 61
61
MSI GTX 1050 Ti Gaming X 4 GB Review
Packaging & Contents »Architecture
The GeForce GTX 1050 Ti and its sibling, the GTX 1050, are based on NVIDIA's smallest silicon from the "Pascal" family, the GP107. With a die-area of 132 mm² and a transistor count of 3.3 billion, this chip is tiny, having been built with very clear cost objectives in mind.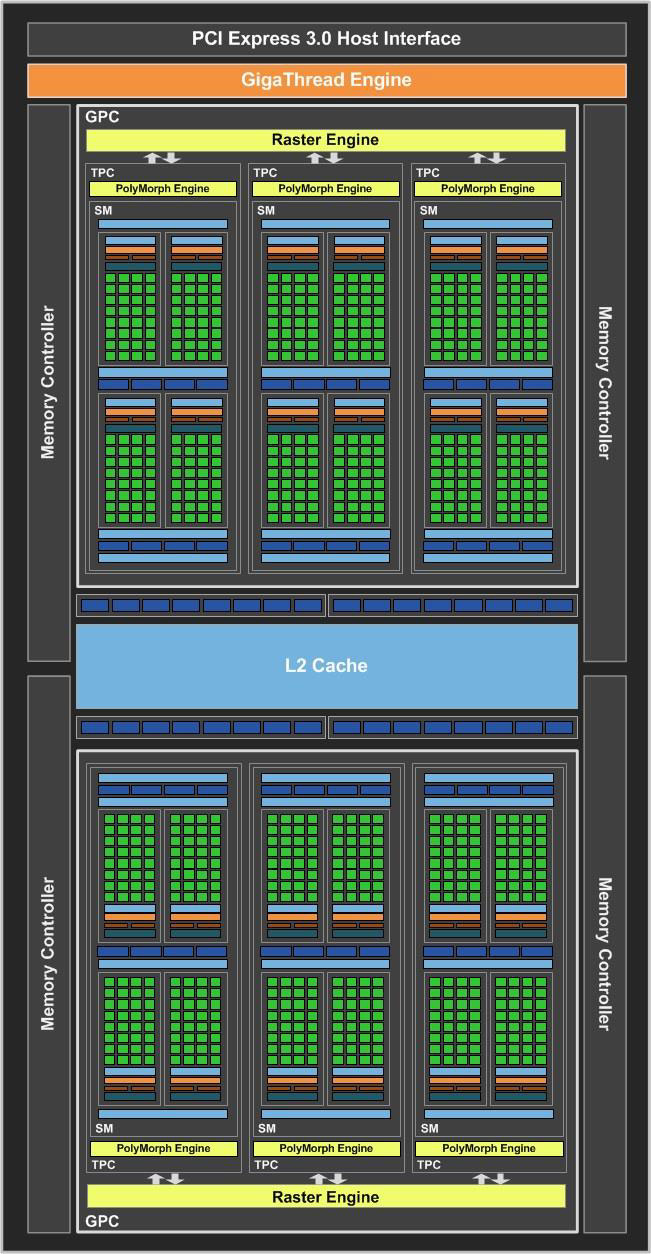


NVIDIA has still made sure that unless a design choice doesn't substantially deviate from its cost objectives, it will implement it. A good example of this is the fact that the GP107 silicon, despite featuring just 768 CUDA cores spread across six streaming multiprocessors (SMs), is split into two graphics processing clusters (GPCs) of three SMs, each.
The decision to spread six streaming multiprocessors across two GPCs means that three SMs share a Raster Engine, specialized units with geometry/tessellation units. The streaming multiprocessor, the indivisible subunit of the GPU, is identical in design to those featured on NVIDIA's fastest TITAN X Pascal graphics cards. Each packs 128 CUDA cores, a PolyMorph Engine, and dedicated geometry processing components. The two GPCs are cushioned by a 1 MB L2 cache wired to a new-generation GigaThread Engine - the GPU's traffic cop - and a 128-bit wide GDDR5 memory interface.


At its reference clock speeds, the GPU has 112 GB/s of memory bandwidth at its disposal. This is bolstered by NVIDIA's lossless memory compression tech, which should increase effective bandwidth in a small but significant way. On the GTX 1080, NVIDIA claims this gain to be 20 percent in the best-case scenario. Something like that would certainly come in handy for the GTX 1050 Ti.


The "Pascal" architecture supports Asynchronous Compute as standardized by Microsoft. It adds to that with its own variation of the concept with "Dynamic Load Balancing."
Mar 19th, 2025 19:31 EDT
change timezone
Latest GPU Drivers
New Forum Posts
- Is RX 9070 VRAM temperature regular value or hotspot? (32)
- HalfLife2 RTX Demo Is out! (175)
- Your PC ATM (35273)
- Windows 11 General Discussion (5876)
- Old Gamer Memory Upgrade Worth It? (12)
- anyone replace capacitors on a component? (5)
- Why is coil whine still a nuisance? (37)
- WCG Daily Numbers (12805)
- Intel to AMD upgrade, re-using 2x24Gb memory? (25)
- PCI 4.0 16x slot reported as a PCI 5.0 8x with the AMD 9070 XT Reaper GPU (35)
Popular Reviews
- ASRock Radeon RX 9070 XT Taichi OC Review - Excellent Cooling
- Corsair SF750 750 W Review
- Sapphire Radeon RX 9070 XT Nitro+ Review - Beating NVIDIA
- AMD Ryzen 9 9950X3D Review - Great for Gaming and Productivity
- MSI GeForce RTX 5070 Gaming Trio OC Review
- XFX Radeon RX 9070 XT Mercury OC Magnetic Air Review
- Kioxia Exceria Plus G4 2 TB Review - Energy-Efficient PCIe Gen 5
- ASUS Radeon RX 9070 TUF OC Review
- ASUS GeForce RTX 5090 TUF Review
- be quiet! Pure Base 501 LX Review
Controversial News Posts
- NVIDIA GeForce RTX 50 Cards Spotted with Missing ROPs, NVIDIA Confirms the Issue, Multiple Vendors Affected (519)
- AMD RDNA 4 and Radeon RX 9070 Series Unveiled: $549 & $599 (260)
- AMD Mentions Sub-$700 Pricing for Radeon RX 9070 GPU Series, Looks Like NV Minus $50 Again (250)
- NVIDIA Investigates GeForce RTX 50 Series "Blackwell" Black Screen and BSOD Issues (244)
- AMD Radeon RX 9070 and 9070 XT Official Performance Metrics Leaked, +42% 4K Performance Over Radeon RX 7900 GRE (195)
- AMD Radeon RX 9070-series Pricing Leaks Courtesy of MicroCenter (158)
- MSI Doesn't Plan Radeon RX 9000 Series GPUs, Skips AMD RDNA 4 Generation Entirely (140)
- Microsoft Introduces Copilot for Gaming (123)