ensuring faster data transmission. Regarding power management and reliability, the GB300 NVL72 cabinet will standardize capacitor tray implementation, with an optional Battery Backup Unit (BBU) system. Each BBU module costs approximately $300 to manufacture, with a complete GB300 system's BBU configuration totaling around $1,500. The system's supercapacitor requirements are equally substantial, with each NVL72 rack requiring over 300 units, priced between $20-25 per unit during production due to its high-power nature. The GB300, carrying Grace CPU and Blackwell Ultra GPU, also introduces the implementation of LPCAMM on its computing boards, indicating that the LPCAMM memory standard is about to take over servers, not just laptops and desktops. We have to wait for the official launch before seeing LPCAMM memory configurations.
Networking capabilities have also seen a substantial upgrade, with the implementation of ConnectX 8 network cards replacing the previous ConnectX 7 generation, while optical modules have been upgraded from 800G to 1.6T, ensuring faster data transmission. Regarding power management and reliability, the GB300 NVL72 cabinet will standardize capacitor tray implementation, with an optional Battery Backup Unit (BBU) system. Each BBU module costs approximately $300 to manufacture, with a complete GB300 system's BBU configuration totaling around $1,500. The system's supercapacitor requirements are equally substantial, with each NVL72 rack requiring over 300 units, priced between $20-25 per unit during production due to its high-power nature. The GB300, carrying Grace CPU and Blackwell Ultra GPU, also introduces the implementation of LPCAMM on its computing boards, indicating that the LPCAMM memory standard is about to take over servers, not just laptops and desktops. We have to wait for the official launch before seeing LPCAMM memory configurations.

NVIDIA and Microsoft Showcase Blackwell Preview, Omniverse Industrial AI and RTX AI PCs at Microsoft Ignite
NVIDIA and Microsoft today unveiled product integrations designed to advance full-stack NVIDIA AI development on Microsoft platforms and applications. At Microsoft Ignite, Microsoft announced the launch of the first cloud private preview of the Azure ND GB200 V6 VM series, based on the NVIDIA Blackwell platform. The Azure ND GB200 v6 will be a new AI-optimized virtual machine (VM) series and combines the NVIDIA GB200 NVL72 rack design with NVIDIA Quantum InfiniBand networking.
In addition, Microsoft revealed that Azure Container Apps now supports NVIDIA GPUs, enabling simplified and scalable AI deployment. Plus, the NVIDIA AI platform on Azure includes new reference workflows for industrial AI and an NVIDIA Omniverse Blueprint for creating immersive, AI-powered visuals. At Ignite, NVIDIA also announced multimodal small language models (SLMs) for RTX AI PCs and workstations, enhancing digital human interactions and virtual assistants with greater realism.
In addition, Microsoft revealed that Azure Container Apps now supports NVIDIA GPUs, enabling simplified and scalable AI deployment. Plus, the NVIDIA AI platform on Azure includes new reference workflows for industrial AI and an NVIDIA Omniverse Blueprint for creating immersive, AI-powered visuals. At Ignite, NVIDIA also announced multimodal small language models (SLMs) for RTX AI PCs and workstations, enhancing digital human interactions and virtual assistants with greater realism.

GIGABYTE Showcases a Leading AI and Enterprise Portfolio at Supercomputing 2024
Giga Computing, a subsidiary of GIGABYTE and an industry leader in generative AI servers and advanced cooling technologies, shows off at SC24 how the GIGABYTE enterprise portfolio provides solutions for all applications, from cloud computing to AI to enterprise IT, including energy-efficient liquid-cooling technologies. This portfolio is made more complete by long-term collaborations with leading technology companies and emerging industry leaders, which will be showcased at GIGABYTE booth #3123 at SC24 (Nov. 19-21) in Atlanta. The booth is sectioned to put the spotlight on strategic technology collaborations, as well as direct liquid cooling partners.
The GIGABYTE booth will showcase an array of NVIDIA platforms built to keep up with the diversity of workloads and degrees of demands in applications of AI & HPC hardware. For a rack-scale AI solution using the NVIDIA GB200 NVL72 design, GIGABYTE displays how seventy-two GPUs can be in one rack with eighteen GIGABYTE servers each housing two NVIDIA Grace CPUs and four NVIDIA Blackwell GPUs. Another platform at the GIGABYTE booth is the NVIDIA HGX H200 platform. GIGABYTE exhibits both its liquid-cooling G4L3-SD1 server and an air-cooled version, G593-SD1.
The GIGABYTE booth will showcase an array of NVIDIA platforms built to keep up with the diversity of workloads and degrees of demands in applications of AI & HPC hardware. For a rack-scale AI solution using the NVIDIA GB200 NVL72 design, GIGABYTE displays how seventy-two GPUs can be in one rack with eighteen GIGABYTE servers each housing two NVIDIA Grace CPUs and four NVIDIA Blackwell GPUs. Another platform at the GIGABYTE booth is the NVIDIA HGX H200 platform. GIGABYTE exhibits both its liquid-cooling G4L3-SD1 server and an air-cooled version, G593-SD1.

