Apr 24th, 2025 13:51 EDT
change timezone
Latest GPU Drivers
New Forum Posts
- Choosing an Internal HDD (2)
- New GPU 5070 Ti or better CPU Ryzen7 7800X3D ? (18)
- Companies should be called out for this (91)
- Are the 8 GB cards worth it? (160)
- To distill or not distill what say ye? (99)
- Do you use Linux? (592)
- I dont understand the phone OS world..... (32)
- 5060 Ti 8GB DOA (265)
- Thermal testing two different size Gigabyte 5070 Ti cards - huge differences (28)
- Asus Rx570 o4g cannot losd drivers error code 43 (15)
Popular Reviews
- NVIDIA GeForce RTX 5060 Ti 8 GB Review - So Many Compromises
- Colorful iGame B860M Ultra V20 Review
- ASUS GeForce RTX 5060 Ti TUF OC 16 GB Review
- ASRock X870E Taichi Lite Review
- Upcoming Hardware Launches 2025 (Updated Apr 2025)
- Sapphire Radeon RX 9070 XT Pulse Review
- Sapphire Radeon RX 9070 XT Nitro+ Review - Beating NVIDIA
- Crucial CUDIMM DDR5-6400 128 GB CL52 Review
- AMD Ryzen 7 9800X3D Review - The Best Gaming Processor
- NVIDIA GeForce RTX 5060 Ti PCI-Express x8 Scaling
Controversial News Posts
- NVIDIA GeForce RTX 5060 Ti 16 GB SKU Likely Launching at $499, According to Supply Chain Leak (182)
- NVIDIA Sends MSRP Numbers to Partners: GeForce RTX 5060 Ti 8 GB at $379, RTX 5060 Ti 16 GB at $429 (127)
- NVIDIA Launches GeForce RTX 5060 Series, Beginning with RTX 5060 Ti This Week (115)
- Nintendo Confirms That Switch 2 Joy-Cons Will Not Utilize Hall Effect Stick Technology (105)
- Nintendo Switch 2 Launches June 5 at $449.99 with New Hardware and Games (99)
- Sony Increases the PS5 Pricing in EMEA and ANZ by Around 25 Percent (85)
- NVIDIA PhysX and Flow Made Fully Open-Source (77)
- Windows Notepad Gets Microsoft Copilot Integration (75)
News Posts matching #ROCm
Return to Keyword Browsing
AMD Instinct MI300X GPUs Featured in LaminiAI LLM Pods
LaminiAI appears to be one of AMD's first customers to receive a bulk order of Instinct MI300X GPUs—late last week, Sharon Zhou (CEO and co-founder) posted about the "next batch of LaminiAI LLM Pods" up and running with Team Red's cutting-edge CDNA 3 series accelerators inside. Her short post on social media stated: "rocm-smi...like freshly baked bread, 8x MI300X is online—if you're building on open LLMs and you're blocked on compute, lmk. Everyone should have access to this wizard technology called LLMs."
An attached screenshot of a ROCm System Management Interface (ROCm SMI) session showcases an individual Pod configuration sporting eight Instinct MI300X GPUs. According to official blog entries, LaminiAI has utilized bog-standard MI300 accelerators since 2023, so it is not surprising to see their partnership continue to grow with AMD. Industry predictions have the Instinct MI300X and MI300A models placed as great alternatives to NVIDIA's dominant H100 "Hopper" series—AMD stock is climbing due to encouraging financial analyst estimations.



An attached screenshot of a ROCm System Management Interface (ROCm SMI) session showcases an individual Pod configuration sporting eight Instinct MI300X GPUs. According to official blog entries, LaminiAI has utilized bog-standard MI300 accelerators since 2023, so it is not surprising to see their partnership continue to grow with AMD. Industry predictions have the Instinct MI300X and MI300A models placed as great alternatives to NVIDIA's dominant H100 "Hopper" series—AMD stock is climbing due to encouraging financial analyst estimations.





Dell Generative AI Open Ecosystem with AMD Instinct Accelerators
Generative AI (GenAI) is the decade's most promising accelerator for innovation with 78% of IT decision makers reporting they're largely excited for the potential GenAI can have on their organizations.¹ Most see GenAI as a means to provide productivity gains, streamline processes and achieve cost savings. Harnessing this technology is critical to ensure organizations can compete in this new digital era.
Dell Technologies and AMD are coming together to unveil an expansion to the Dell Generative AI Solutions portfolio, continuing the work of accelerating advanced workloads and offering businesses more choice to continue their unique GenAI journeys. This new technology highlights a pivotal role played by open ecosystems and silicon diversity in empowering customers with simple, trusted and tailored solutions to bring AI to their data.


Dell Technologies and AMD are coming together to unveil an expansion to the Dell Generative AI Solutions portfolio, continuing the work of accelerating advanced workloads and offering businesses more choice to continue their unique GenAI journeys. This new technology highlights a pivotal role played by open ecosystems and silicon diversity in empowering customers with simple, trusted and tailored solutions to bring AI to their data.



AMD Showcases Growing Momentum for AMD Powered AI Solutions from the Data Center to PCs
Today at the "Advancing AI" event, AMD was joined by industry leaders including Microsoft, Meta, Oracle, Dell Technologies, HPE, Lenovo, Supermicro, Arista, Broadcom and Cisco to showcase how these companies are working with AMD to deliver advanced AI solutions spanning from cloud to enterprise and PCs. AMD launched multiple new products at the event, including the AMD Instinct MI300 Series data center AI accelerators, ROCm 6 open software stack with significant optimizations and new features supporting Large Language Models (LLMs) and Ryzen 8040 Series processors with Ryzen AI.
"AI is the future of computing and AMD is uniquely positioned to power the end-to-end infrastructure that will define this AI era, from massive cloud installations to enterprise clusters and AI-enabled intelligent embedded devices and PCs," said AMD Chair and CEO Dr. Lisa Su. "We are seeing very strong demand for our new Instinct MI300 GPUs, which are the highest-performance accelerators in the world for generative AI. We are also building significant momentum for our data center AI solutions with the largest cloud companies, the industry's top server providers, and the most innovative AI startups ꟷ who we are working closely with to rapidly bring Instinct MI300 solutions to market that will dramatically accelerate the pace of innovation across the entire AI ecosystem."
"AI is the future of computing and AMD is uniquely positioned to power the end-to-end infrastructure that will define this AI era, from massive cloud installations to enterprise clusters and AI-enabled intelligent embedded devices and PCs," said AMD Chair and CEO Dr. Lisa Su. "We are seeing very strong demand for our new Instinct MI300 GPUs, which are the highest-performance accelerators in the world for generative AI. We are also building significant momentum for our data center AI solutions with the largest cloud companies, the industry's top server providers, and the most innovative AI startups ꟷ who we are working closely with to rapidly bring Instinct MI300 solutions to market that will dramatically accelerate the pace of innovation across the entire AI ecosystem."

