 519
519
NVIDIA GeForce RTX 5090 Founders Edition Review - The New Flagship
(519 Comments) »Introduction
NVIDIA GeForce RTX 5090 Blackwell heralds a new chapter in 3D graphics, and we have with us the sleek new RTX 5090 Founders Edition graphics card. Gaming graphics had several major milestones over the past 20 years, beginning with raster 3D, pixel- and vertex shaders, and real time ray tracing; now NVIDIA plans to introduce the next major milestone—neural rendering. By now you're likely aware of generative AI, and its ability to conjure up richly detailed images and video. NVIDIA and its allied researchers in 3D graphics have discovered a way give generative AI a more active role in real time graphics, with the introduction of neural shaders. The new Blackwell graphics architecture, besides bringing in generational improvements to performance and efficiency, also introduces DLSS 4, and with it, an exclusive new technology called Multi Frame Generation. The company claims to have figured out a way to get AI to not just create every other frame, but up to four frames following a conventionally rendered frame. This is a bold claim, but if NVIDIA pulls it off, the RTX 50-series will really turn the page on what's possible with current technology, and maybe even tempt game developers to give us our next Crysis.

The new GeForce Blackwell graphics architecture sees advancements to all six key components of the GPU. The CUDA cores, or the GPU's main unified shader engines, not just introduce generational IPC increases, but are also redesigned to accelerate neural shaders. The 4th generation RT core, besides continuing to lower the performance cost of ray tracing compared to the previous generation, comes with optimization for mega geometry—ray traced objects with much more complex geometry (more surfaces for rays to interact with). The 5th generation Tensor cores lay the groundwork for not just for neural rendering, but also introduce support for newer data formats, including FP4. NVIDIA has given all components involved in AI acceleration a dedicated management engine called AMP. Next up, Blackwell also updates the media acceleration engines; and gives its display I/O a much-needed update, with support for DisplayPort 2.1 and UHBR20. Lastly, Blackwell is the first GPU to use PCI-Express Gen 5 and GDDR7 memory standards. There are significant increases in memory bandwidth across the board.
What's interesting, though, is that while GeForce Blackwell innovates in almost every direction, the entire line of GPUs is built on the same exact foundry node as the RTX 40-series Ada generation, a specialized variant of the 5 nm EUV node at TSMC that the foundry co-engineered with NVIDIA, called TSMC 4N. Any generational gains in performance-per-watt are purely from the architecture, and new power management technologies introduced with Blackwell, not from the node.
The GeForce RTX 5090 is the company's flagship graphics card in this generation, and is based on the gargantuan 5 nm GB202 monolithic silicon. The SKU enables 170 out of 192 streaming multiprocessors (SM) present on the chip, achieving 21,760 CUDA cores, 170 RT cores, 680 Tensor cores, 680 TMUs, and 176 ROPs. The memory sub-system sees a major generational upgrade. The card comes with 32 GB of GDDR7 memory running at 28 Gbps. NVIDIA has widened the memory bus to 512-bit, giving the RTX 5090 an enormous 1.792 TB/s of memory bandwidth—the kind you expect from HBM setups on AI GPUs. These massive increases in memory size and bandwidth are crucial for the GPU to pull off high-geometry ray tracing, and neural rendering.
NVIDIA didn't limit its engineering to just the GB202 silicon, and its various software technologies such as DLSS 4 and Reflex 2; but also the hard product itself. The Founders Edition card is a remarkable piece of engineering. It just as long and tall as the RTX 4090 Founders Edition, but just two-thirds its thickness (2-slot versus 3-slot). This is made possible by the new Double Flow Through cooling solution that compacts and pushes the PCB out of the way to create two nearly unrestricted channels of airflow for the card's two fans.
The NVIDIA GeForce RTX 5090 Founders Edition comes with close to reference clock speeds of 2407 MHz GPU boost, and 28 Gbps (GDDR7-effective) memory. With these settings, the total graphics power (TGP), the de facto power limit of the card, shoots all the way up to 575 W, nearing the design limits of the 600 W-capable 12V-2x6 power connector. NVIDIA is pricing the GeForce RTX 5090 Founders Edition at the SKU's baseline price of USD $1,999. This is a steep increase in price over the RTX 4090, which started at $1,599.
| Price | Cores | ROPs | Core Clock | Boost Clock | Memory Clock | GPU | Transistors | Memory | |
|---|---|---|---|---|---|---|---|---|---|
| RTX 3080 | $420 | 8704 | 96 | 1440 MHz | 1710 MHz | 1188 MHz | GA102 | 28000M | 10 GB, GDDR6X, 320-bit |
| RTX 4070 | $490 | 5888 | 64 | 1920 MHz | 2475 MHz | 1313 MHz | AD104 | 35800M | 12 GB, GDDR6X, 192-bit |
| RX 7800 XT | $440 | 3840 | 96 | 2124 MHz | 2430 MHz | 2425 MHz | Navi 32 | 28100M | 16 GB, GDDR6, 256-bit |
| RX 6900 XT | $450 | 5120 | 128 | 2015 MHz | 2250 MHz | 2000 MHz | Navi 21 | 26800M | 16 GB, GDDR6, 256-bit |
| RX 6950 XT | $630 | 5120 | 128 | 2100 MHz | 2310 MHz | 2250 MHz | Navi 21 | 26800M | 16 GB, GDDR6, 256-bit |
| RTX 3090 | $900 | 10496 | 112 | 1395 MHz | 1695 MHz | 1219 MHz | GA102 | 28000M | 24 GB, GDDR6X, 384-bit |
| RTX 4070 Super | $590 | 7168 | 80 | 1980 MHz | 2475 MHz | 1313 MHz | AD104 | 35800M | 12 GB, GDDR6X, 192-bit |
| RX 7900 GRE | $530 | 5120 | 160 | 1880 MHz | 2245 MHz | 2250 MHz | Navi 31 | 57700M | 16 GB, GDDR6, 256-bit |
| RTX 4070 Ti | $700 | 7680 | 80 | 2310 MHz | 2610 MHz | 1313 MHz | AD104 | 35800M | 12 GB, GDDR6X, 192-bit |
| RTX 4070 Ti Super | $750 | 8448 | 96 | 2340 MHz | 2610 MHz | 1313 MHz | AD103 | 45900M | 16 GB, GDDR6X, 256-bit |
| RX 7900 XT | $620 | 5376 | 192 | 2000 MHz | 2400 MHz | 2500 MHz | Navi 31 | 57700M | 20 GB, GDDR6, 320-bit |
| RTX 3090 Ti | $1000 | 10752 | 112 | 1560 MHz | 1950 MHz | 1313 MHz | GA102 | 28000M | 24 GB, GDDR6X, 384-bit |
| RTX 4080 | $940 | 9728 | 112 | 2205 MHz | 2505 MHz | 1400 MHz | AD103 | 45900M | 16 GB, GDDR6X, 256-bit |
| RTX 4080 Super | $990 | 10240 | 112 | 2295 MHz | 2550 MHz | 1438 MHz | AD103 | 45900M | 16 GB, GDDR6X, 256-bit |
| RX 7900 XTX | $820 | 6144 | 192 | 2300 MHz | 2500 MHz | 2500 MHz | Navi 31 | 57700M | 24 GB, GDDR6, 384-bit |
| RTX 4090 | $2400 | 16384 | 176 | 2235 MHz | 2520 MHz | 1313 MHz | AD102 | 76300M | 24 GB, GDDR6X, 384-bit |
| RTX 5090 | $2000 | 21760 | 176 | 2017 MHz | 2407 MHz | 1750 MHz | GB202 | 92200M | 32 GB, GDDR7, 512-bit |
NVIDIA Blackwell Architecture
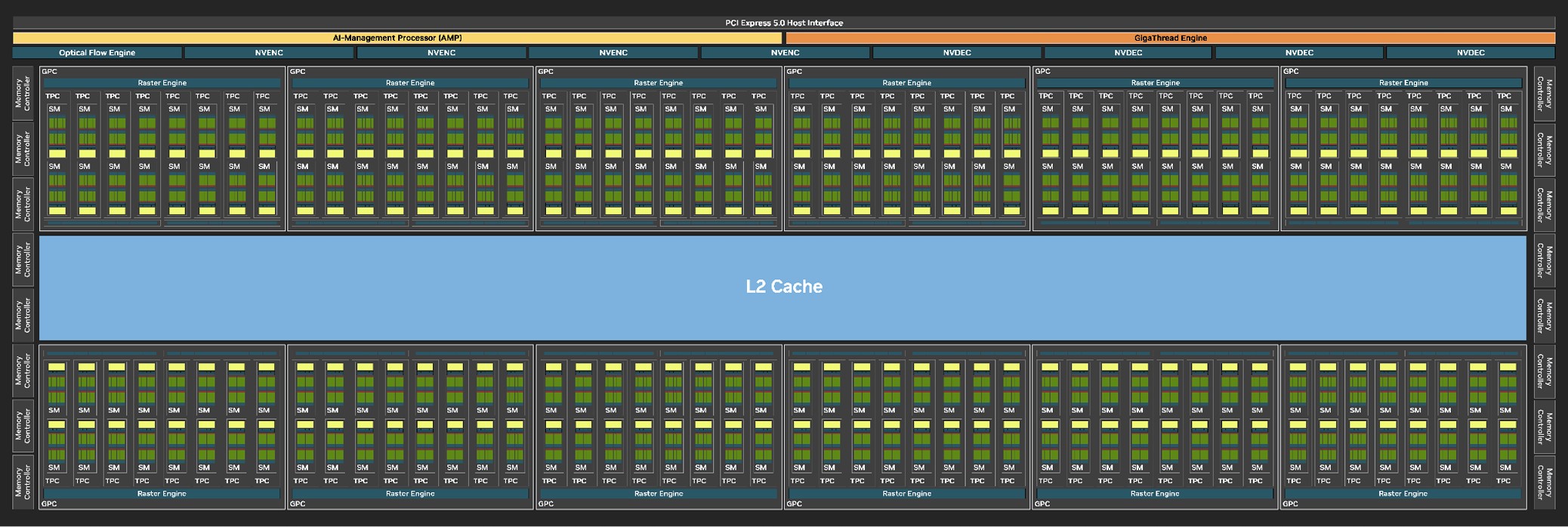
The GeForce Blackwell graphics architecture heralds NVIDIA's 4th generation of RTX, the late-2010s re-invention of the modern GPU that sees a fusion of real time ray traced objects with conventional raster 3D graphics. With Blackwell, NVIDIA is helping add another dimension, neural rendering, the ability for the GPU to leverage a generative AI to create portions of a frame. This is different from DLSS, where an AI model is used to reconstruct details in an upscaled frame based on its training date, temporal frames, and motion vectors. At the heart of the GeForce RTX 5090 we are reviewing today is the mammoth 5 nm GB202 silicon. This is one of the largest monolithic dies ever designed by NVIDIA, measuring 750 mm², compared to the 608.5 mm² of the AD102 die. The process is unchanged between the two generations—it's still an NVIDIA-specific variant of TSMC 5 nm EUV, dubbed TSMC 4N. The GB202 rocks 92.2 billion transistors, a 20% increase over the AD102.
