 154
154
ASUS GeForce RTX 5090 Astral OC Review - Astronomical Premium
Neural Rendering, DLSS 4, Reflex 2 »NVIDIA Blackwell Architecture
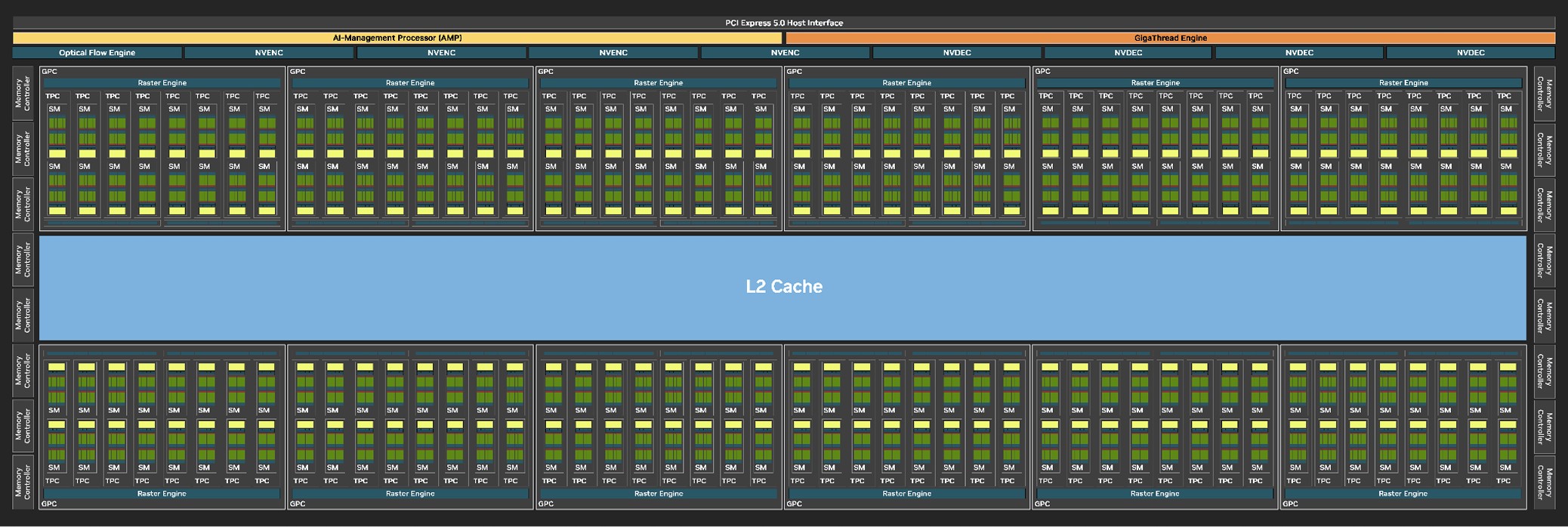
The GeForce Blackwell graphics architecture heralds NVIDIA's 4th generation of RTX, the late-2010s re-invention of the modern GPU that sees a fusion of real time ray traced objects with conventional raster 3D graphics. With Blackwell, NVIDIA is helping add another dimension, neural rendering, the ability for the GPU to leverage a generative AI to create portions of a frame. This is different from DLSS, where an AI model is used to reconstruct details in an upscaled frame based on its training date, temporal frames, and motion vectors. At the heart of the GeForce RTX 5090 we are reviewing today is the mammoth 5 nm GB202 silicon. This is one of the largest monolithic dies ever designed by NVIDIA, measuring 750 mm², compared to the 608.5 mm² of the AD102 die. The process is unchanged between the two generations—it's still an NVIDIA-specific variant of TSMC 5 nm EUV, dubbed TSMC 4N. The GB202 rocks 92.2 billion transistors, a 20% increase over the AD102.
The GB202 silicon is laid out essentially in the same component hierarchy as past generations of NVIDIA GPUs, but with a few notable changes. The GPU features PCI-Express 5.0 x16, making it the first gaming GPU to do so. PCIe Gen 5 has been around since Intel's 12th Gen Core "Alder Lake" and AMD's Ryzen 7000 "Zen 4," so there is a sizable install-base of systems that can take advantage of it. The GPU is of course compatible with older generations of PCIe. Whether this affects performance is a question we cover in our separate RTX 5090 PCIe Scaling Article. The GB202 is also the first GPU to implement the new GDDR7 memory standard, which doubles speeds over GDDR6 while lowering the energy cost of bandwidth. NVIDIA left no half-measures with the GB202, and gave it a broad 512-bit GDDR7 memory interface. On the RTX 5090, this is configured with 32 GB of 28 Gbps GDDR7. Upcoming RTX 50-series SKUs could have narrower memory interfaces but with higher memory speeds, and some professional graphics cards based on the GB202 could even use high-density memory chips.
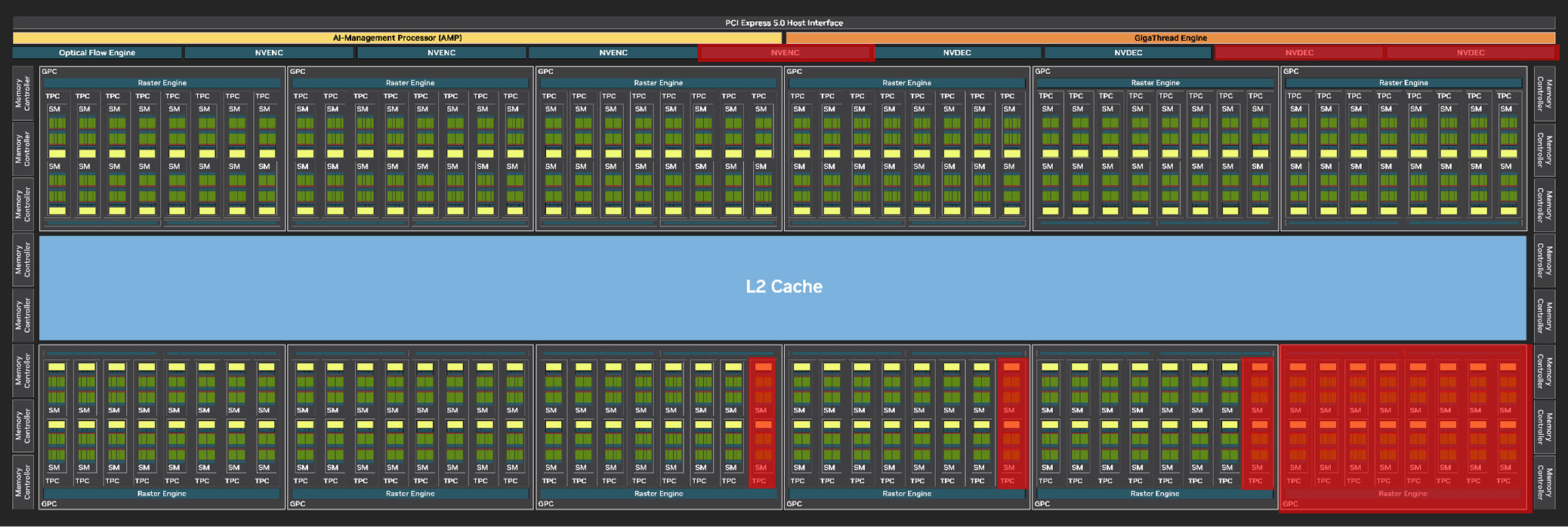
The GigaThread Engine is the main graphics rendering workload allocation logic on the GB202, but there's a new addition, a dedicated serial processor for managing all AI acceleration resources on the GPU, NVIDIA calls this AMP (AI management processor). Other components at the global level are the Optical Flow Processor, a component involved in older versions of DLSS frame generation and for video encoding; and a vast media acceleration engine consisting of four NVENC encode accelerators, and four NVDEC decode accelerators. The new 9th Gen NVENC video encode accelerators come with 4:2:2 AV1 and HEVC encoding support. The RTX 5090 has 3 out of 4 NVENC and 2 out of 4 NVDEC units enabled. The central region of the GPU has the single largest common component, the 128 MB L2 cache. The RTX 5090 is configured with 96 MB of it.