AMD Delivers Leadership Portfolio of Data Center AI Solutions with AMD Instinct MI300 Series
Today, AMD announced the availability of the AMD Instinct MI300X accelerators - with industry leading memory bandwidth for generative AI and leadership performance for large language model (LLM) training and inferencing - as well as the AMD Instinct MI300A accelerated processing unit (APU) - combining the latest AMD CDNA 3 architecture and "Zen 4" CPUs to deliver breakthrough performance for HPC and AI workloads.
"AMD Instinct MI300 Series accelerators are designed with our most advanced technologies, delivering leadership performance, and will be in large scale cloud and enterprise deployments," said Victor Peng, president, AMD. "By leveraging our leadership hardware, software and open ecosystem approach, cloud providers, OEMs and ODMs are bringing to market technologies that empower enterprises to adopt and deploy AI-powered solutions."
"AMD Instinct MI300 Series accelerators are designed with our most advanced technologies, delivering leadership performance, and will be in large scale cloud and enterprise deployments," said Victor Peng, president, AMD. "By leveraging our leadership hardware, software and open ecosystem approach, cloud providers, OEMs and ODMs are bringing to market technologies that empower enterprises to adopt and deploy AI-powered solutions."


AMD Radeon "GFX12" RX 8000 Series GPUs Based on RDNA4 Appear
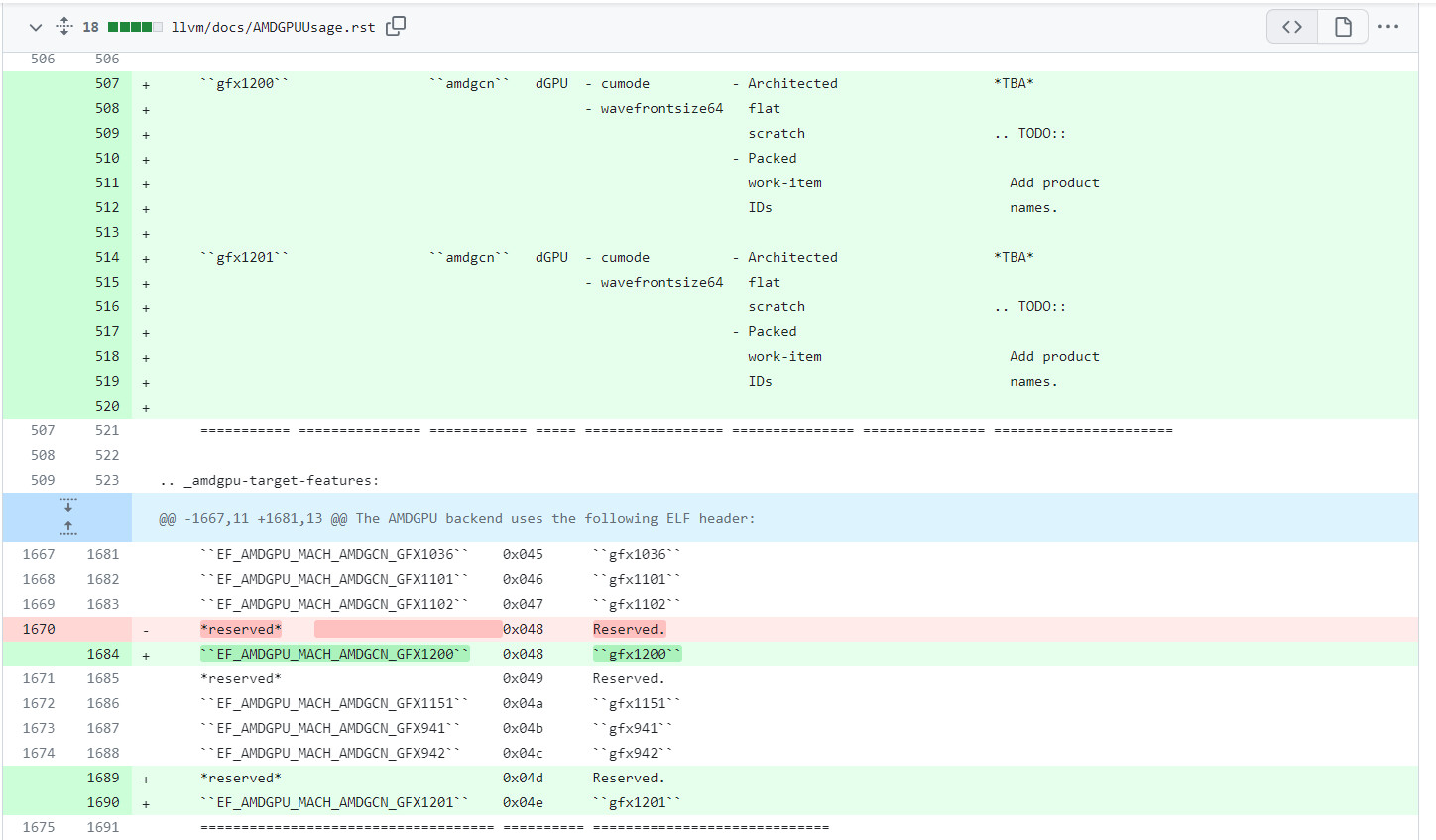
AMD is working hard on delivering next-generation products, and today, its Linux team has submitted a few interesting patches that made a subtle appearance through recent GitHub patches for GFX12 targets, as reported by Phoronix. These patches have introduced two new discrete GPUs into the LLVM compiler for Linux, fueling speculation that these will be the first iterations of the RDNA4 graphics architecture, potentially being a part of the Radeon RX 8000 series of desktop graphics cards. The naming scheme for these new targets, GFX1200 and GFX1201, suggests a continuation of AMD's logical progression through graphics architectures, considering the company's history of associating RDNA1 with GFX10 and following suit with subsequent generations, like RDNA2 was GFX10.2 and RDNA3 was GFX11.
The development of these new GPUs is still in the early stages, indicated by the lack of detailed information about the upcoming graphics ISA or its features within the patches. Currently, the new GFX12 targets are set to be treated akin to GFX11 as the patch notes that "For now they behave identically to GFX11," implying that AMD is keeping the specifics under wraps until closer to release. The patch that defines target names and ELF numbers for new GFX12 targets GFX1200 and GFX1201 is needed in order to enable timely support for AMD ROCm compute stack, the AMDVLK Vulkan driver, and the RadeonSI Gallium3D driver.

The development of these new GPUs is still in the early stages, indicated by the lack of detailed information about the upcoming graphics ISA or its features within the patches. Currently, the new GFX12 targets are set to be treated akin to GFX11 as the patch notes that "For now they behave identically to GFX11," implying that AMD is keeping the specifics under wraps until closer to release. The patch that defines target names and ELF numbers for new GFX12 targets GFX1200 and GFX1201 is needed in order to enable timely support for AMD ROCm compute stack, the AMDVLK Vulkan driver, and the RadeonSI Gallium3D driver.

IT Leaders Optimistic about Ways AI will Transform their Business and are Ramping up Investments
Today, AMD released the findings from a new survey of global IT leaders which found that 3 in 4 IT leaders are optimistic about the potential benefits of AI—from increased employee efficiency to automated cybersecurity solutions—and more than 2 in 3 are increasing investments in AI technologies. However, while AI presents clear opportunities for organizations to become more productive, efficient, and secure, IT leaders expressed uncertainty on their AI adoption timeliness due to their lack of implementation roadmaps and the overall readiness of their existing hardware and technology stack.
AMD commissioned the survey of 2,500 IT leaders across the United States, United Kingdom, Germany, France, and Japan to understand how AI technologies are re-shaping the workplace, how IT leaders are planning their AI technology and related Client hardware roadmaps, and what their biggest challenges are for adoption. Despite some hesitations around security and a perception that training the workforce would be burdensome, it became clear that organizations that have already implemented AI solutions are seeing a positive impact and organizations that delay risk being left behind. Of the organizations prioritizing AI deployments, 90% report already seeing increased workplace efficiency.
AMD commissioned the survey of 2,500 IT leaders across the United States, United Kingdom, Germany, France, and Japan to understand how AI technologies are re-shaping the workplace, how IT leaders are planning their AI technology and related Client hardware roadmaps, and what their biggest challenges are for adoption. Despite some hesitations around security and a perception that training the workforce would be burdensome, it became clear that organizations that have already implemented AI solutions are seeing a positive impact and organizations that delay risk being left behind. Of the organizations prioritizing AI deployments, 90% report already seeing increased workplace efficiency.