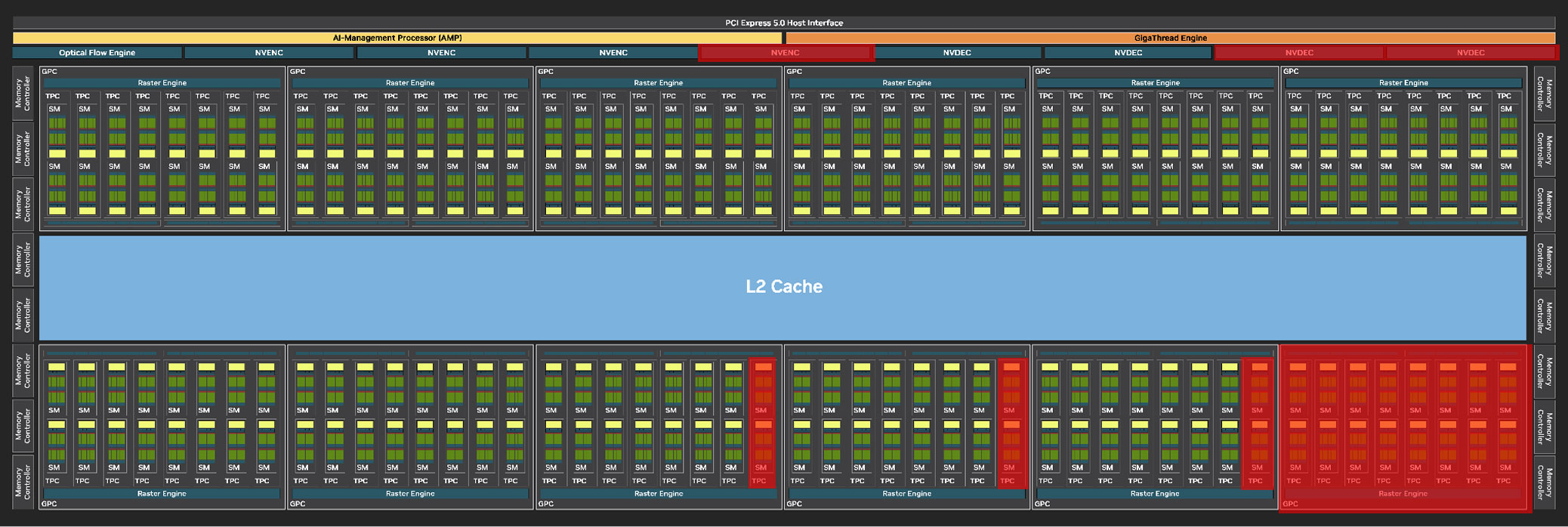
The GB202 silicon is laid out essentially in the same component hierarchy as past generations of NVIDIA GPUs, but with a few notable changes. The GPU features a PCI-Express 5.0 x16, making it the first gaming GPU to do so. PCIe Gen 5 has been around since Intel's 12th Gen Core "Alder Lake" and AMD's Ryzen 7000 "Zen 4," so there is a sizable install-base of systems that can take advantage of it. The GPU is of course compatible with older generations of PCIe. Whether this affects performance is a question we cover in our separate RTX 5090 PCIe Scaling Article. The GB202 is also the first GPU to implement the new GDDR7 memory standard, which doubles speeds over GDDR6 while lowering the energy cost of bandwidth. NVIDIA left no half-measures with the GB202, and gave it a broad 512-bit GDDR7 memory interface. On the RTX 5090, this is configured with 32 GB of 28 Gbps GDDR7. Upcoming RTX 50-series SKUs could have narrower memory interfaces but with higher memory speeds, and some professional graphics cards based on the GB202 could even use high-density memory chips.
The GigaThread Engine is the main graphics rendering workload allocation logic on the GB202, but there's a new addition, a dedicated serial processor for managing all AI acceleration resources on the GPU, NVIDIA calls this AMP (AI management processor). Other components at the global level