New Arm CPUs from NVIDIA Coming in 2025
According to DigiTimes, NVIDIA is reportedly targeting the high-end segment for its first consumer CPU attempt. Slated to arrive in 2025, NVIDIA is partnering with MediaTek to break into the AI PC market, currently being popularized by Qualcomm, Intel, and AMD. With Microsoft and Qualcomm laying the foundation for Windows-on-Arm (WoA) development, NVIDIA plans to join and leverage its massive ecosystem of partners to design and deliver regular applications and games for its Arm-based processors. At the same time, NVIDIA is also scheduled to launch "Blackwell" GPUs for consumers, which could end up in these AI PCs with an Arm CPU at its core.
NVIDIA's partner, MediaTek, has recently launched a big core SoC for mobile called Dimensity 9400. NVIDIA could use something like that as a base for its SoC and add its Blackwell IP to the mix. This would be similar to what Apple is doing with its Apple Silicon and the recent M4 Max chip, which is apparently the fastest CPU in single-threaded and multithreaded workloads, as per recent Geekbench recordings. For NVIDIA, the company already has a team of CPU designers that delivered its Grace CPU to enterprise/server customers. Using off-the-shelf Arm Neoverse IP, the company's customers are acquiring systems with Grace CPUs as fast as they are produced. This puts a lot of hope into NVIDIA's upcoming AI PC, which could offer a selling point no other WoA device currently provides, and that is tried and tested gaming-grade GPU with AI accelerators.
NVIDIA's partner, MediaTek, has recently launched a big core SoC for mobile called Dimensity 9400. NVIDIA could use something like that as a base for its SoC and add its Blackwell IP to the mix. This would be similar to what Apple is doing with its Apple Silicon and the recent M4 Max chip, which is apparently the fastest CPU in single-threaded and multithreaded workloads, as per recent Geekbench recordings. For NVIDIA, the company already has a team of CPU designers that delivered its Grace CPU to enterprise/server customers. Using off-the-shelf Arm Neoverse IP, the company's customers are acquiring systems with Grace CPUs as fast as they are produced. This puts a lot of hope into NVIDIA's upcoming AI PC, which could offer a selling point no other WoA device currently provides, and that is tried and tested gaming-grade GPU with AI accelerators.

Meta Shows Open-Architecture NVIDIA "Blackwell" GB200 System for Data Center
During the Open Compute Project (OCP) Summit 2024, Meta, one of the prime members of the OCP project, showed its NVIDIA "Blackwell" GB200 systems for its massive data centers. We previously covered Microsoft's Azure server rack with GB200 GPUs featuring one-third of the rack space for computing and two-thirds for cooling. A few days later, Google showed off its smaller GB200 system, and today, Meta is showing off its GB200 system—the smallest of the bunch. To train a dense transformer large language model with 405B parameters and a context window of up to 128k tokens, like the Llama 3.1 405B, Meta must redesign its data center infrastructure to run a distributed training job on two 24,000 GPU clusters. That is 48,000 GPUs used for training a single AI model.
Called "Catalina," it is built on the NVIDIA Blackwell platform, emphasizing modularity and adaptability while incorporating the latest NVIDIA GB200 Grace Blackwell Superchip. To address the escalating power requirements of GPUs, Catalina introduces the Orv3, a high-power rack capable of delivering up to 140kW. The comprehensive liquid-cooled setup encompasses a power shelf supporting various components, including a compute tray, switch tray, the Orv3 HPR, Wedge 400 fabric switch with 12.8 Tbps switching capacity, management switch, battery backup, and a rack management controller. Interestingly, Meta also upgraded its "Grand Teton" system for internal usage, such as deep learning recommendation models (DLRMs) and content understanding with AMD Instinct MI300X. Those are used to inference internal models, and MI300X appears to provide the best performance per Dollar for inference. According to Meta, the computational demand stemming from AI will continue to increase exponentially, so more NVIDIA and AMD GPUs is needed, and we can't wait to see what the company builds.