AMD Announces Radeon PRO W7600 and W7500 Graphics Cards
AMD today announced the Radeon PRO W7600 and W7500 graphics cards for the professional-visualization (pro-vis) market segment. These cards target the mid-range of the pro-vis segment, with segment price-band ranging between $350-950. The two are hence positioned below the W7800 and W7900 that the company launched in April. The W7600 and W7500 are based on the same RDNA3 graphics architecture as those two, and the client-segment RX 7000 series. AMD is pricing the the two new cards aggressively compared to NVIDIA. Both the W7500 and W7600 are based on the 6 nm "Navi 33" silicon.
The Radeon PRO W7600 leads today's launch, maxing out the silicon it is based on—you get 32 RDNA3 compute units, or 2,048 stream processors; 64 AI Accelerators, 32 Ray Accelerators; 128 TMUs, and 64 ROPs. The card comes with 8 GB of 18 Gbps GDDR6 memory across a 128-bit wide memory bus. The memory does not feature ECC. The card comes with a 130 W typical power draw, with a single 6-pin PCIe power connector. It uses a slick single-slot lateral-airflow cooling solution. AMD claims 20 TFLOPs peak FP32 performance.




The Radeon PRO W7600 leads today's launch, maxing out the silicon it is based on—you get 32 RDNA3 compute units, or 2,048 stream processors; 64 AI Accelerators, 32 Ray Accelerators; 128 TMUs, and 64 ROPs. The card comes with 8 GB of 18 Gbps GDDR6 memory across a 128-bit wide memory bus. The memory does not feature ECC. The card comes with a 130 W typical power draw, with a single 6-pin PCIe power connector. It uses a slick single-slot lateral-airflow cooling solution. AMD claims 20 TFLOPs peak FP32 performance.





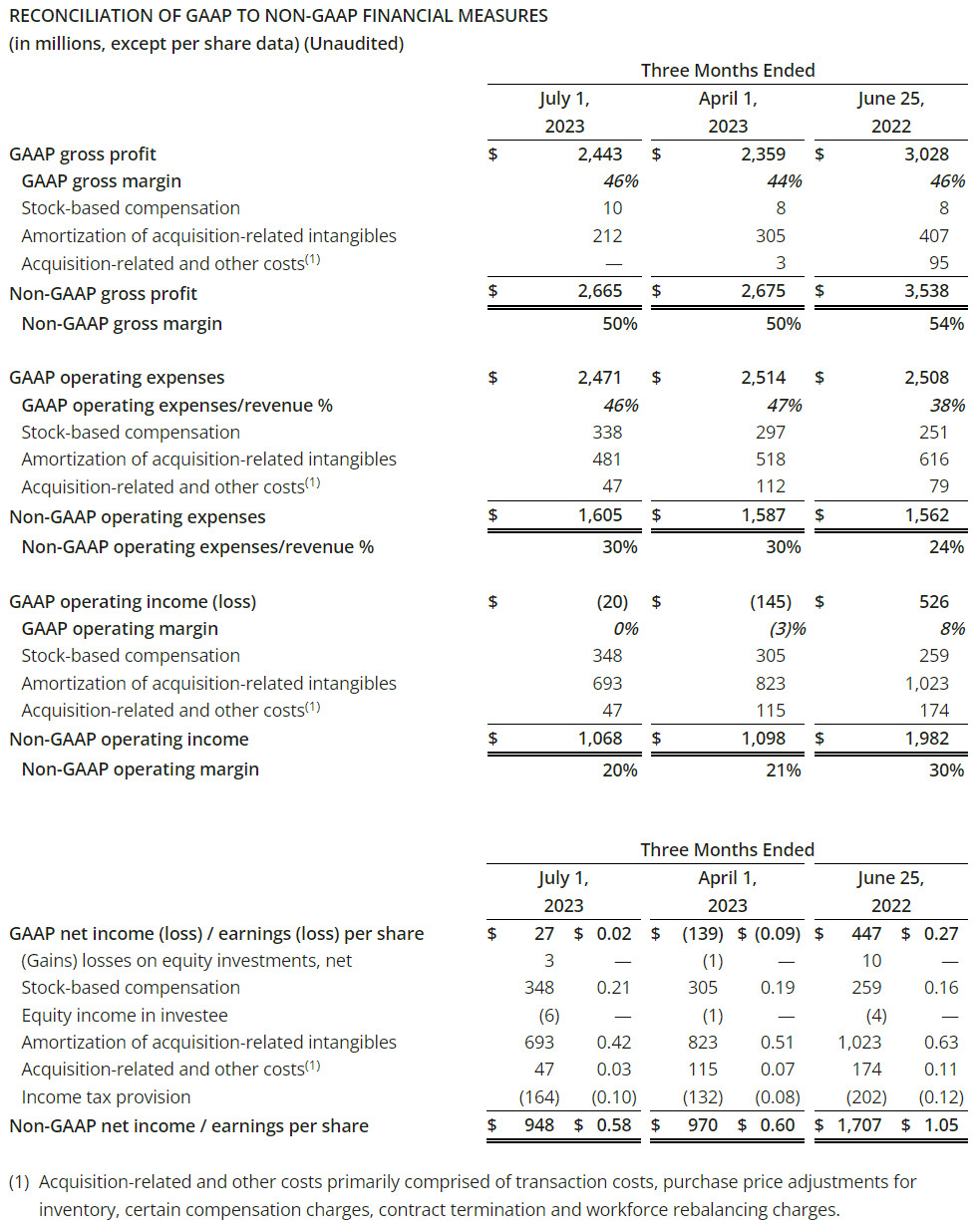
AMD Reports Second Quarter 2023 Financial Results, Revenue Down 18% YoY
AMD today announced revenue for the second quarter of 2023 of $5.4 billion, gross margin of 46%, operating loss of $20 million, net income of $27 million and diluted earnings per share of $0.02. On a non-GAAP basis, gross margin was 50%, operating income was $1.1 billion, net income was $948 million and diluted earnings per share was $0.58.
"We delivered strong results in the second quarter as 4th Gen EPYC and Ryzen 7000 processors ramped significantly," said AMD Chair and CEO Dr. Lisa Su. "Our AI engagements increased by more than seven times in the quarter as multiple customers initiated or expanded programs supporting future deployments of Instinct accelerators at scale. We made strong progress meeting key hardware and software milestones to address the growing customer pull for our data center AI solutions and are on-track to launch and ramp production of MI300 accelerators in the fourth quarter."