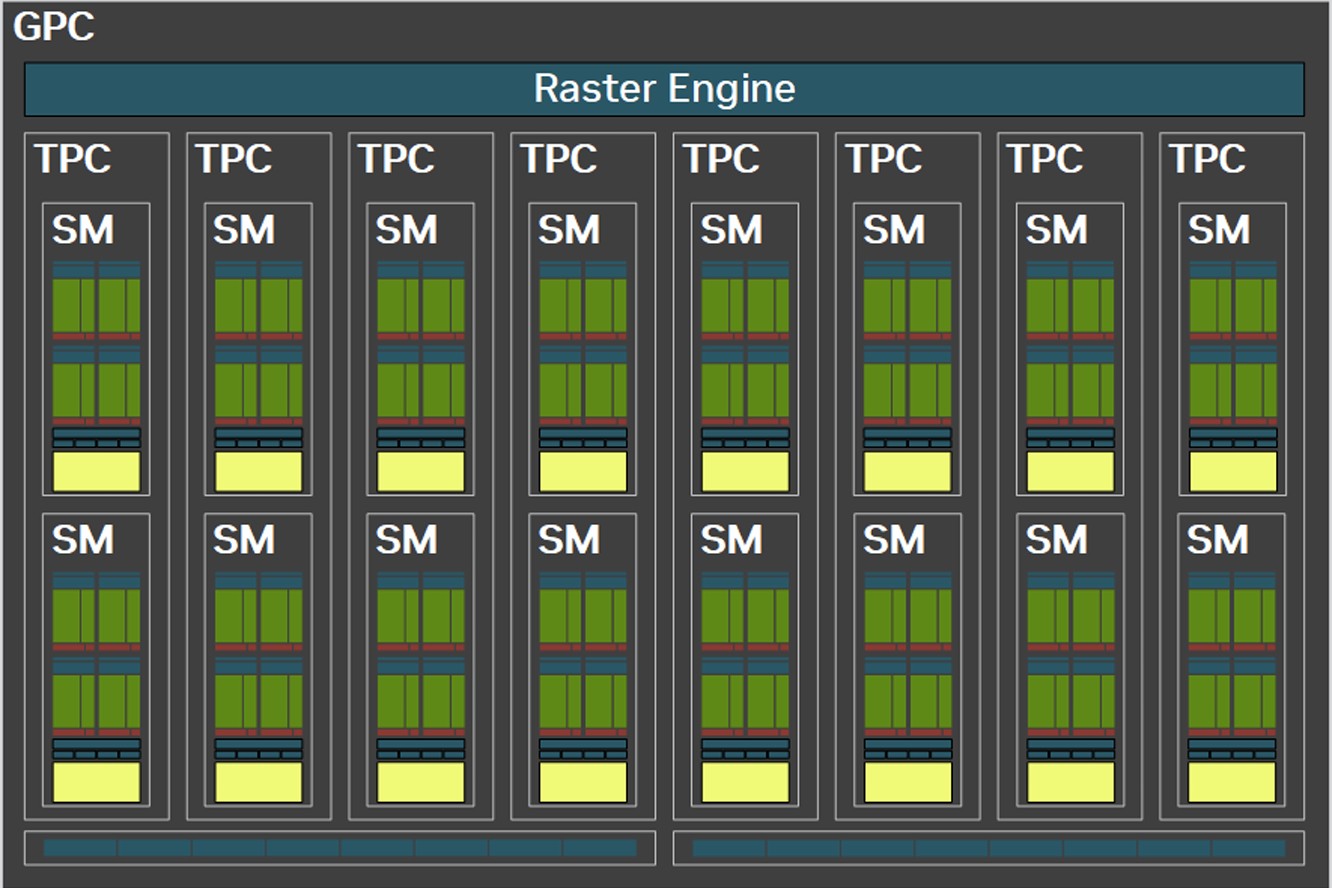
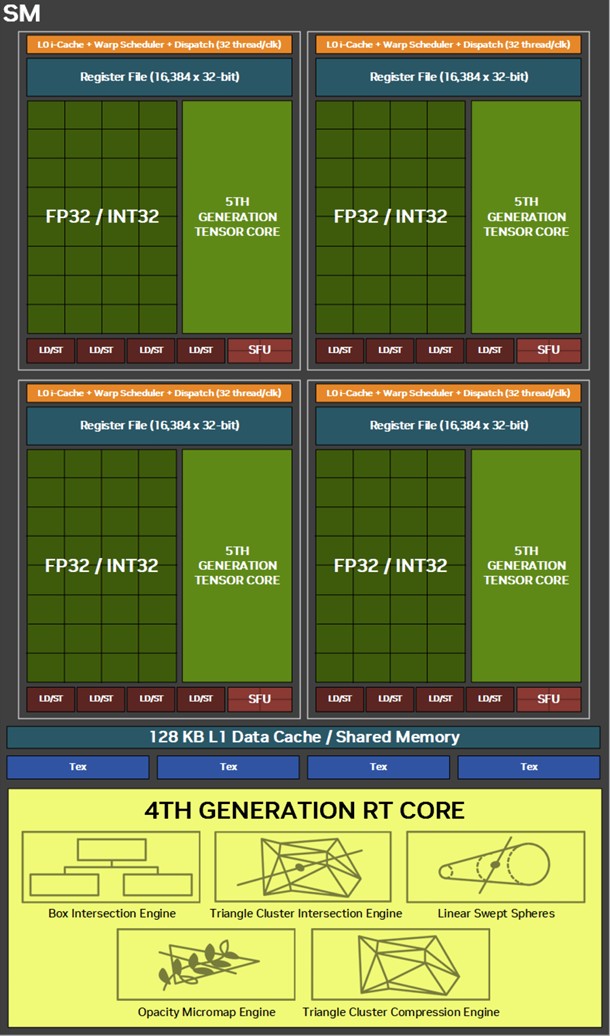
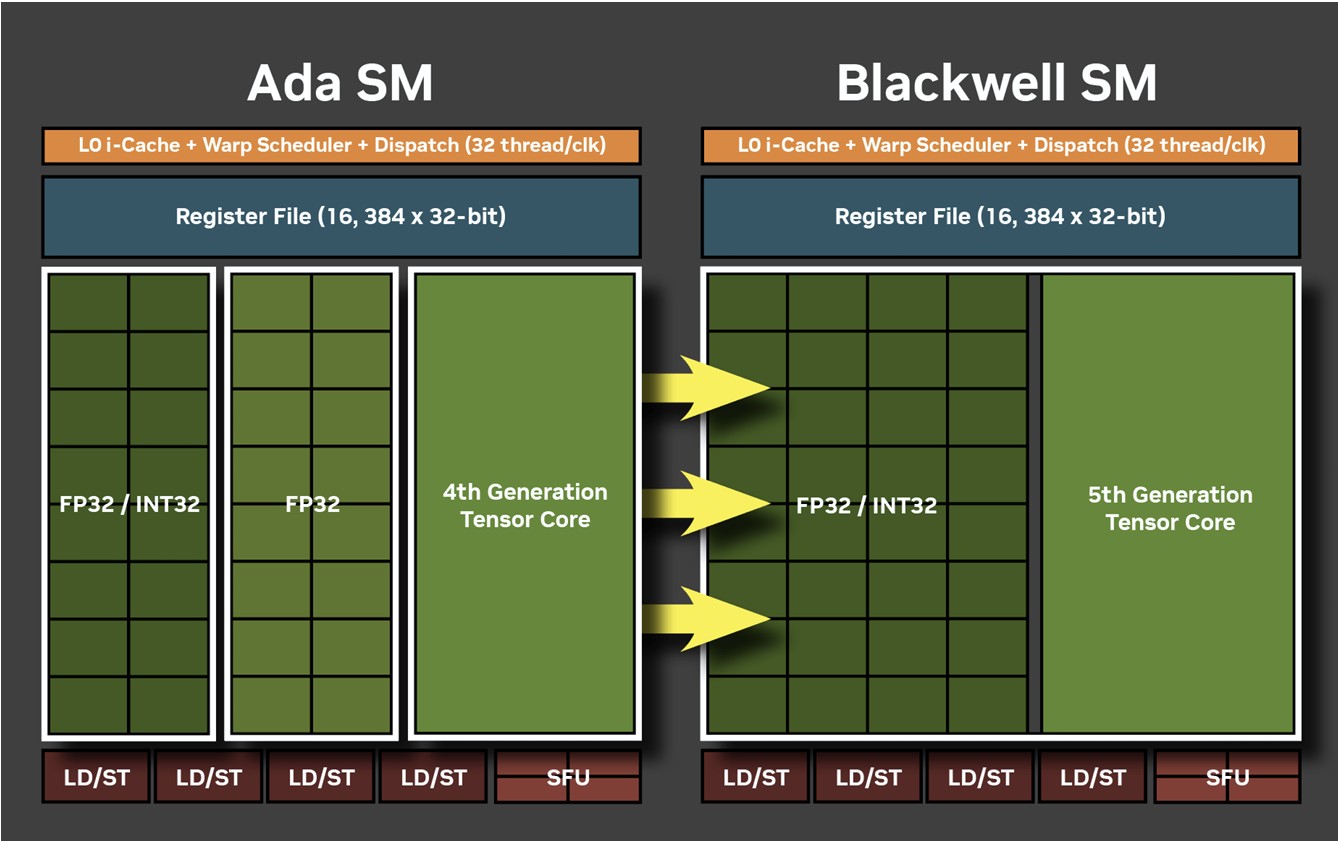
Each graphics processing cluster (GPC) is a subdivision of the GPU with nearly all components needed for graphics rendering. On the GB202, a GPC consists of 16 streaming multiprocessors (SM) across 8 texture processing clusters (TPCs), and a raster engine consisting of 16 ROPs. Each SM contains 128 CUDA cores. Unlike the Ada generation SM that each had 64 FP32+INT32 and 64 purely-FP32 SIMD units, the new Blackwell generation SM features concurrent FP32+INT32 capability on all 128 SIMD units. These 128 CUDA cores are arranged in four slices, each with a register file, a level-0 instruction cache, a warp scheduler, two sets of load-store units, and a special function unit (SFU) handling some special math functions such as trigonometry, exponents, logarithms, reciprocals, and square-root. The four slices share a 128 KB L1 data cache, and four TMUs. The most exotic components of the Blackwell SM are the four 5th Gen Tensor cores, and a 4th Gen RT core.