are the Optical Flow Processor, a component involved in older versions of DLSS frame generation and for video encoding; and a vast media acceleration engine consisting of four NVENC encode accelerators, and four NVDEC decode accelerators. The new 9th Gen NVENC video encode accelerators come with 4:2:2 AV1 and HEVC encoding support. The RTX 5090 has 3 out of 4 NVENC and 2 out of 4 NVDEC units enabled. The central region of the GPU has the single largest common component, the 128 MB L2 cache. The RTX 5090 is configured with 96 MB of it.
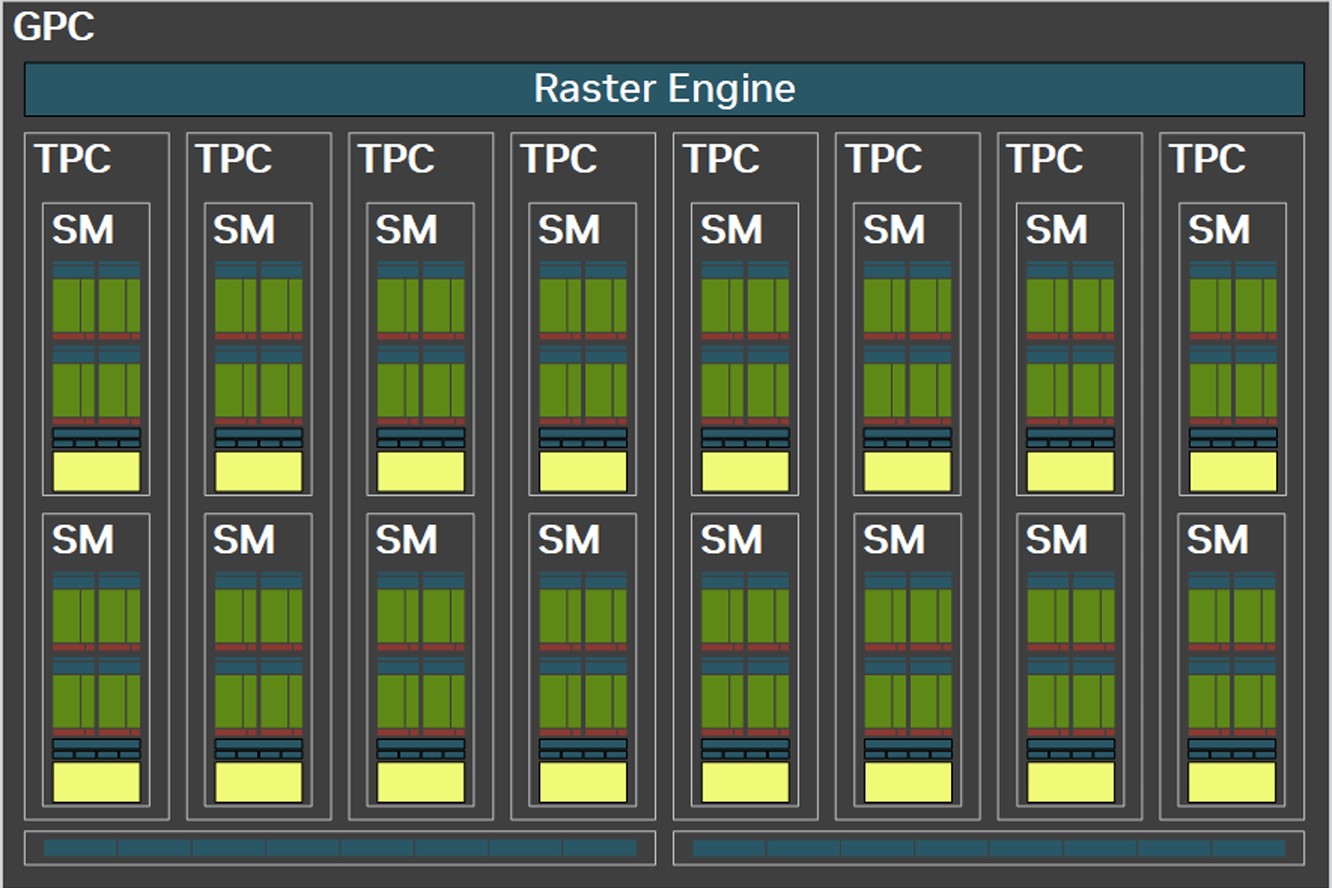
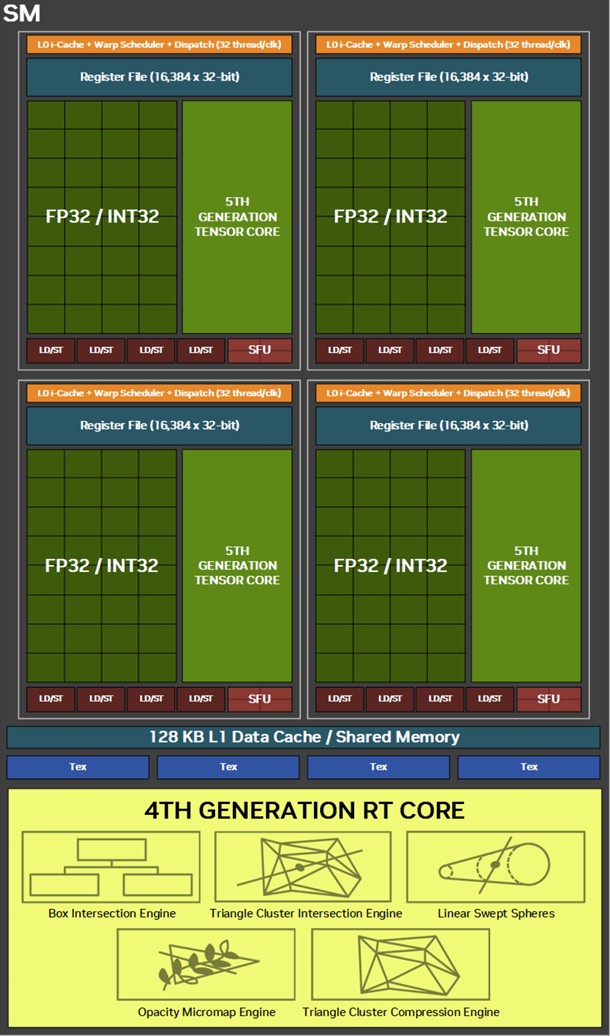
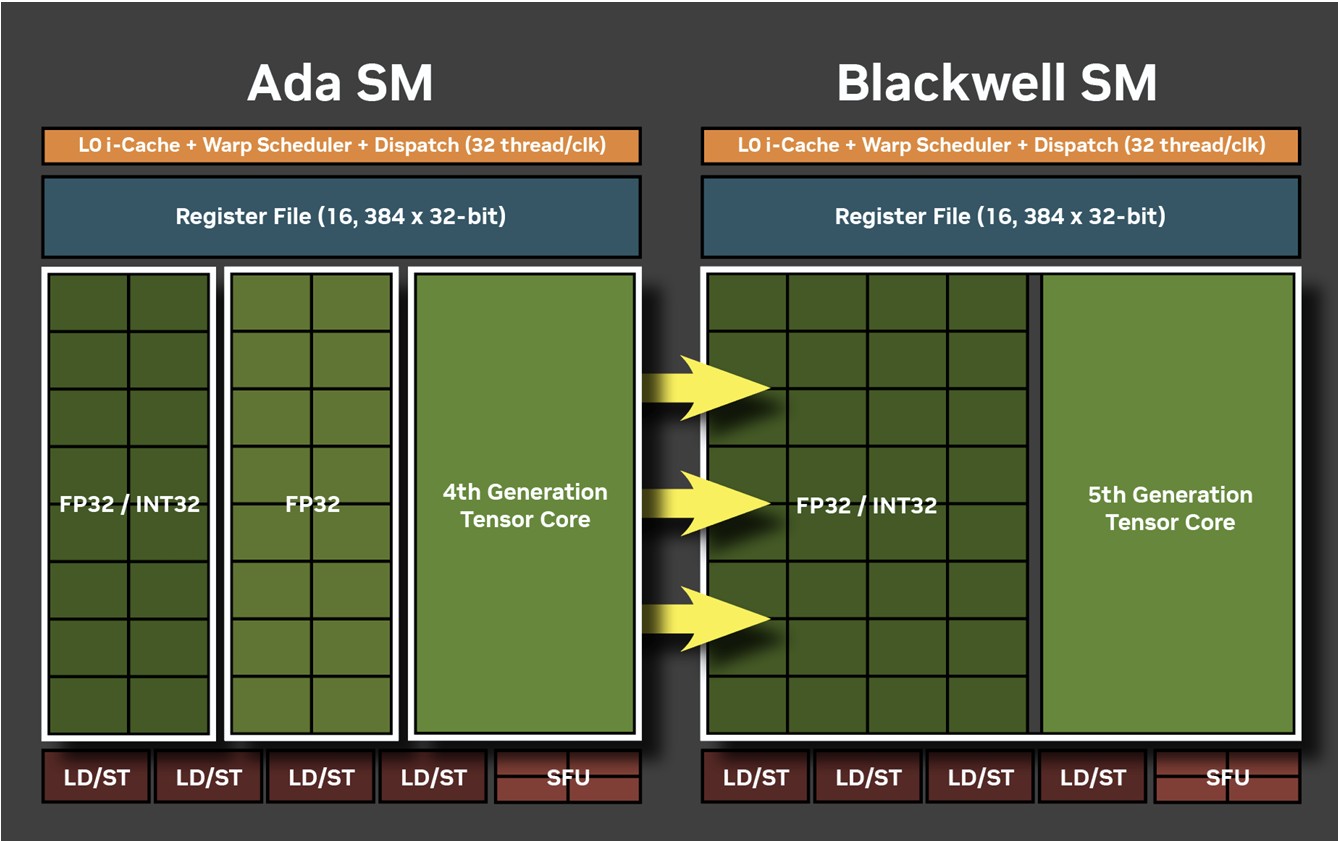
Each graphics processing cluster (GPC) is a subdivision of the GPU with nearly all components needed for graphics rendering. On the GB202, a GPC consists of 16 streaming multiprocessors (SM) across 8 texture processing clusters (TPCs), and a raster engine consisting of 16 ROPs. Each SM contains 128 CUDA cores. Unlike the Ada generation SM that each had 64 FP32+INT32 and 64 purely-FP32 SIMD units, the new Blackwell generation SM features concurrent FP32+INT32 capability on all 128 SIMD units. These 128 CUDA cores are arranged in four slices, each with a register file, a level-0 instruction cache, a warp scheduler, two sets of load-store units, and a special function unit (SFU) handling some special math functions such as