"We delivered strong results in the second quarter as 4th Gen EPYC and Ryzen 7000 processors ramped significantly," said AMD Chair and CEO Dr. Lisa Su. "Our AI engagements increased by more than seven times in the quarter as multiple customers initiated or expanded programs supporting future deployments of Instinct accelerators at scale. We made strong progress meeting key hardware and software milestones to address the growing customer pull for our data center AI solutions and are on-track to launch and ramp production of MI300 accelerators in the fourth quarter."



AMD "Vega" Architecture Gets No More ROCm Updates After Release 5.6
AMD's "Vega" graphics architecture powering graphics cards such as the Radeon VII, Radeon PRO VII, sees a discontinuation of maintenance with ROCm GPU programming software stack. The release notes of ROCm 5.6 states that the AMD Instinct MI50 accelerator, Radeon VII client graphics card, and Radeon PRO VII pro-vis graphics card, collectively referred to as "gfx906," will reach EOM (end of maintenance) starting Q3-2023, which aligns with the release of ROCm 5.7. Developer "EwoutH" on GitHub, who discovered this, remarks gfx906 is barely 5 years old, with the Radeon PRO VII and Instinct MI50 accelerator currently being sold in the market. The most recent AMD product powered by "Vega" has to be the "Cezanne" desktop processor, which uses an iGPU based on the architecture. This chip was released in Q2-2021.

AMD Details New EPYC CPUs, Next-Generation AMD Instinct Accelerator, and Networking Portfolio for Cloud and Enterprise
Today, at the "Data Center and AI Technology Premiere," AMD announced the products, strategy and ecosystem partners that will shape the future of computing, highlighting the next phase of data center innovation. AMD was joined on stage with executives from Amazon Web Services (AWS), Citadel, Hugging Face, Meta, Microsoft Azure and PyTorch to showcase the technological partnerships with industry leaders to bring the next generation of high performance CPU and AI accelerator solutions to market.
"Today, we took another significant step forward in our data center strategy as we expanded our 4th Gen EPYC processor family with new leadership solutions for cloud and technical computing workloads and announced new public instances and internal deployments with the largest cloud providers," said AMD Chair and CEO Dr. Lisa Su. "AI is the defining technology shaping the next generation of computing and the largest strategic growth opportunity for AMD. We are laser focused on accelerating the deployment of AMD AI platforms at scale in the data center, led by the launch of our Instinct MI300 accelerators planned for later this year and the growing ecosystem of enterprise-ready AI software optimized for our hardware."


"Today, we took another significant step forward in our data center strategy as we expanded our 4th Gen EPYC processor family with new leadership solutions for cloud and technical computing workloads and announced new public instances and internal deployments with the largest cloud providers," said AMD Chair and CEO Dr. Lisa Su. "AI is the defining technology shaping the next generation of computing and the largest strategic growth opportunity for AMD. We are laser focused on accelerating the deployment of AMD AI platforms at scale in the data center, led by the launch of our Instinct MI300 accelerators planned for later this year and the growing ecosystem of enterprise-ready AI software optimized for our hardware."



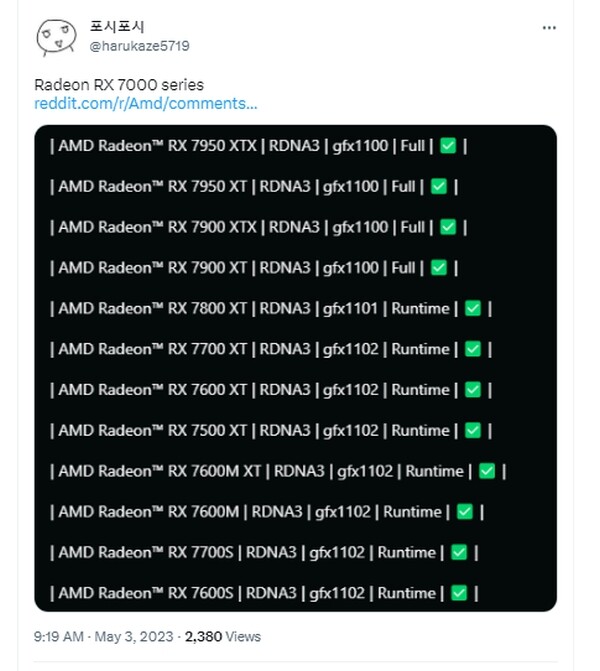
More Radeon RX 7000 Series Graphics Cards Spotted in ROCm 5.6
A bunch of unreleased AMD Radeon RX 7000 series graphics card have been spotted in ROCm 5.6 pull request, including the Radeon RX 7950 XTX, 7950 XT, 7800 XT, 7700 XT, 7600 XT, and 7500 XT. AMD has not yet launched its mainstream Radeon RX 7000 graphics cards, but according to the latest pull request, there are several unreleased graphics cards in for both high-end and mainstream segments. While the pull request has been removed from GitHub, it has been saved on Reddit. So far, it appears that AMD's RDNA 3 Radeon 7000 series lineup will be based on just three GPUs, Navi 33, Navi 32, and the Navi 31.
According to the list, we can expect a high-end refresh with Radeon RX 7950 XTX/XT version, also based on Navi 31 GPU. The list also shows that the Radeon RX 7800 series will be the only one based on the Navi 32 GPU, at least for now, while the Navi 33 GPU should cover the entire mainstream lineup, including the Radeon RX 7700 series, Radeon RX 7600 series, and the Radeon RX 7500 series. The list only includes XT versions, while non-XT should show up later, as it was the case with the Radeon RX 6000 series graphics cards. AMD's President and CEO, Dr. Lisa Su, already confirmed during Q1 2023 earnings call that mainstream Radeon RX 7000 series GPUs based on RDNA 3 architecture will launch during this quarter, and earlier rumors suggest we might see them at Computex 2023.
According to the list, we can expect a high-end refresh with Radeon RX 7950 XTX/XT version, also based on Navi 31 GPU. The list also shows that the Radeon RX 7800 series will be the only one based on the Navi 32 GPU, at least for now, while the Navi 33 GPU should cover the entire mainstream lineup, including the Radeon RX 7700 series, Radeon RX 7600 series, and the Radeon RX 7500 series. The list only includes XT versions, while non-XT should show up later, as it was the case with the Radeon RX 6000 series graphics cards. AMD's President and CEO, Dr. Lisa Su, already confirmed during Q1 2023 earnings call that mainstream Radeon RX 7000 series GPUs based on RDNA 3 architecture will launch during this quarter, and earlier rumors suggest we might see them at Computex 2023.
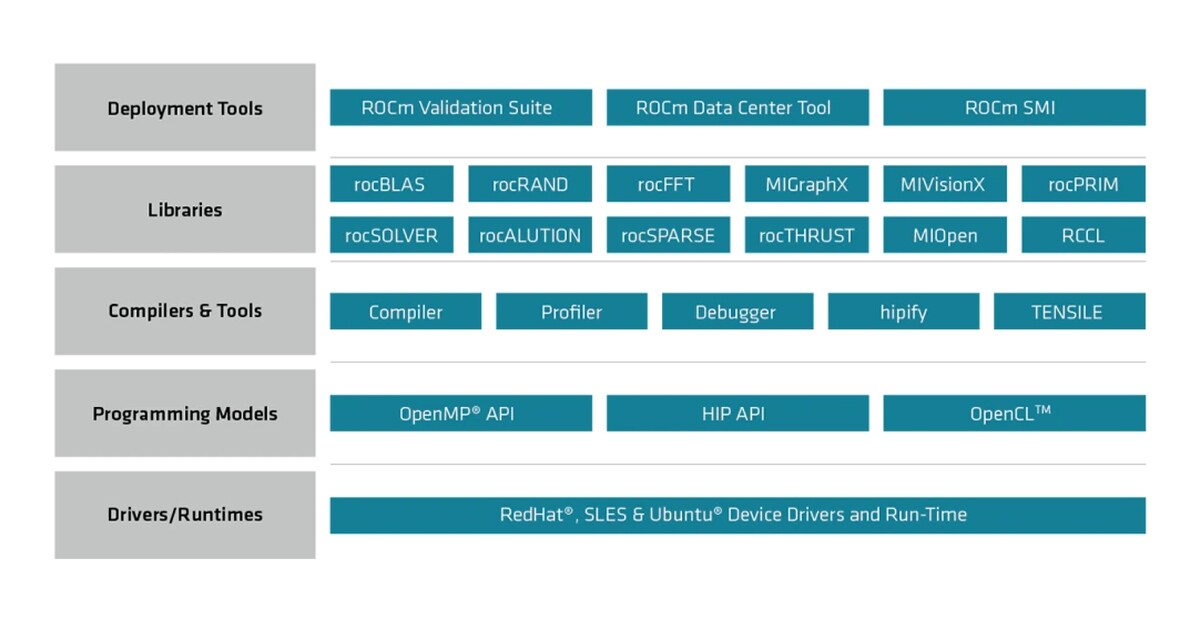
AMD ROCm 5.5 Now Available on GitHub
As expected with AMD's activity on GitHub, ROCm 5.5 has now been officially released. It brings several big changes, including better RDNA 3 support. While officially focused on AMD's professional/workstation graphics cards, the ROCm 5.5 should also bring better support for Radeon RX 7000 series graphics cards on Linux.
Surprisingly, the release notes do not officially mention RDNA 3 improvements in its release notes, but those have been already tested and confirmed. The GPU support list is pretty short including AMD GFX9, RDNA, and CDNA GPUs, ranging from Radeon VII, Pro VII, W6800, V620, and Instinct lineup. The release notes do mention new HIP enhancements, enhanced stack size limit, raising it from 16k to 128k, new APIs, OpenMP enhancements, and more. You can check out the full release notes, downloads, and more details over at GitHub.