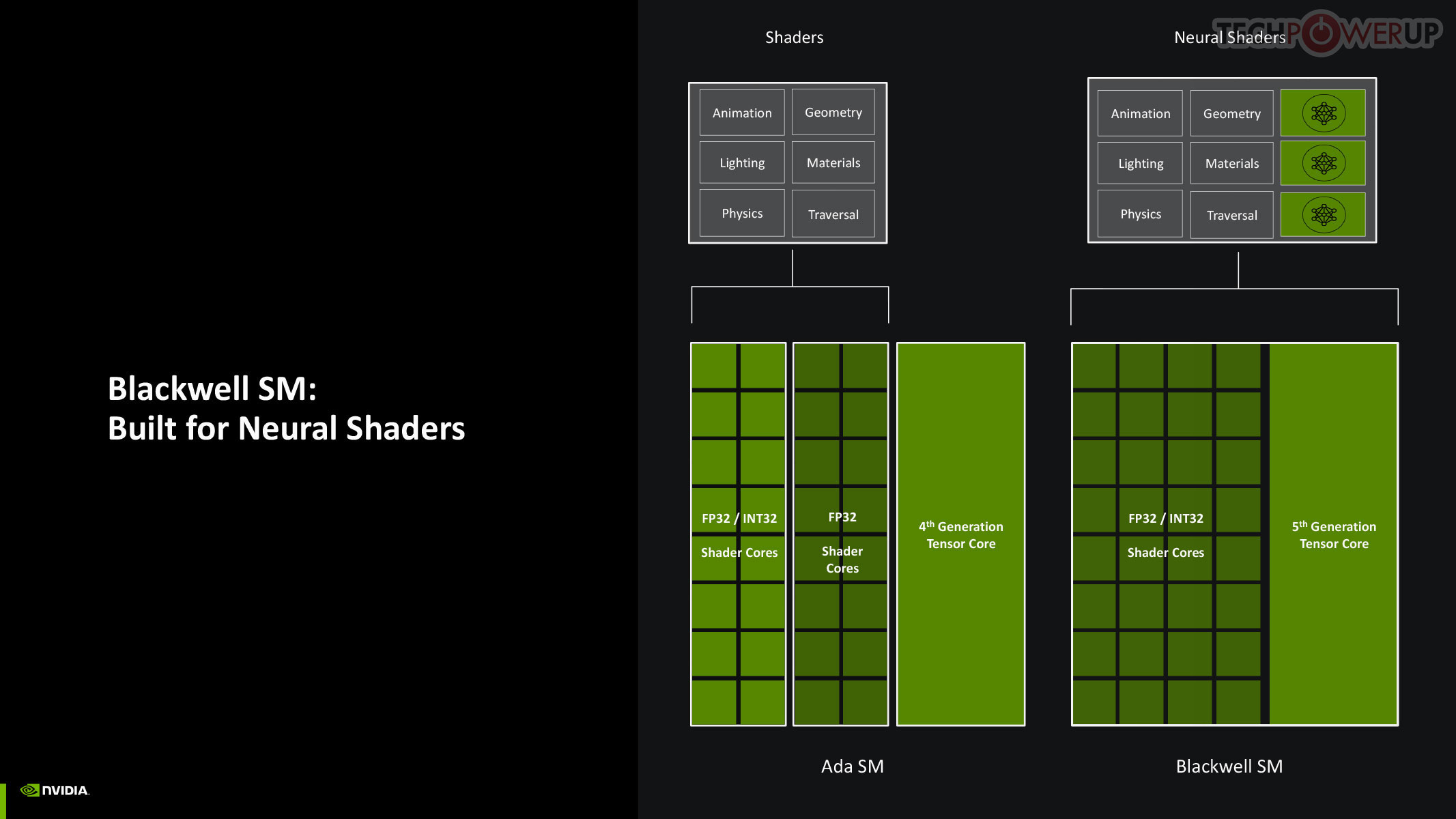
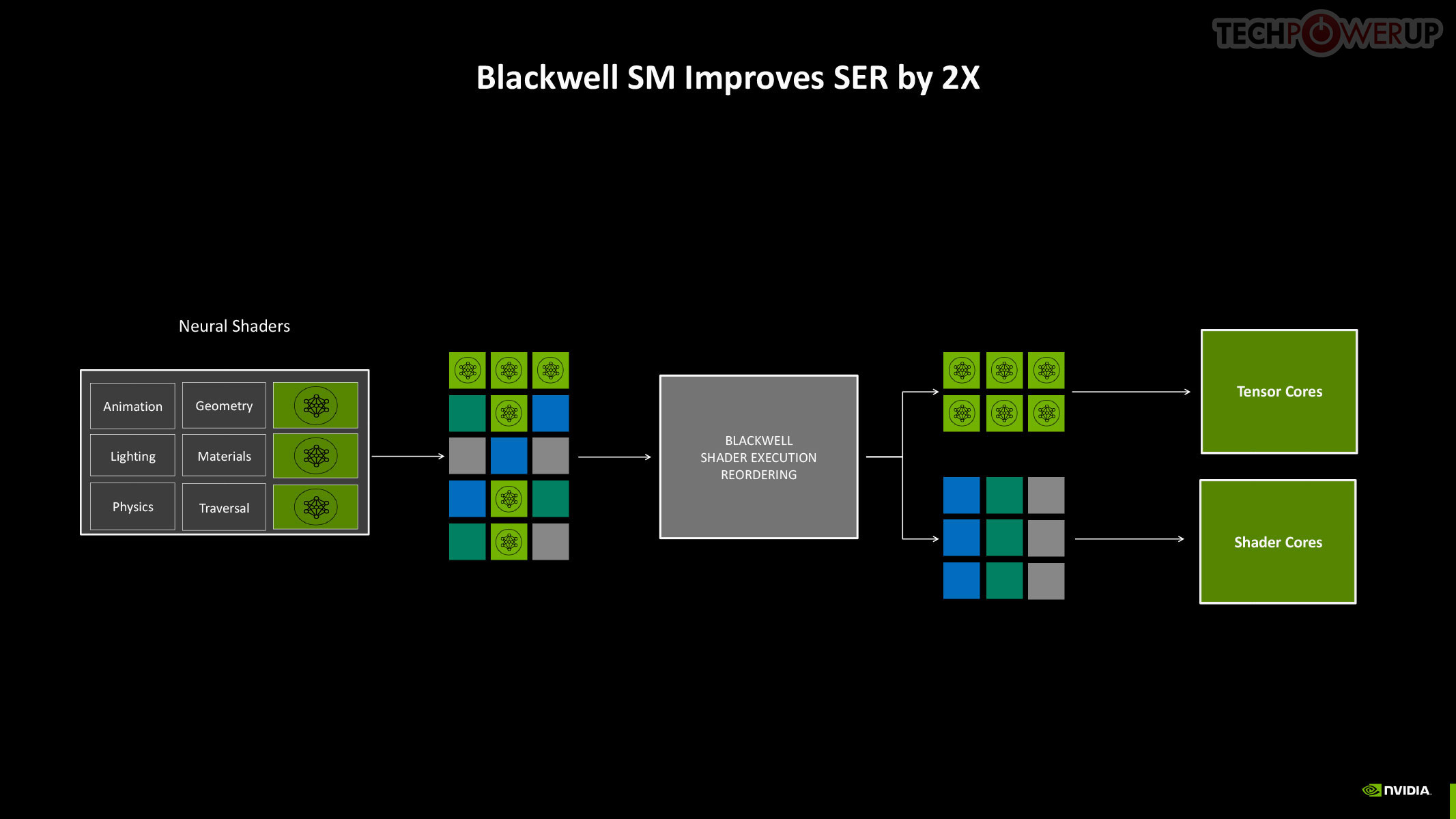
Perhaps the biggest change to the way the SM handles work introduced with Blackwell is the concept of neural shaders—treating portions of the graphics rendering workload done by a generative AI model as shaders. Microsoft has laid the groundwork for standardization of neural shaders with its Cooperative Vectors API, in the latest update to DirectX 12. The Tensor cores are now accessible for workloads through neural shaders, and the shader execution reordering (SER) engine of the Blackwell SM is able to more accurately reorder workloads for the CUDA cores and the Tensor core in an SM.