trigonometry, exponents, logarithms, reciprocals, and square-root. The four slices share a 128 KB L1 data cache, and four TMUs. The most exotic components of the Blackwell SM are the four 5th Gen Tensor cores, and a 4th Gen RT core.
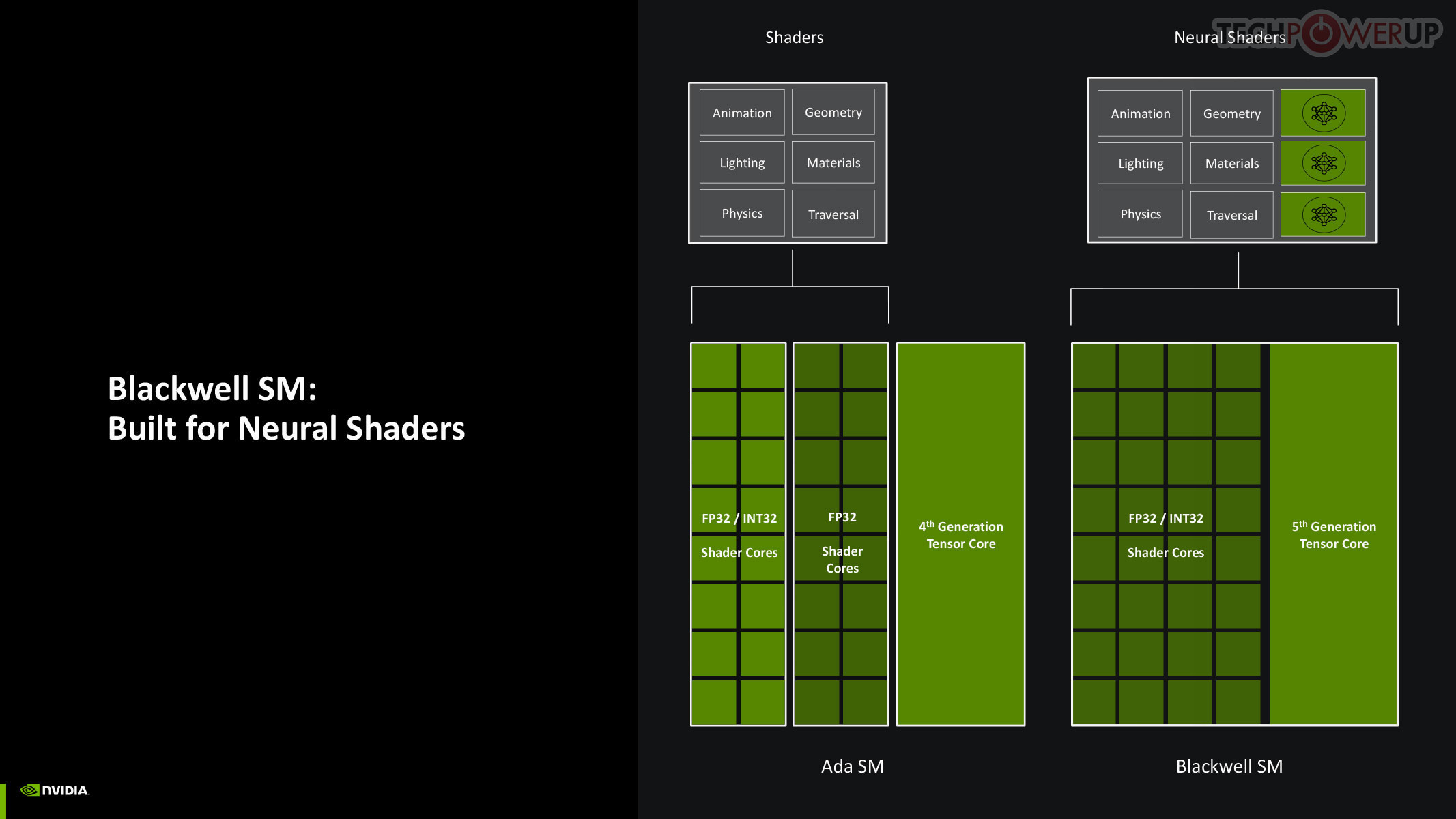
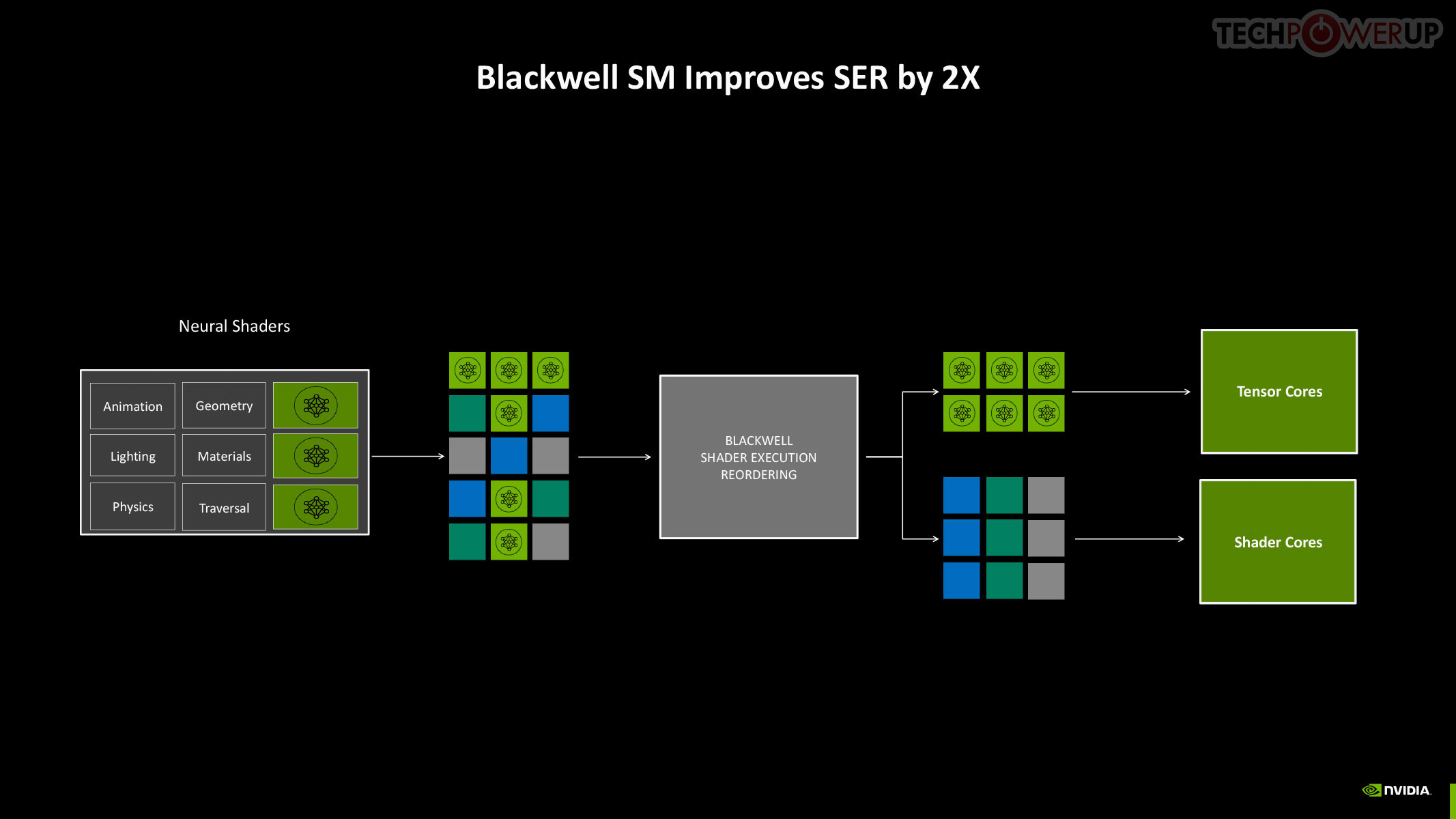
Perhaps the biggest change to the way the SM handles work introduced with Blackwell is the concept of neural shaders—treating portions of the graphics rendering workload done by a generative AI model as shaders. Microsoft has laid the groundwork for standardization of neural shaders with its Cooperative Vectors API, in the latest update to DirectX 12. The Tensor cores are now accessible for workloads through neural shaders, and the shader execution reordering (SER) engine of the Blackwell SM is able to more accurately reorder workloads for the CUDA cores and the Tensor core in an SM.
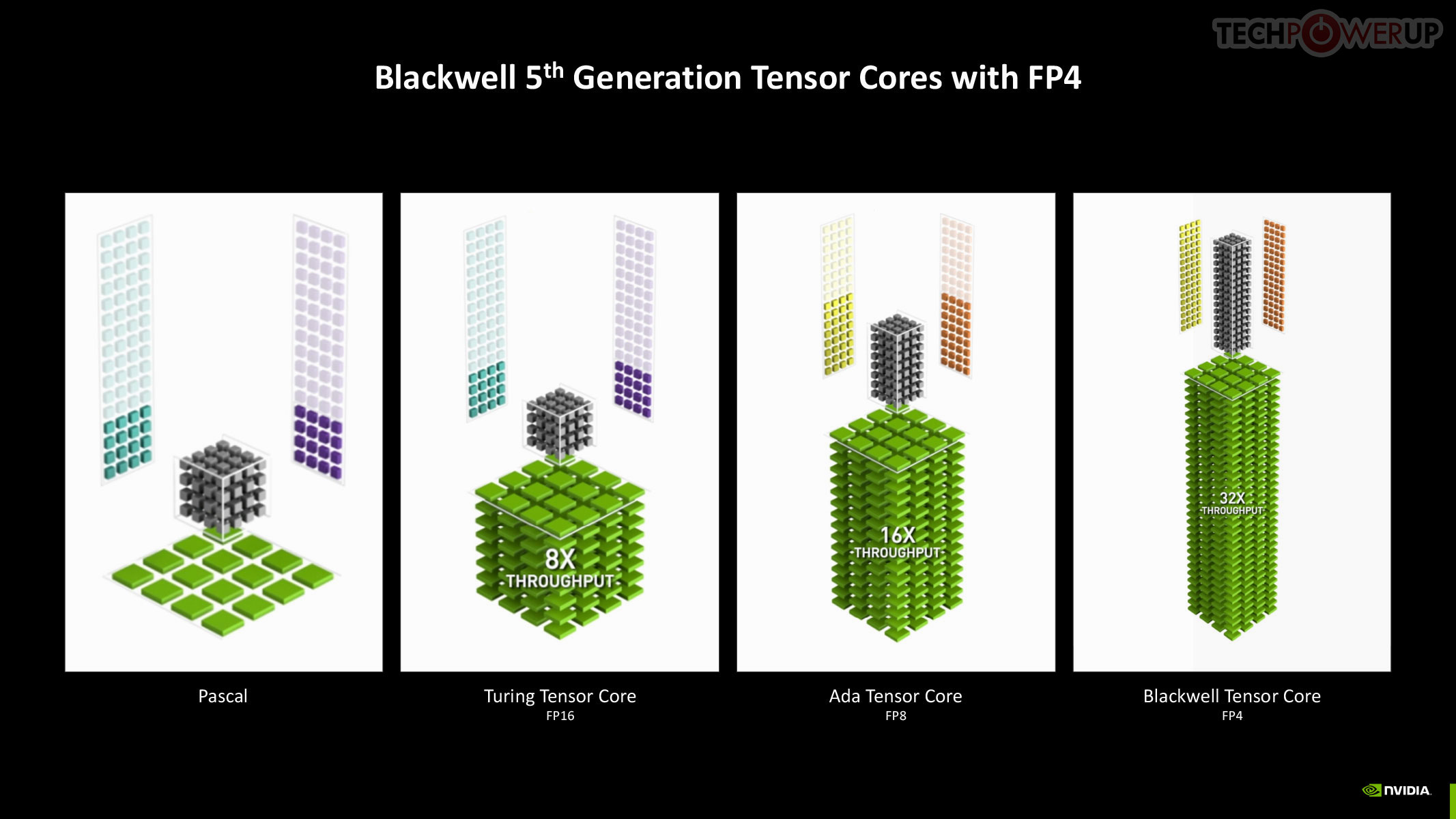
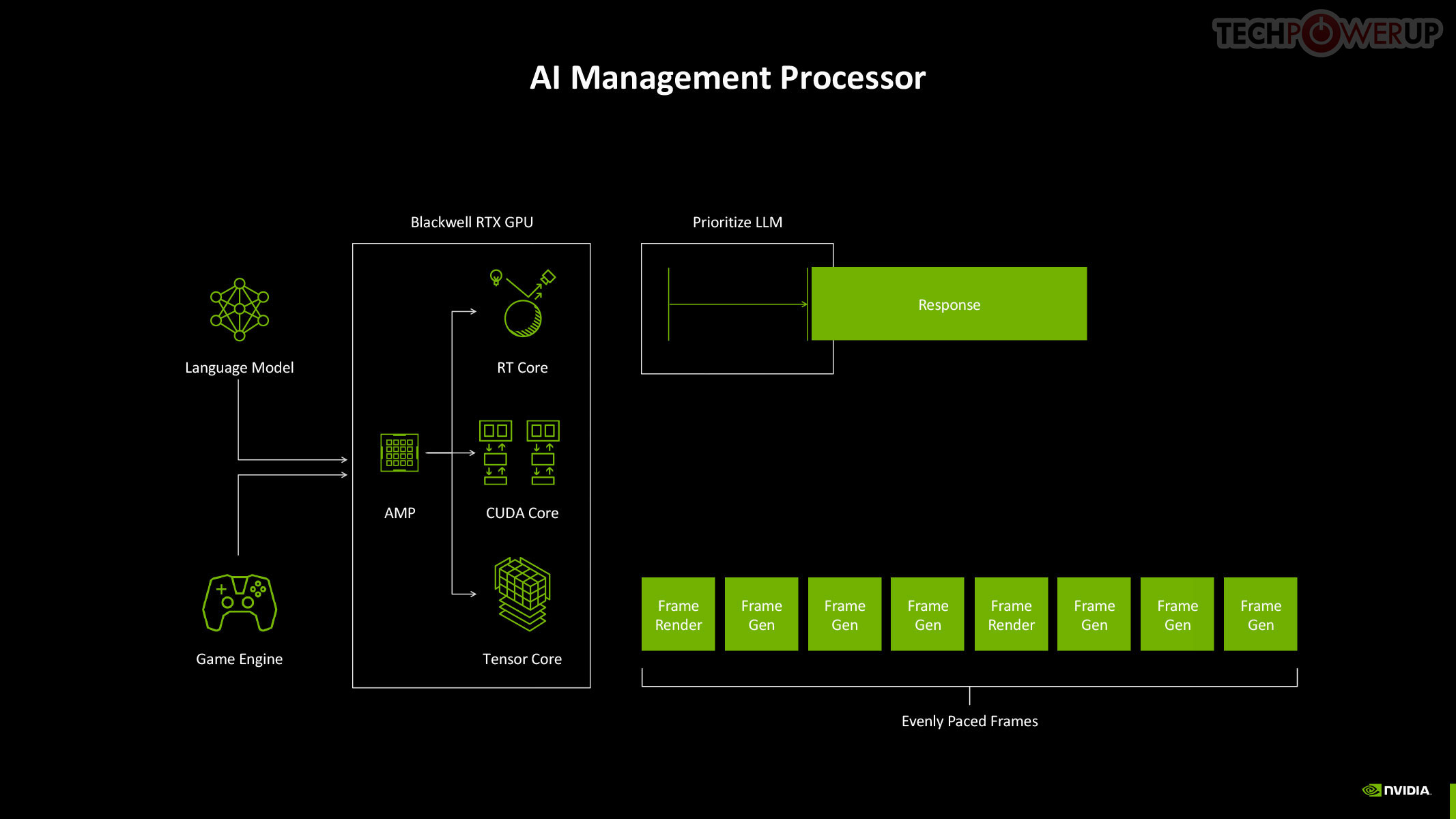
The new 5th Gen Tensor core introduces support for FP4 data format (1/8 precision) to fast moving atomic workloads, providing 32 times the throughput of the very first Tensor core introduced with the Volta architecture. Over the generations, AI models leveraged lesser precision data formats, and sparsity, to improve performance. The AI management processor (AMP) is what enables simultaneous AI and graphics workloads at the highest