Surprisingly, the release notes do not officially mention RDNA 3 improvements in its release notes, but those have been already tested and confirmed. The GPU support list is pretty short including AMD GFX9, RDNA, and CDNA GPUs, ranging from Radeon VII, Pro VII, W6800, V620, and Instinct lineup. The release notes do mention new HIP enhancements, enhanced stack size limit, raising it from 16k to 128k, new APIs, OpenMP enhancements, and more. You can check out the full release notes, downloads, and more details over at GitHub.

AMD Brings ROCm to Consumer GPUs on Windows OS
AMD has published an exciting development for its Radeon Open Compute Ecosystem (ROCm) users today. Now, ROCm is coming to the Windows operating system, and the company has extended ROCm support for consumer graphics cards instead of only supporting professional-grade GPUs. This development milestone is essential for making AMD's GPU family more competent with NVIDIA and its CUDA-accelerated GPUs. For those unaware, AMD ROCm is a software stack designed for GPU programming. Similarly to NVIDIA's CUDA, ROCm is designed for AMD GPUs and was historically limited to Linux-based OSes and GFX9, CDNA, and professional-grade RDNA GPUs.
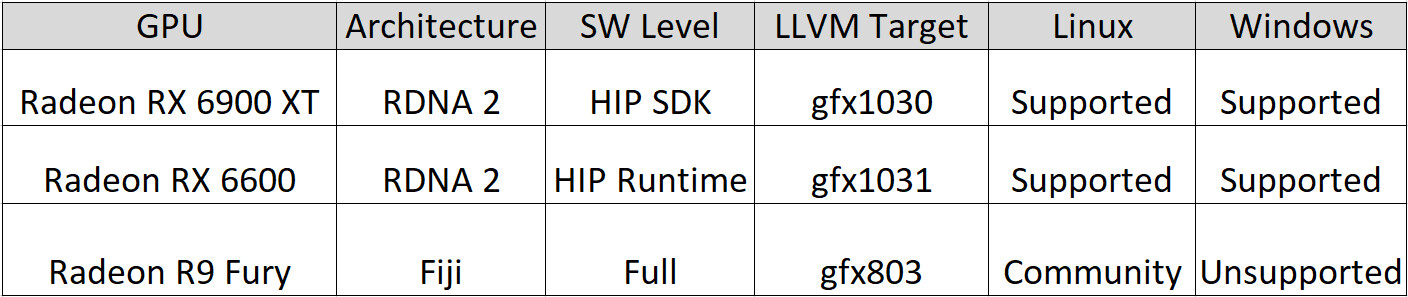
However, according to documents obtained by Tom's Hardware (which are behind a login wall), AMD has brought support for ROCm to Radeon RX 6900 XT, Radeon RX 6600, and R9 Fury GPU. What is interesting is not the inclusion of RX 6900 XT and RX 6600 but the support for R9 Fury, an eight-year-old graphics card. Also, what is interesting is that out of these three GPUs, only R9 Fury has full ROCm support, the RX 6900 XT has HIP SDK support, and RX 6600 has only HIP runtime support. And to make matters even more complicated, the consumer-grade R9 Fury GPU has full ROCm support only on Linux and not Windows. The reason for this strange selection of support has yet to be discovered. However, it is a step in the right direction, as AMD has yet to enable more functionality on Windows and more consumer GPUs to compete with NVIDIA.

However, according to documents obtained by Tom's Hardware (which are behind a login wall), AMD has brought support for ROCm to Radeon RX 6900 XT, Radeon RX 6600, and R9 Fury GPU. What is interesting is not the inclusion of RX 6900 XT and RX 6600 but the support for R9 Fury, an eight-year-old graphics card. Also, what is interesting is that out of these three GPUs, only R9 Fury has full ROCm support, the RX 6900 XT has HIP SDK support, and RX 6600 has only HIP runtime support. And to make matters even more complicated, the consumer-grade R9 Fury GPU has full ROCm support only on Linux and not Windows. The reason for this strange selection of support has yet to be discovered. However, it is a step in the right direction, as AMD has yet to enable more functionality on Windows and more consumer GPUs to compete with NVIDIA.

AMD Announces Appointment of New Corporate Fellows
AMD today announced the appointment of five technical leaders to the role of AMD Corporate Fellow. These appointments recognize each leader's significant impact on semiconductor innovation across various areas, from graphics architecture to advanced packaging. "David, Nathan, Suresh, Ben and Ralph - whose engineering contributions have already left an indelible mark on our industry - represent the best of our innovation culture," said Mark Papermaster, chief technology officer and executive vice president of Technology and Engineering at AMD. "Their appointments to Corporate Fellow will enable AMD to innovate in new dimensions as we work to deliver the most significant breakthroughs in high-performance computing in the decade ahead."
Appointment to AMD Corporate Fellow is an honor bestowed on the most accomplished AMD innovators. AMD Corporate Fellows are appointed after a rigorous review process that assesses not only specific technical contributions to the company, but also involvement in the industry, mentoring of others and improving the long-term strategic position of the company. Currently, only 13 engineers at AMD hold the title of Corporate Fellow.
Appointment to AMD Corporate Fellow is an honor bestowed on the most accomplished AMD innovators. AMD Corporate Fellows are appointed after a rigorous review process that assesses not only specific technical contributions to the company, but also involvement in the industry, mentoring of others and improving the long-term strategic position of the company. Currently, only 13 engineers at AMD hold the title of Corporate Fellow.