Called "Catalina," it is built on the NVIDIA Blackwell platform, emphasizing modularity and adaptability while incorporating the latest NVIDIA GB200 Grace Blackwell Superchip. To address the escalating power requirements of GPUs, Catalina introduces the Orv3, a high-power rack capable of delivering up to 140kW. The comprehensive liquid-cooled setup encompasses a power shelf supporting various components, including a compute tray, switch tray, the Orv3 HPR, Wedge 400 fabric switch with 12.8 Tbps switching capacity, management switch, battery backup, and a rack management controller. Interestingly, Meta also upgraded its "Grand Teton" system for internal usage, such as deep learning recommendation models (DLRMs) and content understanding with AMD Instinct MI300X. Those are used to inference internal models, and MI300X appears to provide the best performance per Dollar for inference. According to Meta, the computational demand stemming from AI will continue to increase exponentially, so more NVIDIA and AMD GPUs is needed, and we can't wait to see what the company builds.


NVIDIA Contributes Blackwell Platform Design to Open Hardware Ecosystem, Accelerating AI Infrastructure Innovation
To drive the development of open, efficient and scalable data center technologies, NVIDIA today announced that it has contributed foundational elements of its NVIDIA Blackwell accelerated computing platform design to the Open Compute Project (OCP) and broadened NVIDIA Spectrum-X support for OCP standards.
At this year's OCP Global Summit, NVIDIA will be sharing key portions of the NVIDIA GB200 NVL72 system electro-mechanical design with the OCP community — including the rack architecture, compute and switch tray mechanicals, liquid-cooling and thermal environment specifications, and NVIDIA NVLink cable cartridge volumetrics — to support higher compute density and networking bandwidth.
At this year's OCP Global Summit, NVIDIA will be sharing key portions of the NVIDIA GB200 NVL72 system electro-mechanical design with the OCP community — including the rack architecture, compute and switch tray mechanicals, liquid-cooling and thermal environment specifications, and NVIDIA NVLink cable cartridge volumetrics — to support higher compute density and networking bandwidth.


Foxconn to Build Taiwan's Fastest AI Supercomputer With NVIDIA Blackwell
NVIDIA and Foxconn are building Taiwan's largest supercomputer, marking a milestone in the island's AI advancement. The project, Hon Hai Kaohsiung Super Computing Center, revealed Tuesday at Hon Hai Tech Day, will be built around NVIDIA's groundbreaking Blackwell architecture and feature the GB200 NVL72 platform, which includes a total of 64 racks and 4,608 Tensor Core GPUs. With an expected performance of over 90 exaflops of AI performance, the machine would easily be considered the fastest in Taiwan.
Foxconn plans to use the supercomputer, once operational, to power breakthroughs in cancer research, large language model development and smart city innovations, positioning Taiwan as a global leader in AI-driven industries. Foxconn's "three-platform strategy" focuses on smart manufacturing, smart cities and electric vehicles. The new supercomputer will play a pivotal role in supporting Foxconn's ongoing efforts in digital twins, robotic automation and smart urban infrastructure, bringing AI-assisted services to urban areas like Kaohsiung.



Foxconn plans to use the supercomputer, once operational, to power breakthroughs in cancer research, large language model development and smart city innovations, positioning Taiwan as a global leader in AI-driven industries. Foxconn's "three-platform strategy" focuses on smart manufacturing, smart cities and electric vehicles. The new supercomputer will play a pivotal role in supporting Foxconn's ongoing efforts in digital twins, robotic automation and smart urban infrastructure, bringing AI-assisted services to urban areas like Kaohsiung.