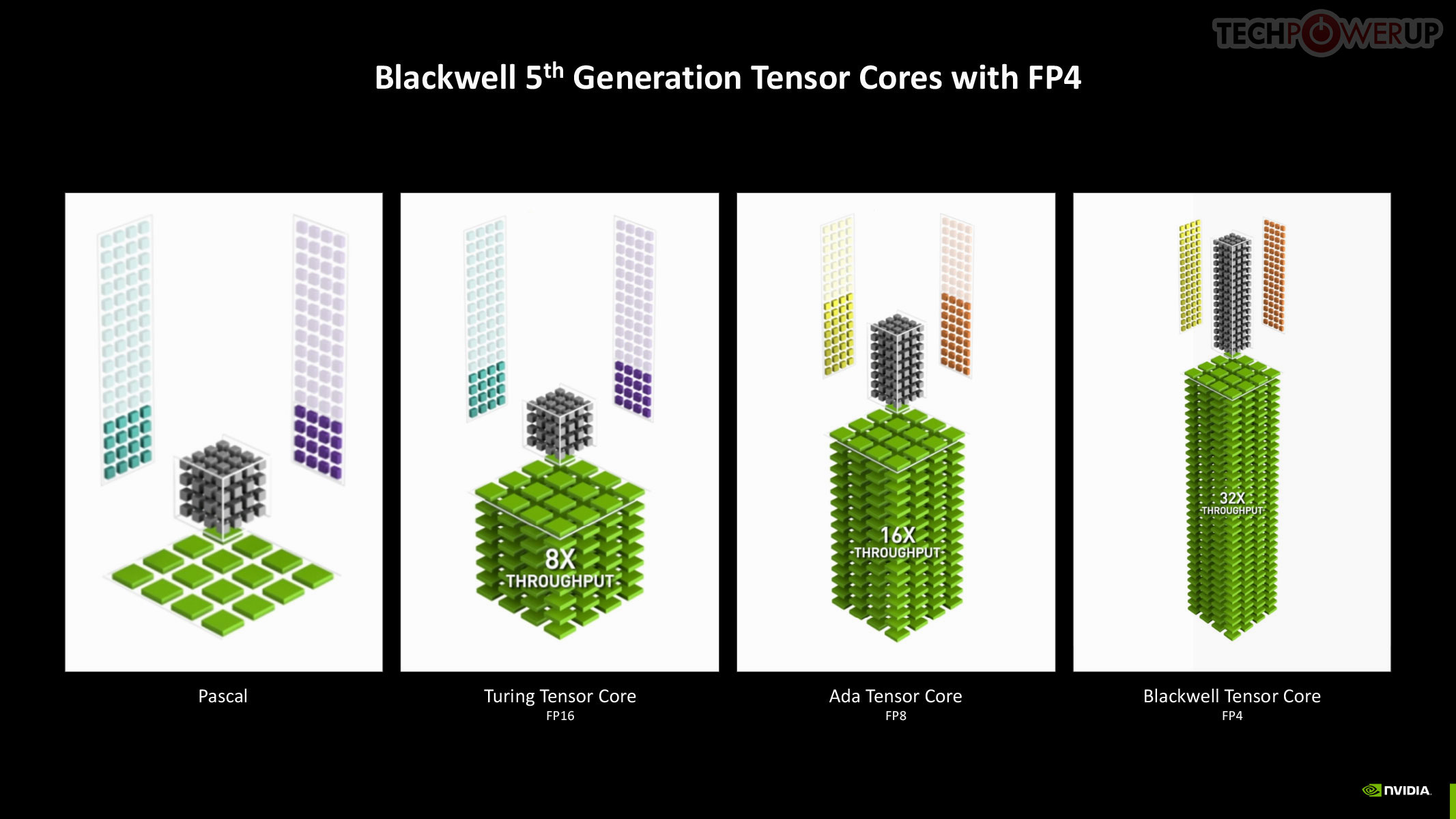
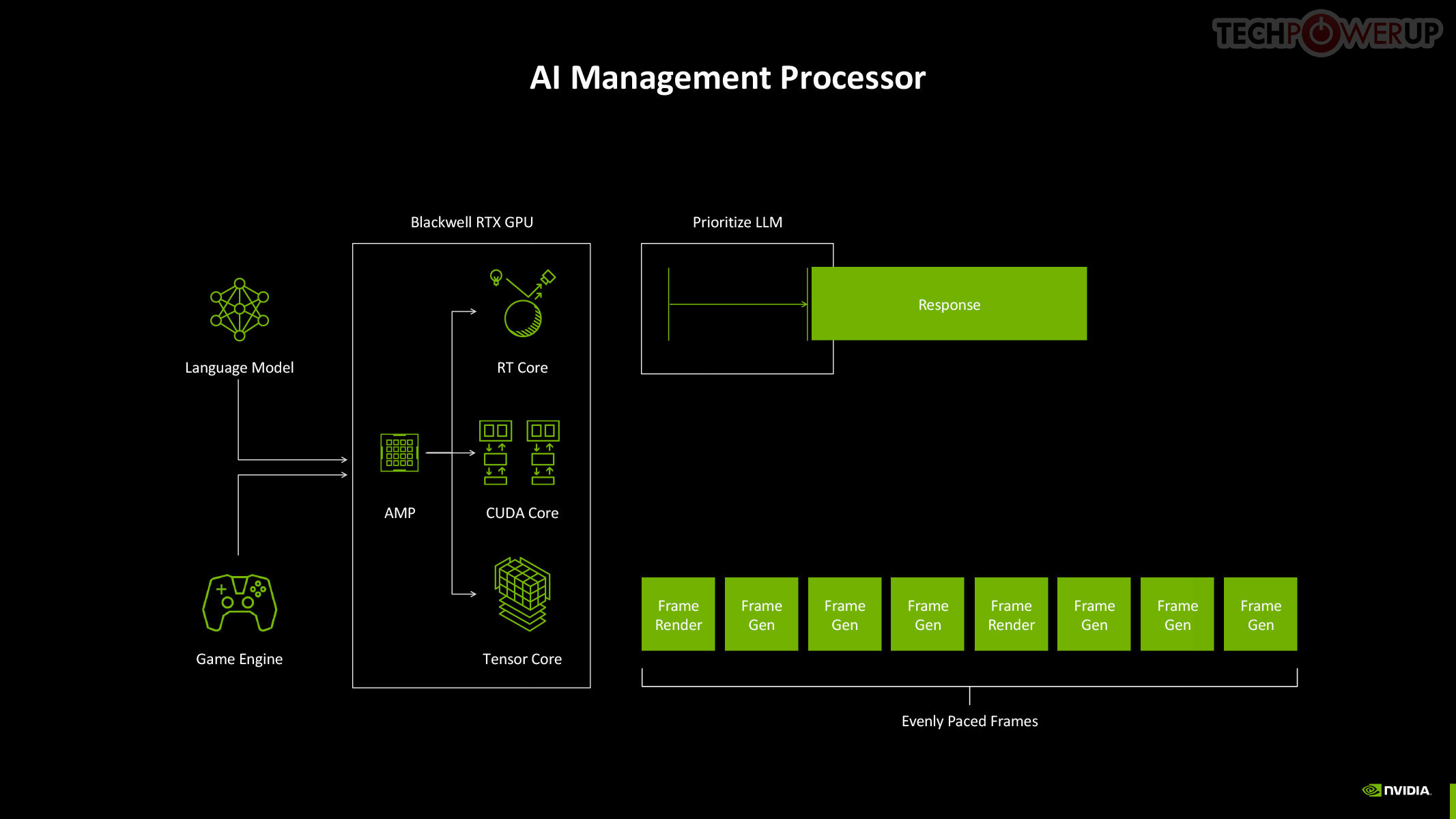
The new 5th Gen Tensor core introduces support for FP4 data format (1/8 precision) to fast moving atomic workloads, providing 32 times the throughput of the very first Tensor core introduced with the Volta architecture. Over the generations, AI models leveraged lesser precision data formats, and sparsity, to improve performance. The AI management processor (AMP) is what enables simultaneous AI and graphics workloads at the highest levels of the GPU, so it could be simultaneously rendering real time graphics for a game, while running an LLM, without either affecting the performance of the other. AMP is a specialized hardware scheduler for all the AI acceleration resources on the silicon. This plays a crucial role for DLSS 4 multi-frame generation to work.