levels of the GPU, so it could be simultaneously rendering real time graphics for a game, while running an LLM, without either affecting the performance of the other. AMP is a specialized hardware scheduler for all the AI acceleration resources on the silicon. This plays a crucial role for DLSS 4 multi-frame generation to work.
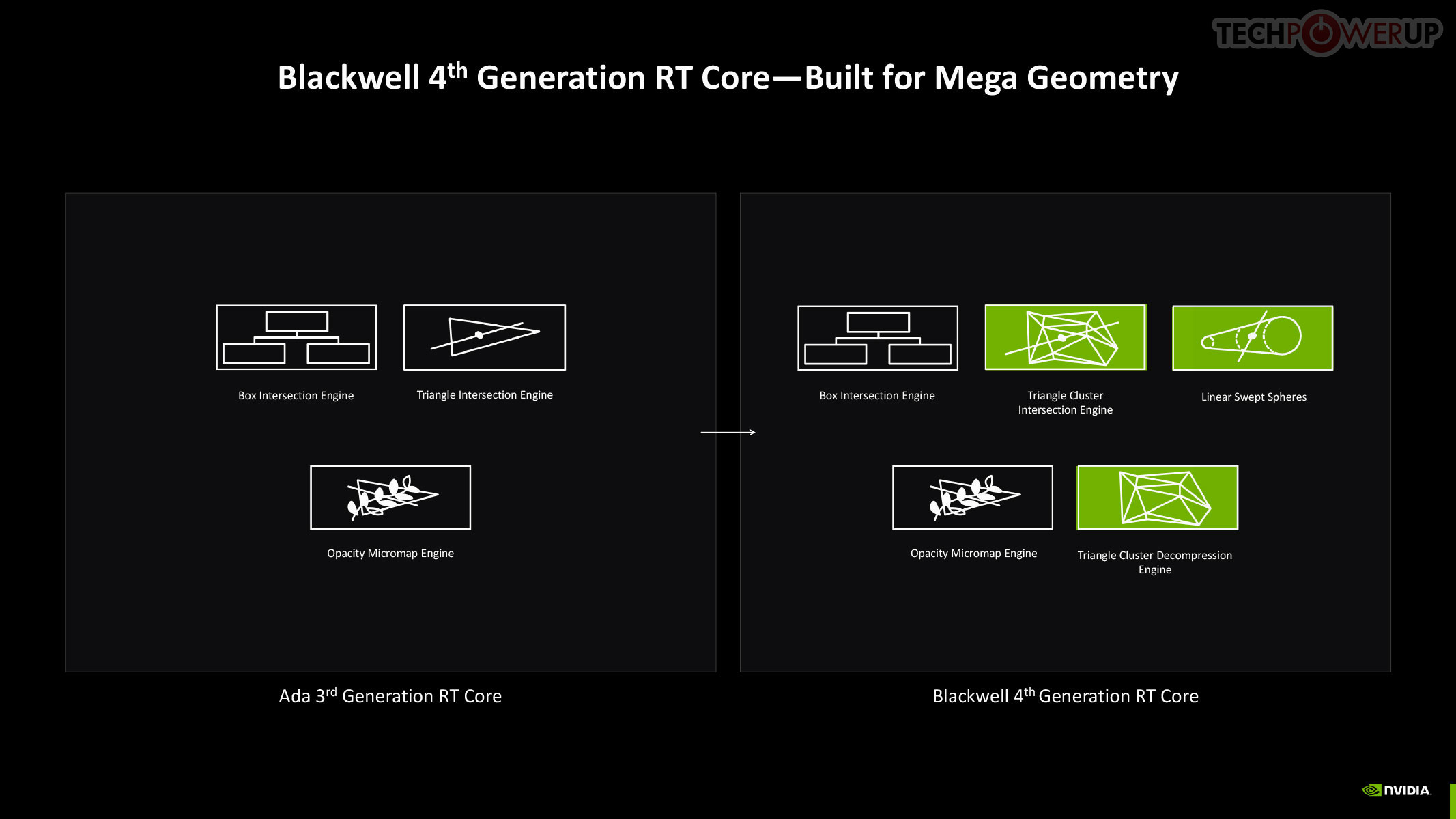
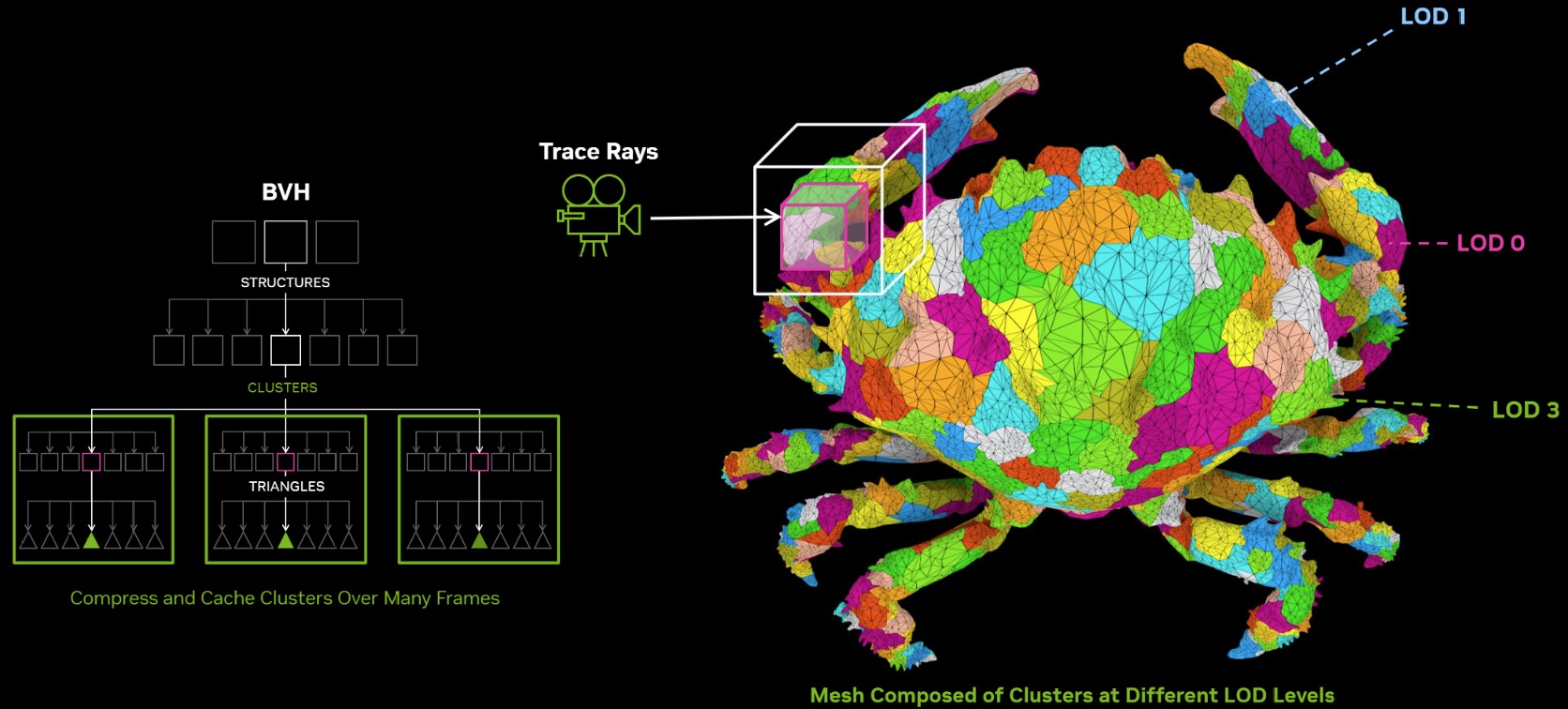
The 4th Gen RT core not just offers a generational increase in ray testing and ray intersection performance, which lowers the performance cost of enabling path tracing and ray traced effects; but also offers a potential generational leap in performance with the introduction of Mega Geometry. This allows for ray traced objects with extremely high polygon counts, increasing their detail. Poly count and ray tracing present linear increases in performance costs, as each triangle has to intersect with a ray, and there should be sufficient rays to intersect with each of them. This is achieved by adopting clusters of triangles in an object as first-class primitives, and cluster-level acceleration structures. The new RT cores introduce a component called a triangle cluster intersection engine, designed specifically for handling mega geometry. The integration of a triangle cluster compression format and a lossless decompression engine allows for more efficient processing of complex geometry.