NVIDIA Cancels Dual-Rack NVL36x2 in Favor of Single-Rack NVL72 Compute Monster
NVIDIA has reportedly discontinued its dual-rack GB200 NVL36x2 GPU model, opting to focus on the single-rack GB200 NVL72 and NVL36 models. This shift, revealed by industry analyst Ming-Chi Kuo, aims to simplify NVIDIA's offerings in the AI and HPC markets. The decision was influenced by major clients like Microsoft, who prefer the NVL72's improved space efficiency and potential for enhanced inference performance. While both models perform similarly in AI large language model (LLM) training, the NVL72 is expected to excel in non-parallelizable inference tasks. As a reminder, the NVL72 features 36 Grace CPUs, delivering 2,592 Arm Neoverse V2 cores with 17 TB LPDDR5X memory with 18.4 TB/s aggregate bandwidth. Additionally, it includes 72 Blackwell GB200 SXM GPUs that have a massive 13.5 TB of HBM3e combined, running at 576 TB/s aggregate bandwidth.
However, this shift presents significant challenges. The NVL72's power consumption of around 120kW far exceeds typical data center capabilities, potentially limiting its immediate widespread adoption. The discontinuation of the NVL36x2 has also sparked concerns about NVIDIA's execution capabilities and may disrupt the supply chain for assembly and cooling solutions. Despite these hurdles, industry experts view this as a pragmatic approach to product planning in the dynamic AI landscape. While some customers may be disappointed by the dual-rack model's cancellation, NVIDIA's long-term outlook in the AI technology market remains strong. The company continues to work with clients and listen to their needs, to position itself as a leader in high-performance computing solutions.
However, this shift presents significant challenges. The NVL72's power consumption of around 120kW far exceeds typical data center capabilities, potentially limiting its immediate widespread adoption. The discontinuation of the NVL36x2 has also sparked concerns about NVIDIA's execution capabilities and may disrupt the supply chain for assembly and cooling solutions. Despite these hurdles, industry experts view this as a pragmatic approach to product planning in the dynamic AI landscape. While some customers may be disappointed by the dual-rack model's cancellation, NVIDIA's long-term outlook in the AI technology market remains strong. The company continues to work with clients and listen to their needs, to position itself as a leader in high-performance computing solutions.

ASUS Presents Comprehensive AI Server Lineup
ASUS today announced its ambitious All in AI initiative, marking a significant leap into the server market with a complete AI infrastructure solution, designed to meet the evolving demands of AI-driven applications from edge, inference and generative AI the new, unparalleled wave of AI supercomputing. ASUS has proven its expertise lies in striking the perfect balance between hardware and software, including infrastructure and cluster architecture design, server installation, testing, onboarding, remote management and cloud services - positioning the ASUS brand and AI server solutions to lead the way in driving innovation and enabling the widespread adoption of AI across industries.
Meeting diverse AI needs
In partnership with NVIDIA, Intel and AMD, ASUS offer comprehensive AI-infrastructure solutions with robust software platforms and services, from entry-level AI servers and machine-learning solutions to full racks and data centers for large-scale supercomputing. At the forefront is the ESC AI POD with NVIDIA GB200 NVL72, a cutting-edge rack designed to accelerate trillion-token LLM training and real-time inference operations. Complemented by the latest NVIDIA Blackwell GPUs, NVIDIA Grace CPUs and 5th Gen NVIDIA NVLink technology, ASUS servers ensure unparalleled computing power and efficiency.



Meeting diverse AI needs
In partnership with NVIDIA, Intel and AMD, ASUS offer comprehensive AI-infrastructure solutions with robust software platforms and services, from entry-level AI servers and machine-learning solutions to full racks and data centers for large-scale supercomputing. At the forefront is the ESC AI POD with NVIDIA GB200 NVL72, a cutting-edge rack designed to accelerate trillion-token LLM training and real-time inference operations. Complemented by the latest NVIDIA Blackwell GPUs, NVIDIA Grace CPUs and 5th Gen NVIDIA NVLink technology, ASUS servers ensure unparalleled computing power and efficiency.




NVIDIA Shifts Gears: Open-Source Linux GPU Drivers Take Center Stage
Just a few months after hiring Ben Skeggs, a lead maintainer of the open-source NVIDIA GPU driver for Linux kernel, NVIDIA has announced a complete transition to open-source GPU kernel modules in its upcoming R560 driver release for Linux. This decision comes two years after the company's initial foray into open-source territory with the R515 driver in May 2022. The tech giant began focusing on data center compute GPUs, while GeForce and Workstation GPU support remained in the alpha stages. Now, after extensive development and optimization, NVIDIA reports that its open-source modules have achieved performance parity with, and in some cases surpassed, their closed-source counterparts. This transition brings a host of new capabilities, including heterogeneous memory management support, confidential computing features, and compatibility with NVIDIA's Grace platform's coherent memory architectures.
The move to open-source is expected to foster greater collaboration within the Linux ecosystem and potentially lead to faster bug fixes and feature improvements. However, not all GPUs will be compatible with the new open-source modules. While cutting-edge platforms like NVIDIA Grace Hopper and Blackwell will require open-source drivers, older GPUs from the Maxwell, Pascal, or Volta architectures must stick with proprietary drivers. NVIDIA has developed a detection helper script to guide driver selection for users who are unsure about compatibility. The shift also brings changes to NVIDIA's installation processes. The default driver version for most installation methods will now be the open-source variant. This affects package managers with the CUDA meta package, run file installations and even Windows Subsystem for Linux.
The move to open-source is expected to foster greater collaboration within the Linux ecosystem and potentially lead to faster bug fixes and feature improvements. However, not all GPUs will be compatible with the new open-source modules. While cutting-edge platforms like NVIDIA Grace Hopper and Blackwell will require open-source drivers, older GPUs from the Maxwell, Pascal, or Volta architectures must stick with proprietary drivers. NVIDIA has developed a detection helper script to guide driver selection for users who are unsure about compatibility. The shift also brings changes to NVIDIA's installation processes. The default driver version for most installation methods will now be the open-source variant. This affects package managers with the CUDA meta package, run file installations and even Windows Subsystem for Linux.