AMD RDNA3 Second-largest Navi 32 and Third-largest Navi 33 Shader Counts Leaked
The unified shader (stream processor) counts of AMD's upcoming second- and third-largest GPUs based on the RDNA3 graphics architecture, have been leaked in some ROCm code, discovered by Kepler_L2 on Twitter. The "performance.hpp" file references "Navi 32" with a compute unit count of 60, and the "Navi 33" with 32 compute units. We know from the "Navi 31" specifications that an RDNA3 compute unit still amounts to 64 stream processors (although with significant IPC uplifts over the RDNA2 stream processor due to dual-instruction issue-rate).
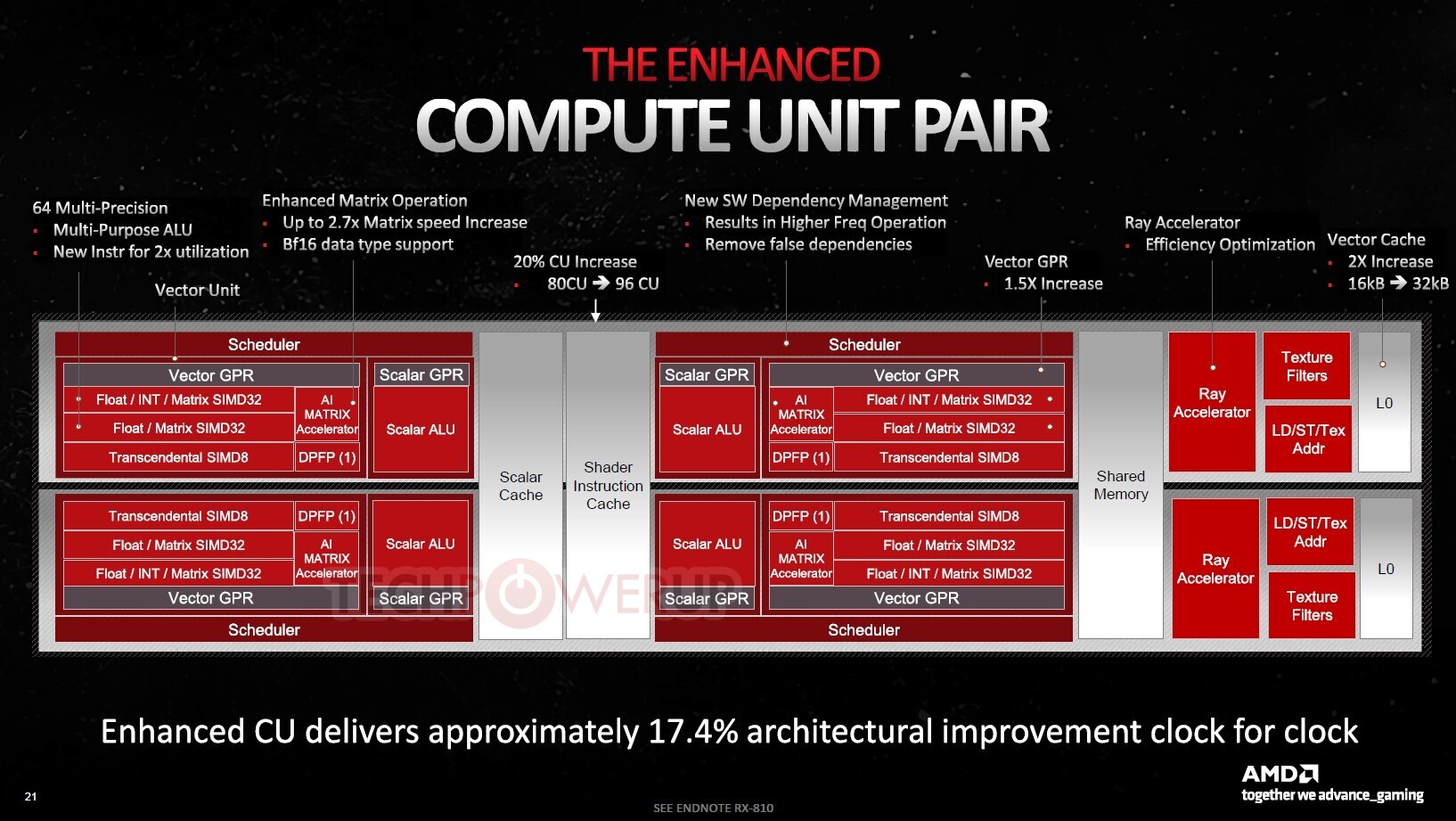
60 compute units would give the "Navi 32" silicon a stream processor count of 3,840, a 50% numerical increase over the 2,560 of its predecessor, the "Navi 22," powering graphics cards such as the Radeon RX 6750 XT. Meanwhile, the 32 CU count of the "Navi 33" amounts to 2,048 stream processors, which is numerically unchanged from that of the "Navi 23" powering the RX 6650 XT. The new RDNA3 compute unit has significant changes over RDNA2, besides the dual-issue stream processors—it gets second-generation Ray Accelerators, and two AI accelerators for matrix-multiplication.



60 compute units would give the "Navi 32" silicon a stream processor count of 3,840, a 50% numerical increase over the 2,560 of its predecessor, the "Navi 22," powering graphics cards such as the Radeon RX 6750 XT. Meanwhile, the 32 CU count of the "Navi 33" amounts to 2,048 stream processors, which is numerically unchanged from that of the "Navi 23" powering the RX 6650 XT. The new RDNA3 compute unit has significant changes over RDNA2, besides the dual-issue stream processors—it gets second-generation Ray Accelerators, and two AI accelerators for matrix-multiplication.



AMD Joins New PyTorch Foundation as Founding Member
AMD today announced it is joining the newly created PyTorch Foundation as a founding member. The foundation, which will be part of the non-profit Linux Foundation, will drive adoption of Artificial Intelligence (AI) tooling by fostering and sustaining an ecosystem of open source projects with PyTorch, the Machine Learning (ML) software framework originally created and fostered by Meta.
As a founding member, AMD joins others in the industry to prioritize the continued growth of PyTorch's vibrant community. Supported by innovations such as the AMD ROCm open software platform, AMD Instinct accelerators, Adaptive SoCs and CPUs, AMD will help the PyTorch Foundation by working to democratize state-of-the-art tools, libraries and other components to make these ML innovations accessible to everyone.
As a founding member, AMD joins others in the industry to prioritize the continued growth of PyTorch's vibrant community. Supported by innovations such as the AMD ROCm open software platform, AMD Instinct accelerators, Adaptive SoCs and CPUs, AMD will help the PyTorch Foundation by working to democratize state-of-the-art tools, libraries and other components to make these ML innovations accessible to everyone.