The GB202 and the rest of the GeForce Blackwell GPU family is built on the exact same TSMC "NVIDIA 4N" foundry node, which is actually 5 nm, as previous-generation Ada, so NVIDIA directed efforts to finding innovative new ways to manage power and thermals. This is done through a re-architected power management engine that relies on clock gating, power gating, and rail gating of the individual GPCs and other top-level components. It also worked on the speed at which the GPU makes power-related decisions.
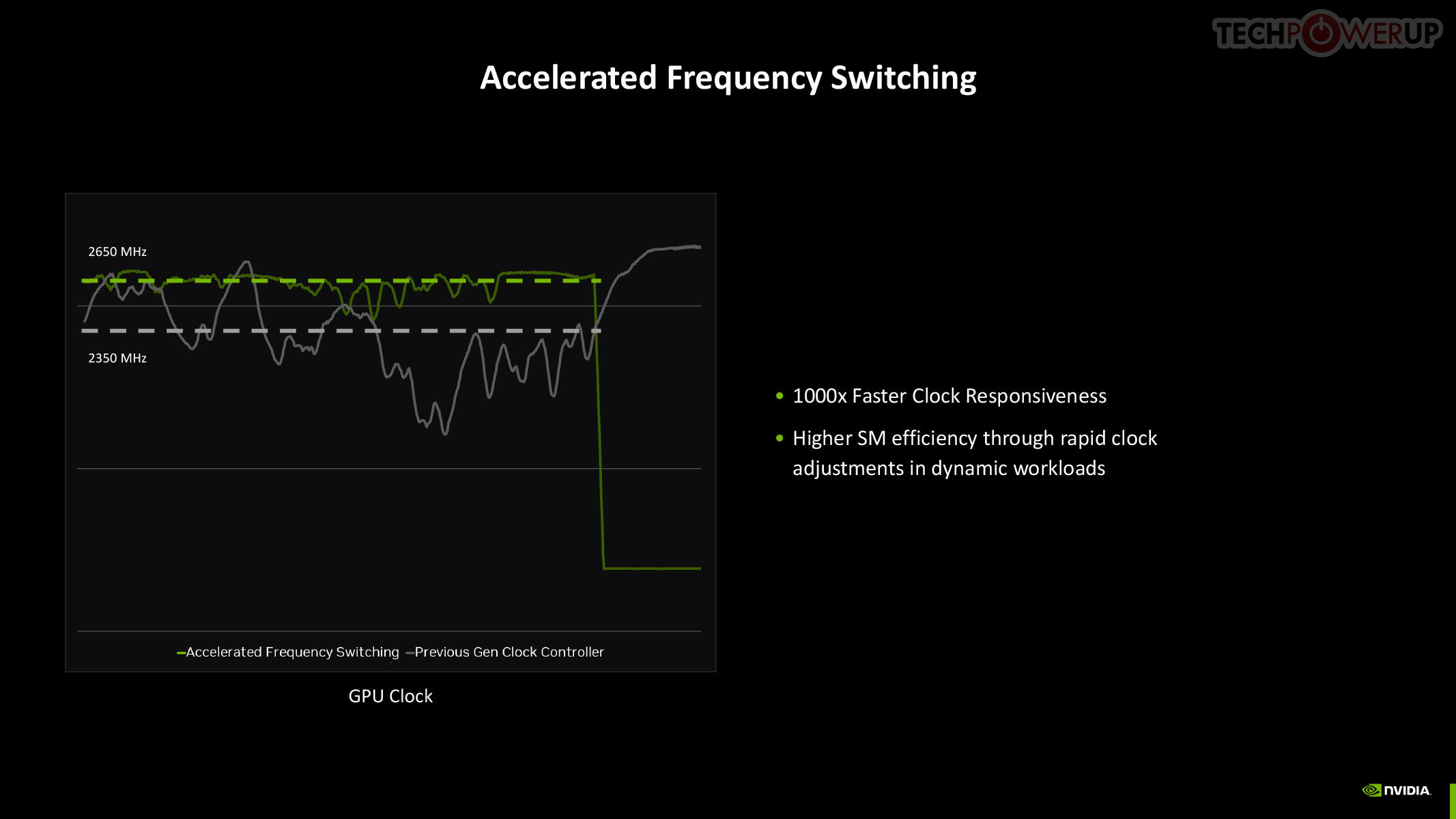
The quickest way to drop power is by adjusting the GPU clock speed, and with Blackwell, NVIDIA introduced a means for rapid clock adjustments at the SM-level.
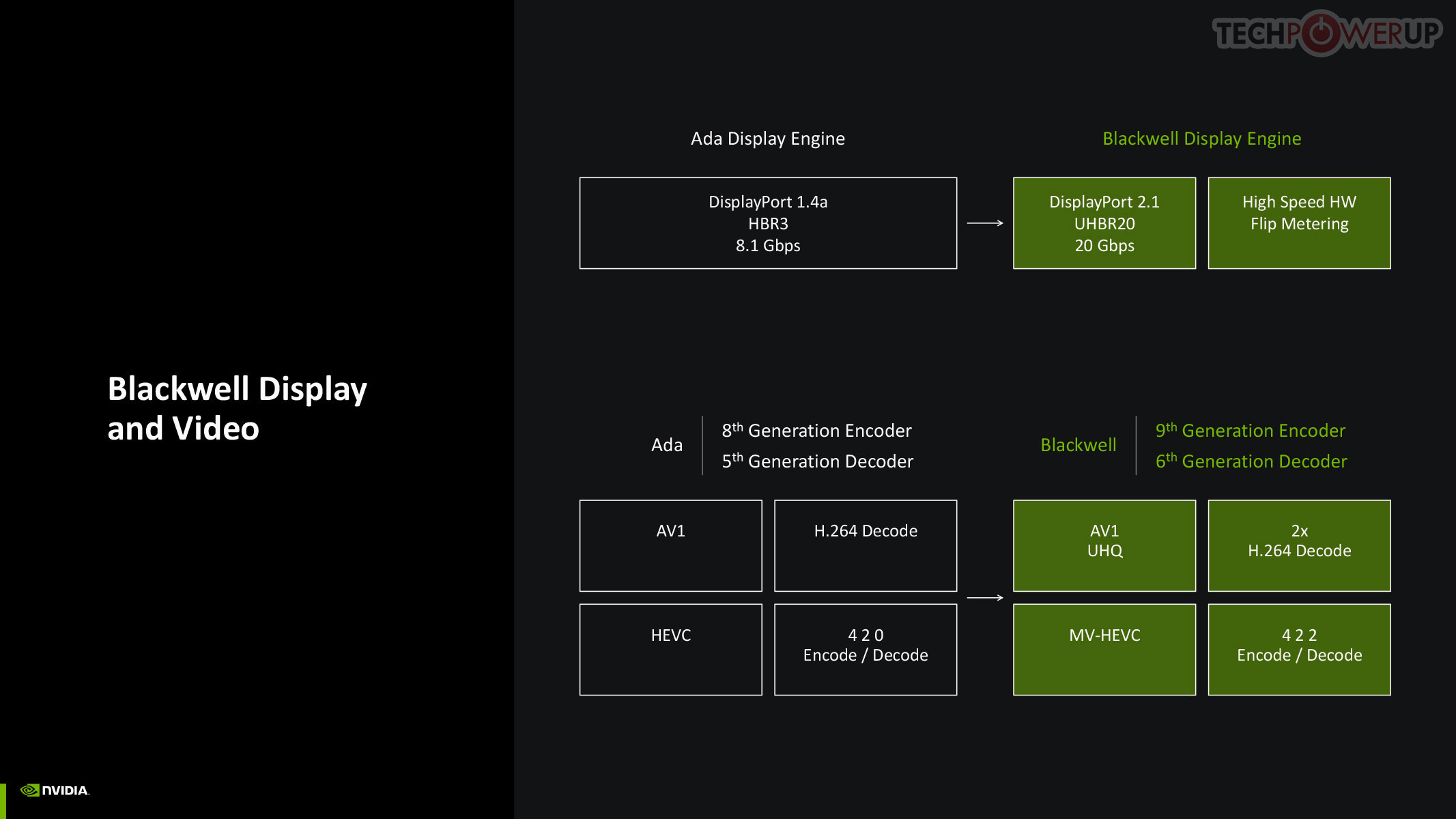
NVIDIA updated both the display engine and the media engine of Blackwell over the previous generation Ada, which drew some flack for holding on to older display I/O standards such as DisplayPort 1.4, while AMD and Intel had moved on to DisplayPort 2.1. The good news is that Blackwell supports DP 2.1 with UHBR20, enabling 8K 60 Hz with a single cable. The company also updated NVDEC and NVENC, which now support AV1 UHQ, double the H.264 decode performance, MV-HEVC, and 4:2:2 formats.