Qualcomm's Success with Windows AI PC Drawing NVIDIA Back to the Client SoC Business
NVIDIA is eying a comeback to the client processor business, reveals a Bloomberg interview with the CEOs of NVIDIA and Dell. For NVIDIA, all it takes is a simple driver update that exposes every GeForce GPU with tensor cores as an NPU to Windows 11, with translation layers to get popular client AI apps to work with TensorRT. But that would need you to have a discrete NVIDIA GPU. What about the vast market of Windows AI PCs powered by the likes of Qualcomm, Intel, and AMD, who each sell 15 W-class processors with integrated NPUs capable of 50 AI TOPS, which is all that Copilot+ needs? NVIDIA held an Arm license for decades now, and makes Arm-based CPUs to this day, with the NVIDIA Grace, however, that is a large server processor meant for its AI GPU servers.
NVIDIA already made client processors under the Tegra brand targeting smartphones, which it winded down last decade. It's since been making Drive PX processors for its automotive self-driving hardware division; and of course there's Grace. NVIDIA hinted that it might have a client CPU for the AI PC market in 2025. In the interview Bloomberg asked NVIDIA CEO Jensen Huang a pointed question on whether NVIDIA has a place in the AI PC market. Dell CEO Michael Dell, who was also in the interview, interjected "come back next year," to which Jensen affirmed "exactly." Dell would be in a front-and-center position to know if NVIDIA is working on a new PC processor for launch in 2025, and Jensen's nod almost confirms this
NVIDIA already made client processors under the Tegra brand targeting smartphones, which it winded down last decade. It's since been making Drive PX processors for its automotive self-driving hardware division; and of course there's Grace. NVIDIA hinted that it might have a client CPU for the AI PC market in 2025. In the interview Bloomberg asked NVIDIA CEO Jensen Huang a pointed question on whether NVIDIA has a place in the AI PC market. Dell CEO Michael Dell, who was also in the interview, interjected "come back next year," to which Jensen affirmed "exactly." Dell would be in a front-and-center position to know if NVIDIA is working on a new PC processor for launch in 2025, and Jensen's nod almost confirms this

TOP500: Frontier Keeps Top Spot, Aurora Officially Becomes the Second Exascale Machine
The 63rd edition of the TOP500 reveals that Frontier has once again claimed the top spot, despite no longer being the only exascale machine on the list. Additionally, a new system has found its way into the Top 10.
The Frontier system at Oak Ridge National Laboratory in Tennessee, USA remains the most powerful system on the list with an HPL score of 1.206 EFlop/s. The system has a total of 8,699,904 combined CPU and GPU cores, an HPE Cray EX architecture that combines 3rd Gen AMD EPYC CPUs optimized for HPC and AI with AMD Instinct MI250X accelerators, and it relies on Cray's Slingshot 11 network for data transfer. On top of that, this machine has an impressive power efficiency rating of 52.93 GFlops/Watt - putting Frontier at the No. 13 spot on the GREEN500.
The Frontier system at Oak Ridge National Laboratory in Tennessee, USA remains the most powerful system on the list with an HPL score of 1.206 EFlop/s. The system has a total of 8,699,904 combined CPU and GPU cores, an HPE Cray EX architecture that combines 3rd Gen AMD EPYC CPUs optimized for HPC and AI with AMD Instinct MI250X accelerators, and it relies on Cray's Slingshot 11 network for data transfer. On top of that, this machine has an impressive power efficiency rating of 52.93 GFlops/Watt - putting Frontier at the No. 13 spot on the GREEN500.

NVIDIA Blackwell Platform Pushes the Boundaries of Scientific Computing
Quantum computing. Drug discovery. Fusion energy. Scientific computing and physics-based simulations are poised to make giant steps across domains that benefit humanity as advances in accelerated computing and AI drive the world's next big breakthroughs. NVIDIA unveiled at GTC in March the NVIDIA Blackwell platform, which promises generative AI on trillion-parameter large language models (LLMs) at up to 25x less cost and energy consumption than the NVIDIA Hopper architecture.
Blackwell has powerful implications for AI workloads, and its technology capabilities can also help to deliver discoveries across all types of scientific computing applications, including traditional numerical simulation. By reducing energy costs, accelerated computing and AI drive sustainable computing. Many scientific computing applications already benefit. Weather can be simulated at 200x lower cost and with 300x less energy, while digital twin simulations have 65x lower cost and 58x less energy consumption versus traditional CPU-based systems and others.