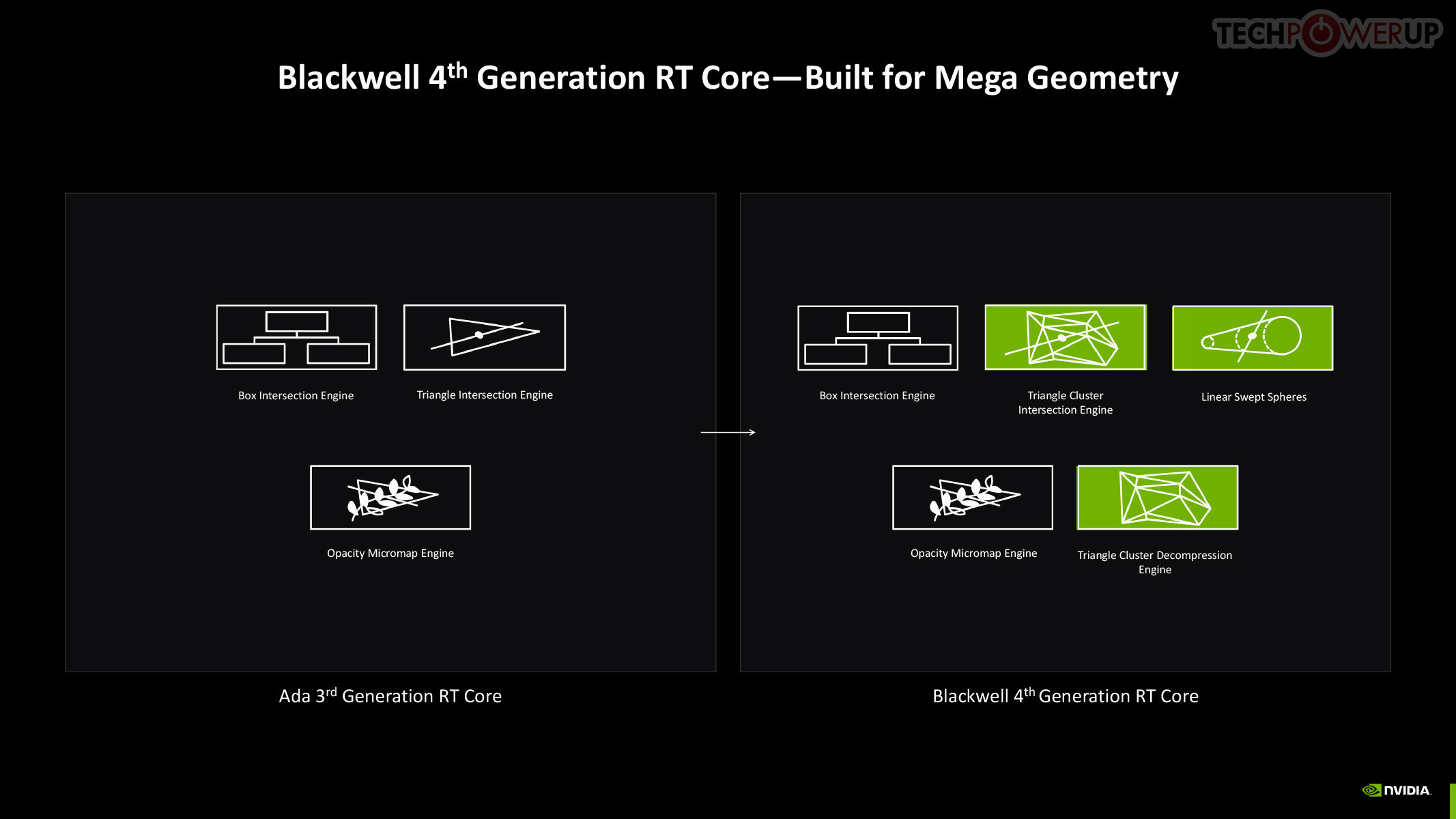
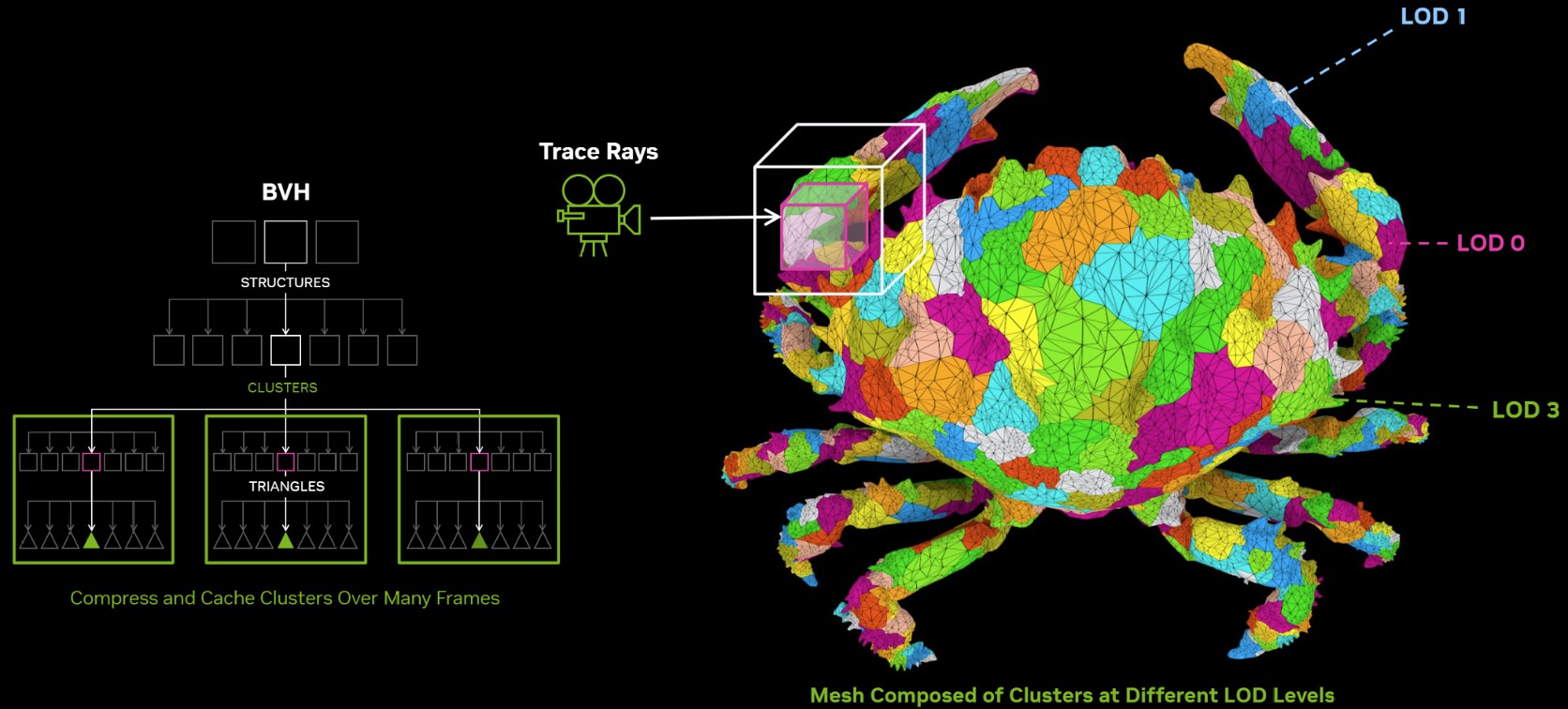
The 4th Gen RT core not just offers a generational increase in ray testing and ray intersection performance, which lowers the performance cost of enabling path tracing and ray traced effects; but also offers a potential generational leap in performance with the introduction of Mega Geometry. This allows for ray traced objects with extremely high polygon counts, increasing their detail. Poly count and ray tracing present linear increases in performance costs, as each triangle has to intersect with a ray, and there should be sufficient rays to intersect with each of them. This is achieved by adopting clusters of triangles in an object as first-class primitives, and cluster-level acceleration structures. The new RT cores introduce a component called a triangle cluster intersection engine, designed specifically