Neural Rendering
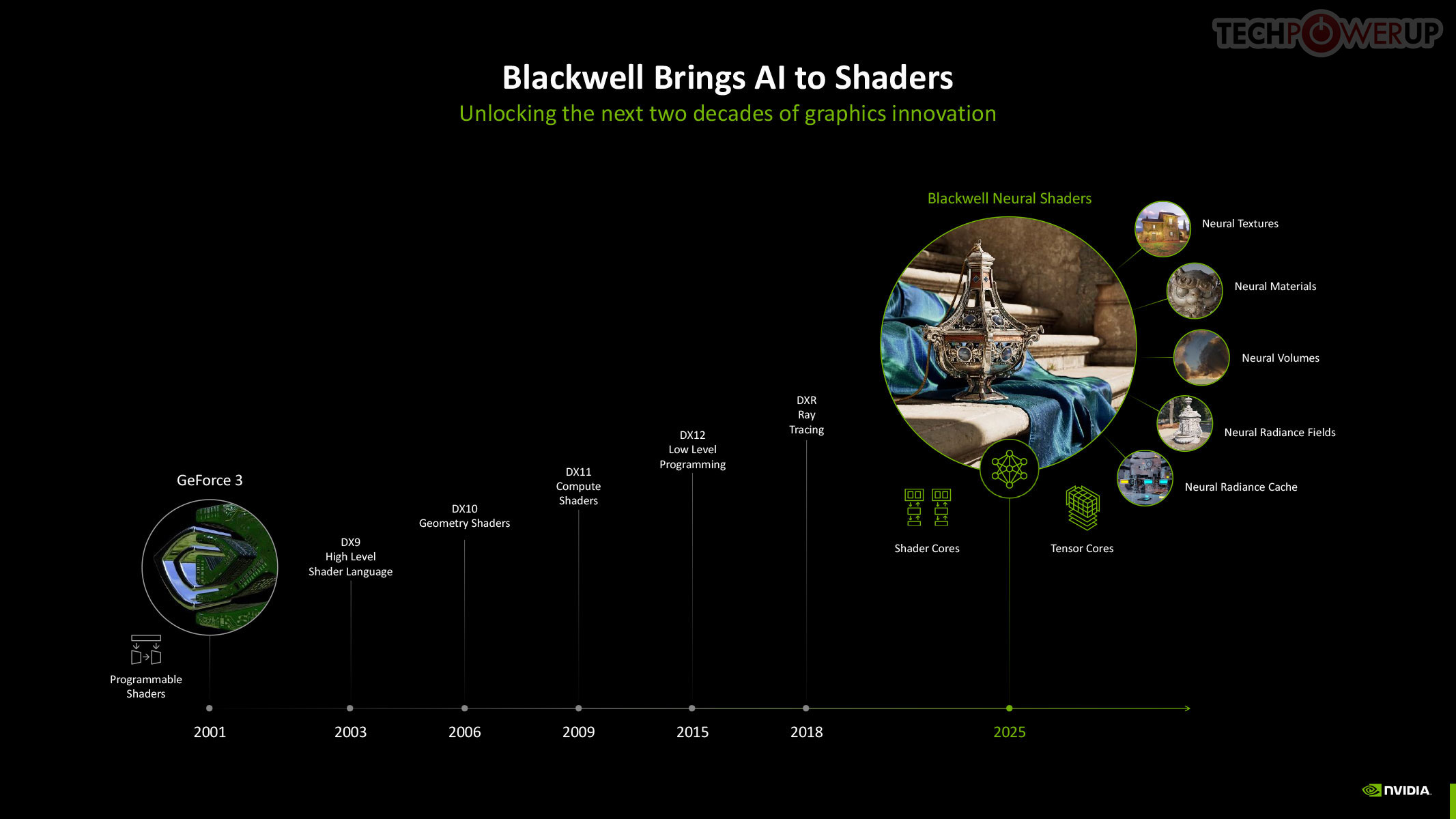
Neural Rendering promises to be as transformative to modern graphics as programmable shaders itself. 3D Graphics rendering evolved from fixed-function over the turn of the century, to programmable shaders, HLSL, geometry shaders, compute shaders, and ray tracing, over the past couple of decades. In 2025, NVIDIA is writing the next chapter in this journey with Blackwell neural shaders. This allows for a host of neural-driven effects, including neural materials, neural volumes, and even neural radiance fields. Microsoft introduced the new Cooperative Vectors API for DirectX in a recent update, making it possible to access Tensor cores within a graphics API. Combined with a new shading language, Slang, this breakthrough enables developers to integrate neural techniques directly into their workflows, potentially replacing parts of the traditional graphics pipeline. Slang splits large, complex functions into smaller pieces that are easier to handle. Given that this is a DirectX standard API feature, there is nothing that stops AMD and Intel from integrating Neural Rendering (Cooperative Vectors) into their graphics drivers.
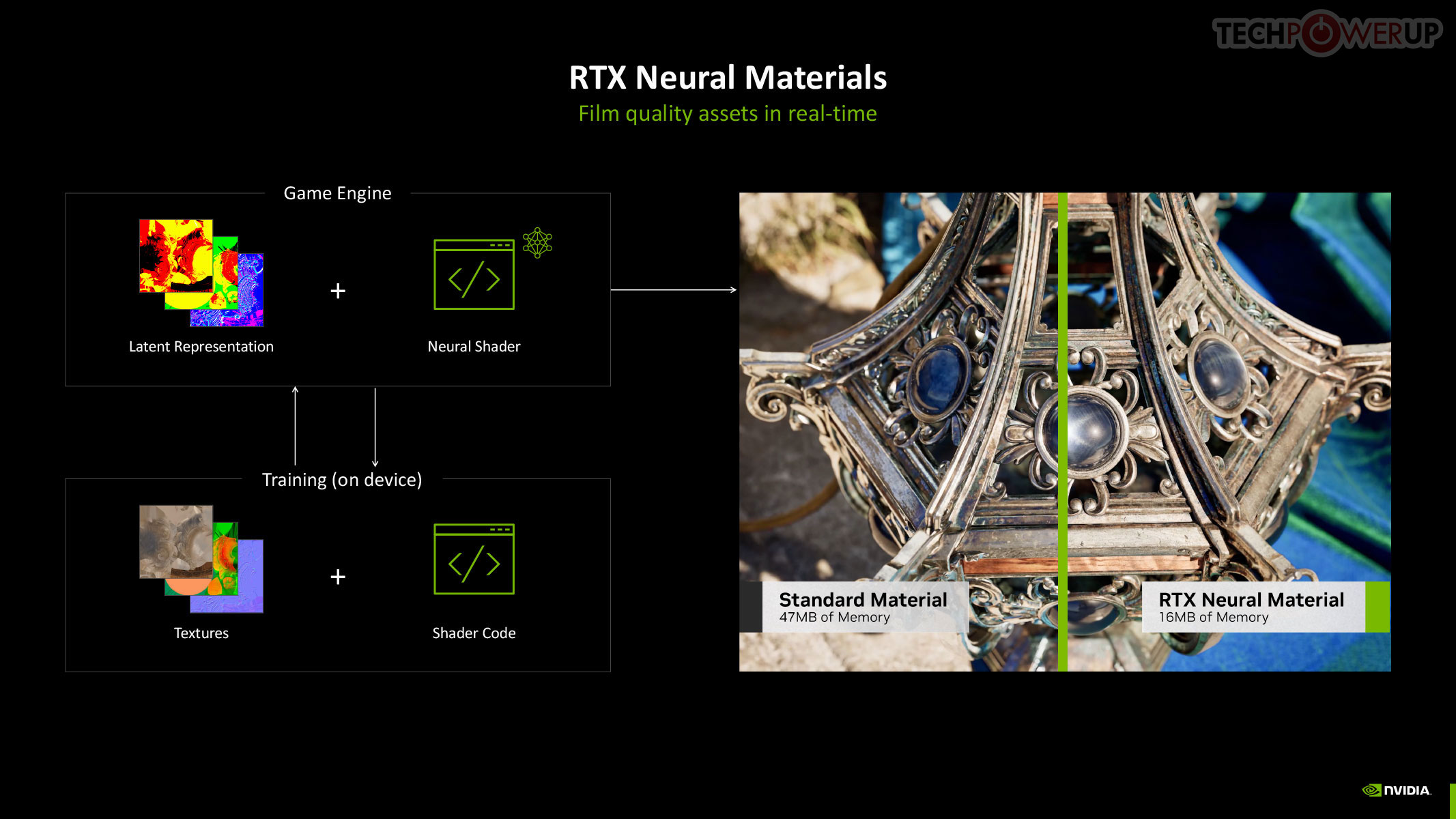
RTX Neural Materials works to significantly reduce the memory footprint of materials in 3D scenes. Under conventional rendering, the memory footprint of a material is bloated from complex shader code. Neural materials convert shader code and texture layers into a compressed neural representation. This results in up to a 7:1 compression ratio and enables small neural networks to generate stunning, film-like materials in real-time. For example, silk rendered with traditional shaders might lack the multicolored sheen seen in real life. Neural materials, however, capture intricate details like color variation and reflections, bringing such surfaces to life with unparalleled realism—and at a fraction of the memory cost.