Blackwell has powerful implications for AI workloads, and its technology capabilities can also help to deliver discoveries across all types of scientific computing applications, including traditional numerical simulation. By reducing energy costs, accelerated computing and AI drive sustainable computing. Many scientific computing applications already benefit. Weather can be simulated at 200x lower cost and with 300x less energy, while digital twin simulations have 65x lower cost and 58x less energy consumption versus traditional CPU-based systems and others.

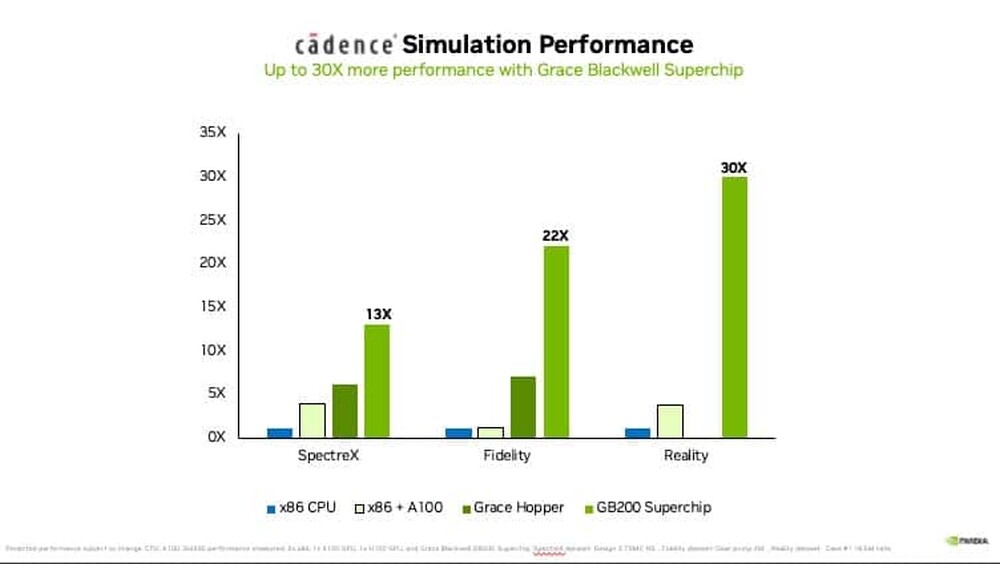

NVIDIA Grace Hopper Ignites New Era of AI Supercomputing
Driving a fundamental shift in the high-performance computing industry toward AI-powered systems, NVIDIA today announced nine new supercomputers worldwide are using NVIDIA Grace Hopper Superchips to speed scientific research and discovery. Combined, the systems deliver 200 exaflops, or 200 quintillion calculations per second, of energy-efficient AI processing power.
New Grace Hopper-based supercomputers coming online include EXA1-HE, in France, from CEA and Eviden; Helios at Academic Computer Centre Cyfronet, in Poland, from Hewlett Packard Enterprise (HPE); Alps at the Swiss National Supercomputing Centre, from HPE; JUPITER at the Jülich Supercomputing Centre, in Germany; DeltaAI at the National Center for Supercomputing Applications at the University of Illinois Urbana-Champaign; and Miyabi at Japan's Joint Center for Advanced High Performance Computing - established between the Center for Computational Sciences at the University of Tsukuba and the Information Technology Center at the University of Tokyo.
New Grace Hopper-based supercomputers coming online include EXA1-HE, in France, from CEA and Eviden; Helios at Academic Computer Centre Cyfronet, in Poland, from Hewlett Packard Enterprise (HPE); Alps at the Swiss National Supercomputing Centre, from HPE; JUPITER at the Jülich Supercomputing Centre, in Germany; DeltaAI at the National Center for Supercomputing Applications at the University of Illinois Urbana-Champaign; and Miyabi at Japan's Joint Center for Advanced High Performance Computing - established between the Center for Computational Sciences at the University of Tsukuba and the Information Technology Center at the University of Tokyo.