for handling mega geometry. The integration of a triangle cluster compression format and a lossless decompression engine allows for more efficient processing of complex geometry.


The GB202 and the rest of the GeForce Blackwell GPU family is built on the exact same TSMC "NVIDIA 4N" foundry node, which is actually 5 nm, as previous-generation Ada, so NVIDIA directed efforts to finding innovative new ways to manage power and thermals. This is done through a re-architected power management engine that relies on clock gating, power gating, and rail gating of the individual GPCs and other top-level components. It also worked on the speed at which the GPU makes power-related decisions.
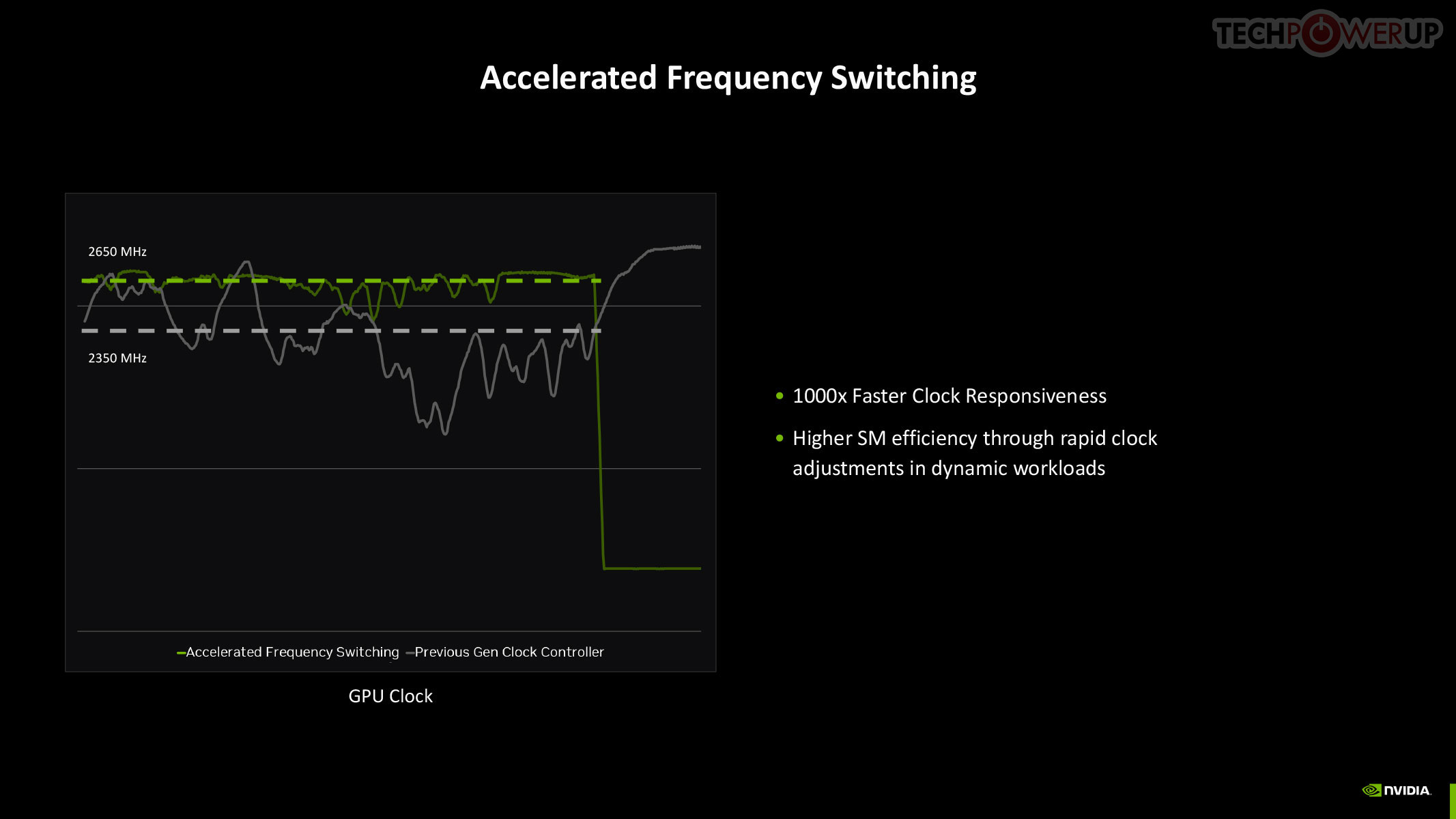
The quickest way to drop power is by adjusting the GPU clock speed, and with Blackwell, NVIDIA introduced a means for rapid clock adjustments at the SM-level.