AMD WMMA Instruction is Direct Response to NVIDIA Tensor Cores
AMD's RDNA3 graphics IP is just around the corner, and we are hearing more information about the upcoming architecture. Historically, as GPUs advance, it is not unusual for companies to add dedicated hardware blocks to accelerate a specific task. Today, AMD engineers have updated the backend of the LLVM compiler to include a new instruction called Wave Matrix Multiply-Accumulate (WMMA). This instruction will be present on GFX11, which is the RDNA3 GPU architecture. With WMMA, AMD will offer support for processing 16x16x16 size tensors in FP16 and BF16 precision formats. With these instructions, AMD is adding new arrangements to support the processing of matrix multiply-accumulate operations. This is closely mimicking the work NVIDIA is doing with Tensor Cores.
AMD ROCm 5.2 API update lists the use case for this type of instruction, which you can see below:
AMD ROCm 5.2 API update lists the use case for this type of instruction, which you can see below:
rocWMMA provides a C++ API to facilitate breaking down matrix multiply accumulate problems into fragments and using them in block-wise operations that are distributed in parallel across GPU wavefronts. The API is a header library of GPU device code, meaning matrix core acceleration may be compiled directly into your kernel device code. This can benefit from compiler optimization in the generation of kernel assembly and does not incur additional overhead costs of linking to external runtime libraries or having to launch separate kernels.
rocWMMA is released as a header library and includes test and sample projects to validate and illustrate example usages of the C++ API. GEMM matrix multiplication is used as primary validation given the heavy precedent for the library. However, the usage portfolio is growing significantly and demonstrates different ways rocWMMA may be consumed.

AMD ROCm 4.5 Drops "Polaris" Architecture Support
AMD's ROCm compute programming platform—a competitor to NVIDIA's CUDA, dropped support for the "Polaris" graphics architecture, with the latest version 4.5 update. Users on the official ROCm git raised this as an issue assuming it was a bug, to which an official AMD support handle confirmed that the Radeon RX 480 graphics card of the original poster is no longer supported. Another user tested his "Polaris 20" based RX 570, and it isn't supported, either. It's conceivable that the "Polaris 30" based RX 590, a GPU launched in November 2018, isn't supported either. Cutting out a 3-year old graphics architecture from the compute platform sends the wrong message, especially to CUDA users who AMD wants to win over with ROCm. With contemporary GPUs priced out of reach, IT students are left with used older-generation graphics cards, such as those based on "Polaris." NVIDIA CUDA supports GPUs as far back as "Maxwell" (September 2014).

AMD Details Instinct MI200 Series Compute Accelerator Lineup
AMD today announced the new AMD Instinct MI200 series accelerators, the first exascale-class GPU accelerators. AMD Instinct MI200 series accelerators includes the world's fastest high performance computing (HPC) and artificial intelligence (AI) accelerator,1 the AMD Instinct MI250X.
Built on AMD CDNA 2 architecture, AMD Instinct MI200 series accelerators deliver leading application performance for a broad set of HPC workloads. The AMD Instinct MI250X accelerator provides up to 4.9X better performance than competitive accelerators for double precision (FP64) HPC applications and surpasses 380 teraflops of peak theoretical half-precision (FP16) for AI workloads to enable disruptive approaches in further accelerating data-driven research.
Built on AMD CDNA 2 architecture, AMD Instinct MI200 series accelerators deliver leading application performance for a broad set of HPC workloads. The AMD Instinct MI250X accelerator provides up to 4.9X better performance than competitive accelerators for double precision (FP64) HPC applications and surpasses 380 teraflops of peak theoretical half-precision (FP16) for AI workloads to enable disruptive approaches in further accelerating data-driven research.

AMD Leads High Performance Computing Towards Exascale and Beyond
At this year's International Supercomputing 2021 digital event, AMD (NASDAQ: AMD) is showcasing momentum for its AMD EPYC processors and AMD Instinct accelerators across the High Performance Computing (HPC) industry. The company also outlined updates to the ROCm open software platform and introduced the AMD Instinct Education and Research (AIER) initiative. The latest Top500 list showcased the continued growth of AMD EPYC processors for HPC systems. AMD EPYC processors power nearly 5x more systems compared to the June 2020 list, and more than double the number of systems compared to November 2020. As well, AMD EPYC processors power half of the 58 new entries on the June 2021 list.
"High performance computing is critical to addressing the world's biggest and most important challenges," said Forrest Norrod, senior vice president and general manager, data center and embedded systems group, AMD. "With our AMD EPYC processor family and Instinct accelerators, AMD continues to be the partner of choice for HPC. We are committed to enabling the performance and capabilities needed to advance scientific discoveries, break the exascale barrier, and continue driving innovation."
"High performance computing is critical to addressing the world's biggest and most important challenges," said Forrest Norrod, senior vice president and general manager, data center and embedded systems group, AMD. "With our AMD EPYC processor family and Instinct accelerators, AMD continues to be the partner of choice for HPC. We are committed to enabling the performance and capabilities needed to advance scientific discoveries, break the exascale barrier, and continue driving innovation."
AMD Announces CDNA Architecture. Radeon MI100 is the World's Fastest HPC Accelerator
AMD today announced the new AMD Instinct MI100 accelerator - the world's fastest HPC GPU and the first x86 server GPU to surpass the 10 teraflops (FP64) performance barrier. Supported by new accelerated compute platforms from Dell, Gigabyte, HPE, and Supermicro, the MI100, combined with AMD EPYC CPUs and the ROCm 4.0 open software platform, is designed to propel new discoveries ahead of the exascale era.
Built on the new AMD CDNA architecture, the AMD Instinct MI100 GPU enables a new class of accelerated systems for HPC and AI when paired with 2nd Gen AMD EPYC processors. The MI100 offers up to 11.5 TFLOPS of peak FP64 performance for HPC and up to 46.1 TFLOPS peak FP32 Matrix performance for AI and machine learning workloads. With new AMD Matrix Core technology, the MI100 also delivers a nearly 7x boost in FP16 theoretical peak floating point performance for AI training workloads compared to AMD's prior generation accelerators.




Built on the new AMD CDNA architecture, the AMD Instinct MI100 GPU enables a new class of accelerated systems for HPC and AI when paired with 2nd Gen AMD EPYC processors. The MI100 offers up to 11.5 TFLOPS of peak FP64 performance for HPC and up to 46.1 TFLOPS peak FP32 Matrix performance for AI and machine learning workloads. With new AMD Matrix Core technology, the MI100 also delivers a nearly 7x boost in FP16 theoretical peak floating point performance for AI training workloads compared to AMD's prior generation accelerators.





AMD Radeon "Navy Flounder" Features 40CU, 192-bit GDDR6 Memory
AMD uses offbeat codenames such as the "Great Horned Owl," "Sienna Cichlid" and "Navy Flounder" to identify sources of leaks internally. One such upcoming product, codenamed "Navy Flounder," is shaping up to be a possible successor to the RX 5500 XT, the company's 1080p segment-leading product. According to ROCm compute code fished out by stblr on Reddit, this GPU is configured with 40 compute units, a step up from 14 on the RX 5500 XT, and retains a 192-bit wide GDDR6 memory interface.
Assuming the RDNA2 compute unit on next-gen Radeon RX graphics processors has the same number of stream processors per CU, we're looking at 2,560 stream processors for the "Navy Flounder," compared to 80 on "Sienna Cichlid." The 192-bit wide memory interface allows a high degree of segmentation for AMD's product managers for graphics cards under the $250-mark.
Assuming the RDNA2 compute unit on next-gen Radeon RX graphics processors has the same number of stream processors per CU, we're looking at 2,560 stream processors for the "Navy Flounder," compared to 80 on "Sienna Cichlid." The 192-bit wide memory interface allows a high degree of segmentation for AMD's product managers for graphics cards under the $250-mark.