NVIDIA Accelerates Quantum Computing Centers Worldwide With CUDA-Q Platform
NVIDIA today announced that it will accelerate quantum computing efforts at national supercomputing centers around the world with the open-source NVIDIA CUDA-Q platform. Supercomputing sites in Germany, Japan and Poland will use the platform to power the quantum processing units (QPUs) inside their NVIDIA-accelerated high-performance computing systems.
QPUs are the brains of quantum computers that use the behavior of particles like electrons or photons to calculate differently than traditional processors, with the potential to make certain types of calculations faster. Germany's Jülich Supercomputing Centre (JSC) at Forschungszentrum Jülich is installing a QPU built by IQM Quantum Computers as a complement to its JUPITER supercomputer, supercharged by the NVIDIA GH200 Grace Hopper Superchip. The ABCI-Q supercomputer, located at the National Institute of Advanced Industrial Science and Technology (AIST) in Japan, is designed to advance the nation's quantum computing initiative. Powered by the NVIDIA Hopper architecture, the system will add a QPU from QuEra. Poland's Poznan Supercomputing and Networking Center (PSNC) has recently installed two photonic QPUs, built by ORCA Computing, connected to a new supercomputer partition accelerated by NVIDIA Hopper.
QPUs are the brains of quantum computers that use the behavior of particles like electrons or photons to calculate differently than traditional processors, with the potential to make certain types of calculations faster. Germany's Jülich Supercomputing Centre (JSC) at Forschungszentrum Jülich is installing a QPU built by IQM Quantum Computers as a complement to its JUPITER supercomputer, supercharged by the NVIDIA GH200 Grace Hopper Superchip. The ABCI-Q supercomputer, located at the National Institute of Advanced Industrial Science and Technology (AIST) in Japan, is designed to advance the nation's quantum computing initiative. Powered by the NVIDIA Hopper architecture, the system will add a QPU from QuEra. Poland's Poznan Supercomputing and Networking Center (PSNC) has recently installed two photonic QPUs, built by ORCA Computing, connected to a new supercomputer partition accelerated by NVIDIA Hopper.

AWS and NVIDIA Extend Collaboration to Advance Generative AI Innovation
Amazon Web Services (AWS), an Amazon.com company, and NVIDIA today announced that the new NVIDIA Blackwell GPU platform - unveiled by NVIDIA at GTC 2024 - is coming to AWS. AWS will offer the NVIDIA GB200 Grace Blackwell Superchip and B100 Tensor Core GPUs, extending the companies' long standing strategic collaboration to deliver the most secure and advanced infrastructure, software, and services to help customers unlock new generative artificial intelligence (AI) capabilities.
NVIDIA and AWS continue to bring together the best of their technologies, including NVIDIA's newest multi-node systems featuring the next-generation NVIDIA Blackwell platform and AI software, AWS's Nitro System and AWS Key Management Service (AWS KMS) advanced security, Elastic Fabric Adapter (EFA) petabit scale networking, and Amazon Elastic Compute Cloud (Amazon EC2) UltraCluster hyper-scale clustering. Together, they deliver the infrastructure and tools that enable customers to build and run real-time inference on multi-trillion parameter large language models (LLMs) faster, at massive scale, and at a lower cost than previous-generation NVIDIA GPUs on Amazon EC2.
NVIDIA and AWS continue to bring together the best of their technologies, including NVIDIA's newest multi-node systems featuring the next-generation NVIDIA Blackwell platform and AI software, AWS's Nitro System and AWS Key Management Service (AWS KMS) advanced security, Elastic Fabric Adapter (EFA) petabit scale networking, and Amazon Elastic Compute Cloud (Amazon EC2) UltraCluster hyper-scale clustering. Together, they deliver the infrastructure and tools that enable customers to build and run real-time inference on multi-trillion parameter large language models (LLMs) faster, at massive scale, and at a lower cost than previous-generation NVIDIA GPUs on Amazon EC2.