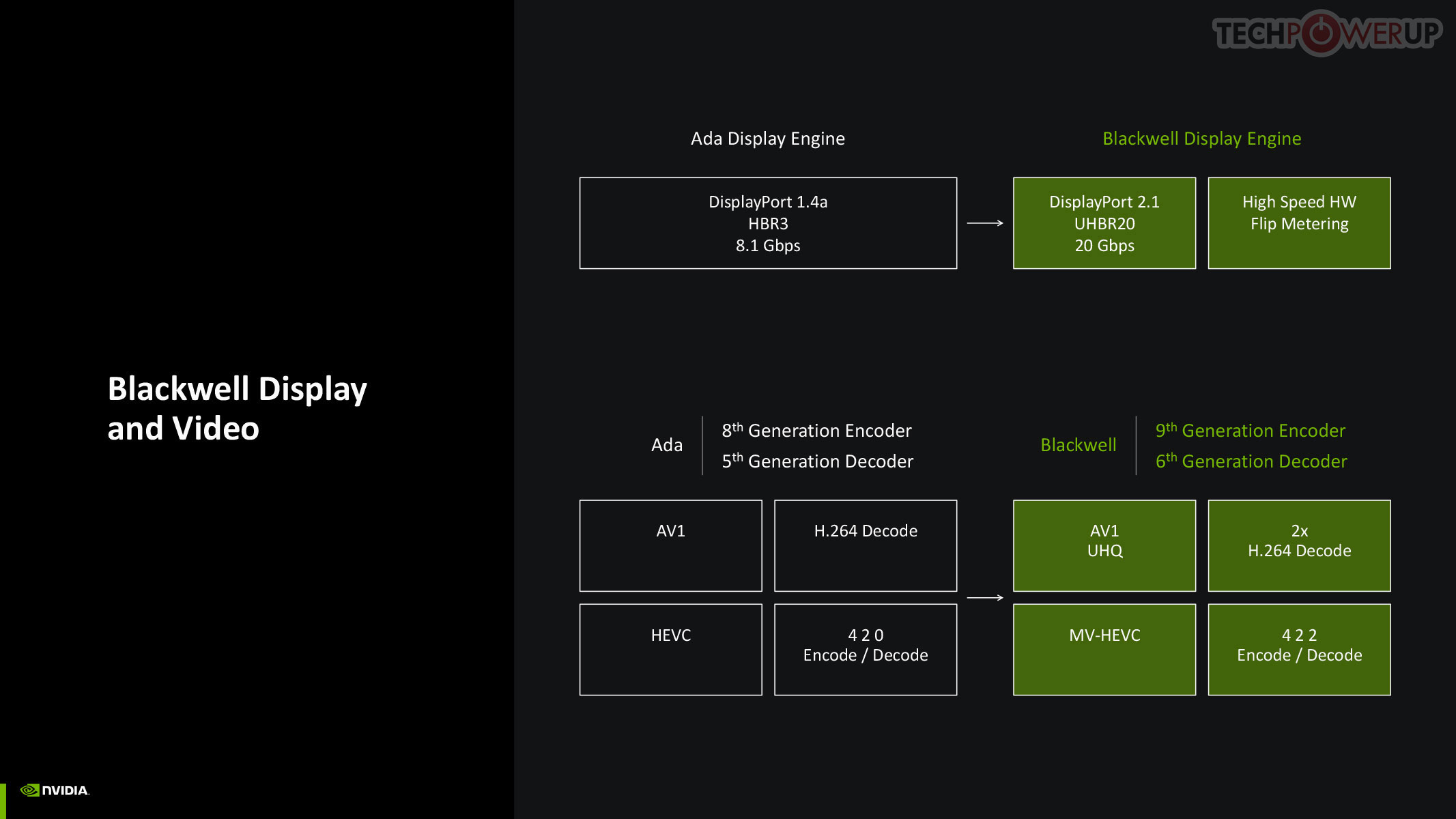
NVIDIA updated both the display engine and the media engine of Blackwell over the previous generation Ada, which drew some flack for holding on to older display I/O standards such as DisplayPort 1.4, while AMD and Intel had moved on to DisplayPort 2.1. The good news is that Blackwell supports DP 2.1 with UHBR20, enabling 8K 60 Hz with a single cable. The company also updated NVDEC and NVENC, which now support AV1 UHQ, double the H.264 decode performance, MV-HEVC, and 4:2:2 formats.
Feb 26th, 2025 08:58 EST
change timezone
Latest GPU Drivers
New Forum Posts
- GameTechBench GPU benchmark is already out! (272)
- Microcenter GPU Stock status (15)
- Are the two M.2 pcie Gen4 x4 slots on my Zen 4 8845HS Socket FP8 Mini-PC equal? (1)
- Video BIOS Collection - search filters (15)
- TPU's Nostalgic Hardware Club (20005)
- Which API call returns the nvidia ROP count? (6)
- Gaming AM5 Board (Swapping from Intel) (3)
- 4070 Super, Proart or Gaming X Slim? (1)
- Corsair SF750 750 W (1)
- Nvidia's GPU market share hits 90% in Q4 2024 (gets closer to full monopoly) (643)
Popular Reviews
- Corsair Xeneon 34WQHD240-C Review - Pretty In White
- ASUS GeForce RTX 5070 Ti TUF OC Review
- Corsair Virtuoso MAX Wireless Review
- MSI GeForce RTX 5070 Ti Ventus 3X OC Review
- MSI GeForce RTX 5070 Ti Vanguard SOC Review
- MSI GeForce RTX 5070 Ti Gaming Trio OC+ Review
- darkFlash DY470 Review
- AMD Ryzen 7 9800X3D Review - The Best Gaming Processor
- Gigabyte X870 Aorus Elite WiFi 7 Review
- Gigabyte GeForce RTX 5090 Gaming OC Review
Controversial News Posts
- NVIDIA GeForce RTX 50 Cards Spotted with Missing ROPs, NVIDIA Confirms the Issue, Multiple Vendors Affected (495)
- AMD Radeon 9070 XT Rumored to Outpace RTX 5070 Ti by Almost 15% (304)
- AMD Plans Aggressive Price Competition with Radeon RX 9000 Series (273)
- AMD Radeon RX 9070 and 9070 XT Listed On Amazon - One Buyer Snags a Unit (247)
- NVIDIA Investigates GeForce RTX 50 Series "Blackwell" Black Screen and BSOD Issues (241)
- Edward Snowden Lashes Out at NVIDIA Over GeForce RTX 50 Pricing And Value (241)
- AMD Denies Radeon RX 9070 XT $899 USD Starting Price Point Rumors (239)
- AMD Radeon RX 9070 and 9070 XT Official Performance Metrics Leaked, +42% 4K Performance Over Radeon RX 7900 GRE (186)