AMD Announces Radeon Pro VII Graphics Card, Brings Back Multi-GPU Bridge
AMD today announced its Radeon Pro VII professional graphics card targeting 3D artists, engineering professionals, broadcast media professionals, and HPC researchers. The card is based on AMD's "Vega 20" multi-chip module that incorporates a 7 nm (TSMC N7) GPU die, along with a 4096-bit wide HBM2 memory interface, and four memory stacks adding up to 16 GB of video memory. The GPU die is configured with 3,840 stream processors across 60 compute units, 240 TMUs, and 64 ROPs. The card is built in a workstation-optimized add-on card form-factor (rear-facing power connectors and lateral-blower cooling solution).
What separates the Radeon Pro VII from last year's Radeon VII is full double precision floating point support, which is 1:2 FP32 throughput compared to the Radeon VII, which is locked to 1:4 FP32. Specifically, the Radeon Pro VII offers 6.55 TFLOPs double-precision floating point performance (vs. 3.36 TFLOPs on the Radeon VII). Another major difference is the physical Infinity Fabric bridge interface, which lets you pair up to two of these cards in a multi-GPU setup to double the memory capacity, to 32 GB. Each GPU has two Infinity Fabric links, running at 1333 MHz, with a per-direction bandwidth of 42 GB/s. This brings the total bidirectional bandwidth to a whopping 168 GB/s—more than twice the PCIe 4.0 x16 limit of 64 GB/s.



What separates the Radeon Pro VII from last year's Radeon VII is full double precision floating point support, which is 1:2 FP32 throughput compared to the Radeon VII, which is locked to 1:4 FP32. Specifically, the Radeon Pro VII offers 6.55 TFLOPs double-precision floating point performance (vs. 3.36 TFLOPs on the Radeon VII). Another major difference is the physical Infinity Fabric bridge interface, which lets you pair up to two of these cards in a multi-GPU setup to double the memory capacity, to 32 GB. Each GPU has two Infinity Fabric links, running at 1333 MHz, with a per-direction bandwidth of 42 GB/s. This brings the total bidirectional bandwidth to a whopping 168 GB/s—more than twice the PCIe 4.0 x16 limit of 64 GB/s.





AMD Scores Another EPYC Win in Exascale Computing With DOE's "El Capitan" Two-Exaflop Supercomputer
AMD has been on a roll in both consumer, professional, and exascale computing environments, and it has just snagged itself another hugely important contract. The US Department of Energy (DOE) has just announced the winners for their next-gen, exascale supercomputer that aims to be the world's fastest. Dubbed "El Capitan", the new supercomputer will be powered by AMD's next-gen EPYC Genoa processors (Zen 4 architecture) and Radeon GPUs. This is the first such exascale contract where AMD is the sole purveyor of both CPUs and GPUs, with AMD's other design win with EPYC in the Cray Shasta being paired with NVIDIA graphics cards.
El Capitan will be a $600 million investment to be deployed in late 2022 and operational in 2023. Undoubtedly, next-gen proposals from AMD, Intel and NVIDIA were presented, with AMD winning the shootout in a big way. While initially the DOE projected El Capitan to provide some 1.5 exaflops of computing power, it has now revised their performance goals to a pure 2 exaflop machine. El Capitan willl thus be ten times faster than the current leader of the supercomputing world, Summit.


El Capitan will be a $600 million investment to be deployed in late 2022 and operational in 2023. Undoubtedly, next-gen proposals from AMD, Intel and NVIDIA were presented, with AMD winning the shootout in a big way. While initially the DOE projected El Capitan to provide some 1.5 exaflops of computing power, it has now revised their performance goals to a pure 2 exaflop machine. El Capitan willl thus be ten times faster than the current leader of the supercomputing world, Summit.



AMD Announces Mini PC Initiative, Brings the Fight to Intel in Yet Another Product Segment
AMD is wading into even deeper waters across Intel's markets with the announcement of new Mini-PCs powered by the company's AMD Ryzen embedded V1000 and R1000 processors. Mini PCs, powered by AMD Ryzen Embedded V1000 and R1000 processors. Multiple partners such as ASRock Industrial, EEPD, OnLogic and Simply NUC have already designed their own takes on Mini-PCs (comparable to Intel's NUC, Next unit of Computing) as a way to give businesses a way to have a small form factor box for different computing needs. These aim to offer a high-performance CPU/GPU processor with expansive peripheral support, in-depth security features and a planned 10-year processor availability.
Until now, AMD's Ryzen Embedded product line had mostly scored one design win here and there, powering handheld consoles such as the Smach Z and such other low power, relatively high-performance environments. When AMD announced the R1000 SoC back in April, it already announced that partners would be bringing their own takes on the underlying silicon, and today is the announcement of that effort.


Until now, AMD's Ryzen Embedded product line had mostly scored one design win here and there, powering handheld consoles such as the Smach Z and such other low power, relatively high-performance environments. When AMD announced the R1000 SoC back in April, it already announced that partners would be bringing their own takes on the underlying silicon, and today is the announcement of that effort.



Apr 24th, 2025 13:51 EDT
change timezone
Latest GPU Drivers
New Forum Posts
- Choosing an Internal HDD (2)
- New GPU 5070 Ti or better CPU Ryzen7 7800X3D ? (18)
- Companies should be called out for this (91)
- Are the 8 GB cards worth it? (160)
- To distill or not distill what say ye? (99)
- Do you use Linux? (592)
- I dont understand the phone OS world..... (32)
- 5060 Ti 8GB DOA (265)
- Thermal testing two different size Gigabyte 5070 Ti cards - huge differences (28)
- Asus Rx570 o4g cannot losd drivers error code 43 (15)
Popular Reviews
- NVIDIA GeForce RTX 5060 Ti 8 GB Review - So Many Compromises
- Colorful iGame B860M Ultra V20 Review
- ASUS GeForce RTX 5060 Ti TUF OC 16 GB Review
- ASRock X870E Taichi Lite Review
- Upcoming Hardware Launches 2025 (Updated Apr 2025)
- Sapphire Radeon RX 9070 XT Pulse Review
- Sapphire Radeon RX 9070 XT Nitro+ Review - Beating NVIDIA
- Crucial CUDIMM DDR5-6400 128 GB CL52 Review
- AMD Ryzen 7 9800X3D Review - The Best Gaming Processor
- NVIDIA GeForce RTX 5060 Ti PCI-Express x8 Scaling
Controversial News Posts
- NVIDIA GeForce RTX 5060 Ti 16 GB SKU Likely Launching at $499, According to Supply Chain Leak (182)
- NVIDIA Sends MSRP Numbers to Partners: GeForce RTX 5060 Ti 8 GB at $379, RTX 5060 Ti 16 GB at $429 (127)
- NVIDIA Launches GeForce RTX 5060 Series, Beginning with RTX 5060 Ti This Week (115)
- Nintendo Confirms That Switch 2 Joy-Cons Will Not Utilize Hall Effect Stick Technology (105)
- Nintendo Switch 2 Launches June 5 at $449.99 with New Hardware and Games (99)
- Sony Increases the PS5 Pricing in EMEA and ANZ by Around 25 Percent (85)
- NVIDIA PhysX and Flow Made Fully Open-Source (77)
- Windows Notepad Gets Microsoft Copilot Integration (75)