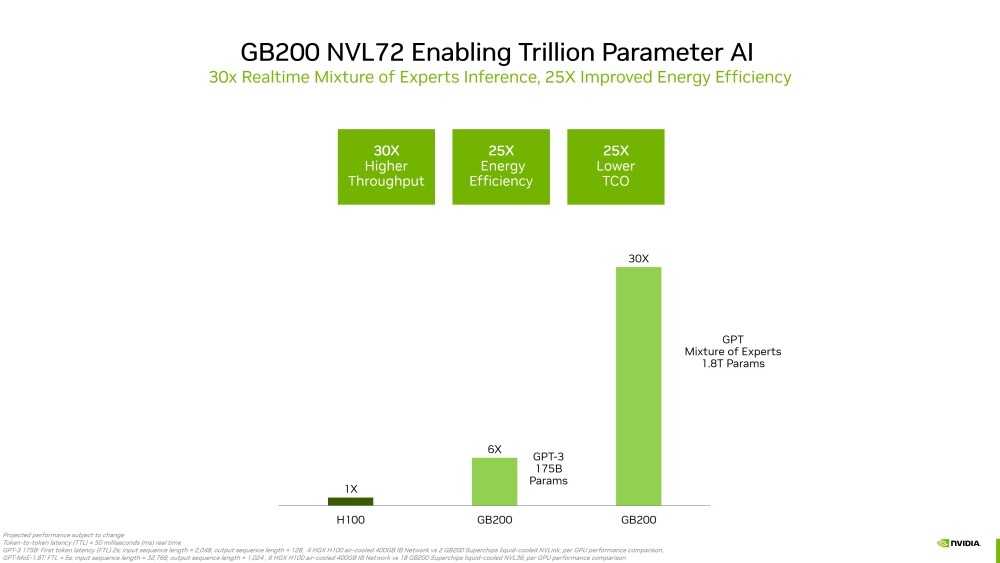
NVIDIA Launches Blackwell-Powered DGX SuperPOD for Generative AI Supercomputing at Trillion-Parameter Scale
NVIDIA today announced its next-generation AI supercomputer—the NVIDIA DGX SuperPOD powered by NVIDIA GB200 Grace Blackwell Superchips—for processing trillion-parameter models with constant uptime for superscale generative AI training and inference workloads.
Featuring a new, highly efficient, liquid-cooled rack-scale architecture, the new DGX SuperPOD is built with NVIDIA DGX GB200 systems and provides 11.5 exaflops of AI supercomputing at FP4 precision and 240 terabytes of fast memory—scaling to more with additional racks.
Featuring a new, highly efficient, liquid-cooled rack-scale architecture, the new DGX SuperPOD is built with NVIDIA DGX GB200 systems and provides 11.5 exaflops of AI supercomputing at FP4 precision and 240 terabytes of fast memory—scaling to more with additional racks.

Apr 18th, 2025 16:09 EDT
change timezone
Latest GPU Drivers
New Forum Posts
- How to relubricate a fan and/or service a troublesome/noisy fan. (242)
- It's happening again, melting 12v high pwr connectors (1027)
- RX 9000 series GPU Owners Club (393)
- Can Intel recover in DYI market anytime soon? (11)
- Place your bets, what node will rtx 6000/RDNA 5(UDNA 1?) use (8)
- TPU's Nostalgic Hardware Club (20257)
- GPU Pricing and Performance (15)
- What are you playing? (23396)
- Spoofer Modified SMBIOS/BIOS – Need Help Restoring Original Motherboard Info (TUF GAMING B550-PLUS WiFi II) (2)
- Tried installing 576.02 - installer window disappears (20)
Popular Reviews
- ASUS GeForce RTX 5060 Ti TUF OC 16 GB Review
- NVIDIA GeForce RTX 5060 Ti PCI-Express x8 Scaling
- Palit GeForce RTX 5060 Ti Infinity 3 16 GB Review
- G.SKILL Trident Z5 NEO RGB DDR5-6000 32 GB CL26 Review - AMD EXPO
- ASUS GeForce RTX 5060 Ti Prime OC 16 GB Review
- Teevolution Terra Pro Review
- MSI GeForce RTX 5060 Ti Gaming OC 16 GB Review
- Zotac GeForce RTX 5060 Ti AMP 16 GB Review
- MSI GeForce RTX 5060 Ti Gaming Trio OC 16 GB Review
- ASUS GeForce RTX 5080 TUF OC Review
Controversial News Posts
- NVIDIA GeForce RTX 5060 Ti 16 GB SKU Likely Launching at $499, According to Supply Chain Leak (182)
- NVIDIA Sends MSRP Numbers to Partners: GeForce RTX 5060 Ti 8 GB at $379, RTX 5060 Ti 16 GB at $429 (127)
- Nintendo Confirms That Switch 2 Joy-Cons Will Not Utilize Hall Effect Stick Technology (105)
- NVIDIA Launches GeForce RTX 5060 Series, Beginning with RTX 5060 Ti This Week (101)
- Over 200,000 Sold Radeon RX 9070 and RX 9070 XT GPUs? AMD Says No Number was Given (100)
- Nintendo Switch 2 Launches June 5 at $449.99 with New Hardware and Games (99)
- Sony Increases the PS5 Pricing in EMEA and ANZ by Around 25 Percent (85)
- NVIDIA PhysX and Flow Made Fully Open-Source (77)