The new Neural Radiance Cache, which dynamically trains a neural network during gameplay using the user's GPU, allowing light transport to be cached spatially, enabling near-infinite light bounces in a scene. This results in realistic indirect lighting and shadows with minimal performance impact. NRC partially traces 1 or 2 rays before storing them in a radiance cache, and infers an infinite amount of rays and bounces for a more accurate representation of indirect lighting in the game scene.
DLSS 4 and Multi Frame Generation


DLSS 4 introduces a major leap in image quality and performance. It isn't just a version bump with the introduction of a new feature, namely Multi Frame Generation, but introduces updates to nearly all DLSS sub-features. DLSS from its very beginning relied on AI to reconstruct details in super resolution, and with DLSS 4, NVIDIA is introducing a new transformer-based AI model to succeed the convolutional neural networks previous used, for double the parameters, four times the compute performance, and significantly improved image quality. Ray Reconstruction, introduced with DLSS 3.5, gets a significant image quality update with the new transformer-based model.
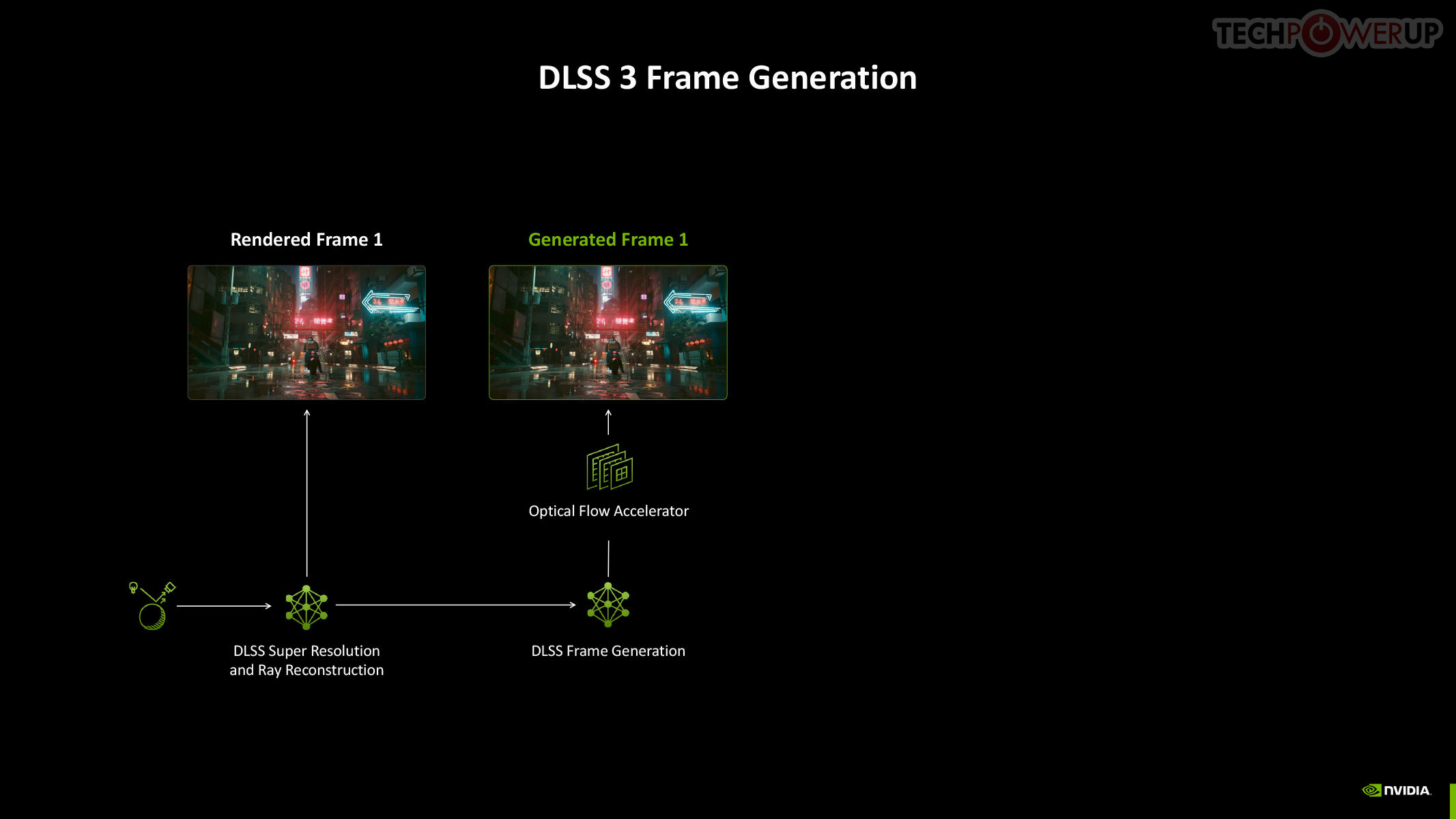
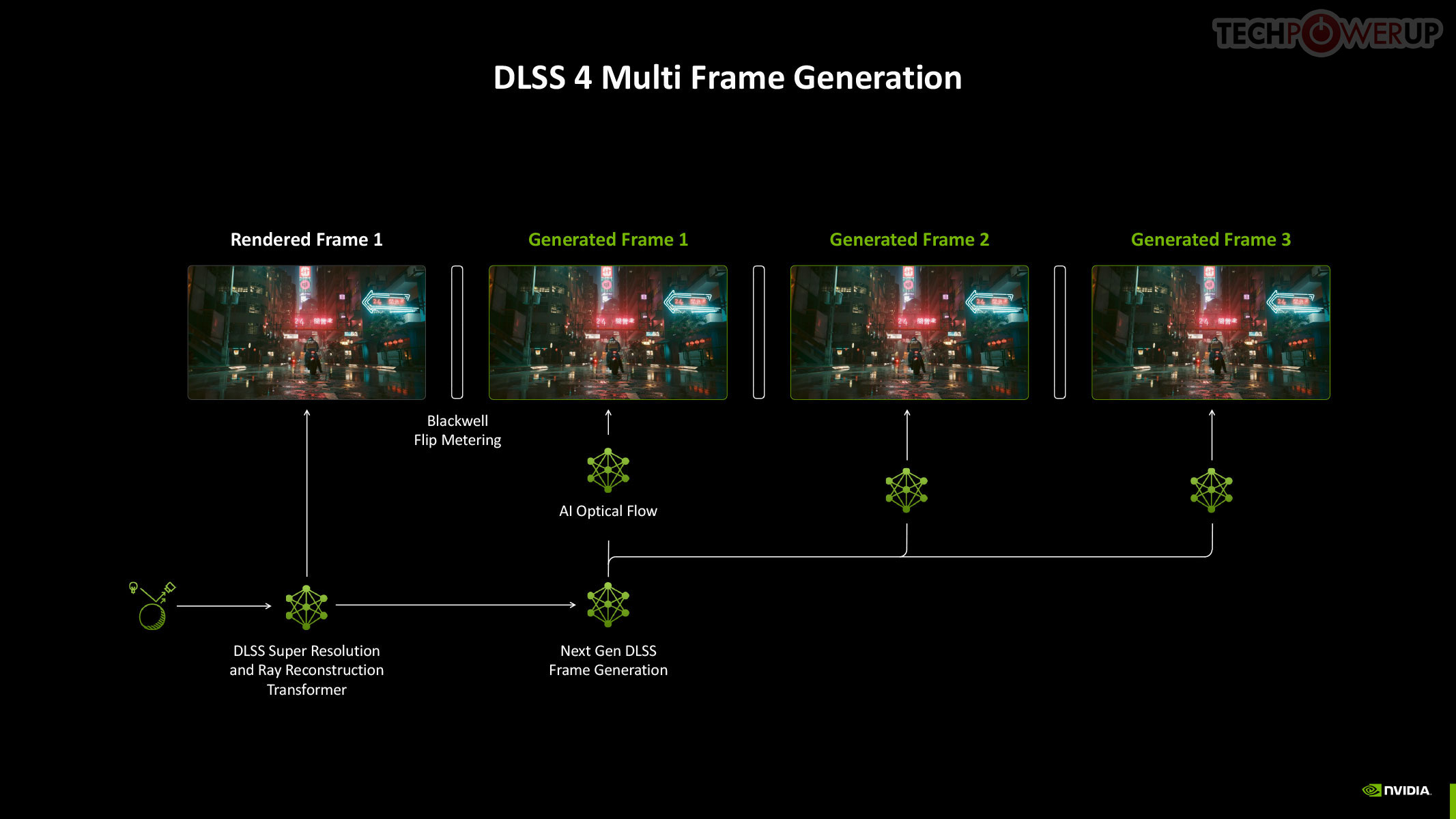
To understand Multi Frame Generation, you need to understand how DLSS Frame Generation, introduced with GeForce Ada, works. An Optical Flow Accelerator component gives the DLSS algorithm data to generate an entire frame using a neural network, using information from a previous rendered frame, effectively doubling frame rate. In Multi Frame Generation, AI takes over the functions of optical flow, to predict up to three frames following a conventionally rendered frame, effectively drawing four frames form the rendering effort of one.

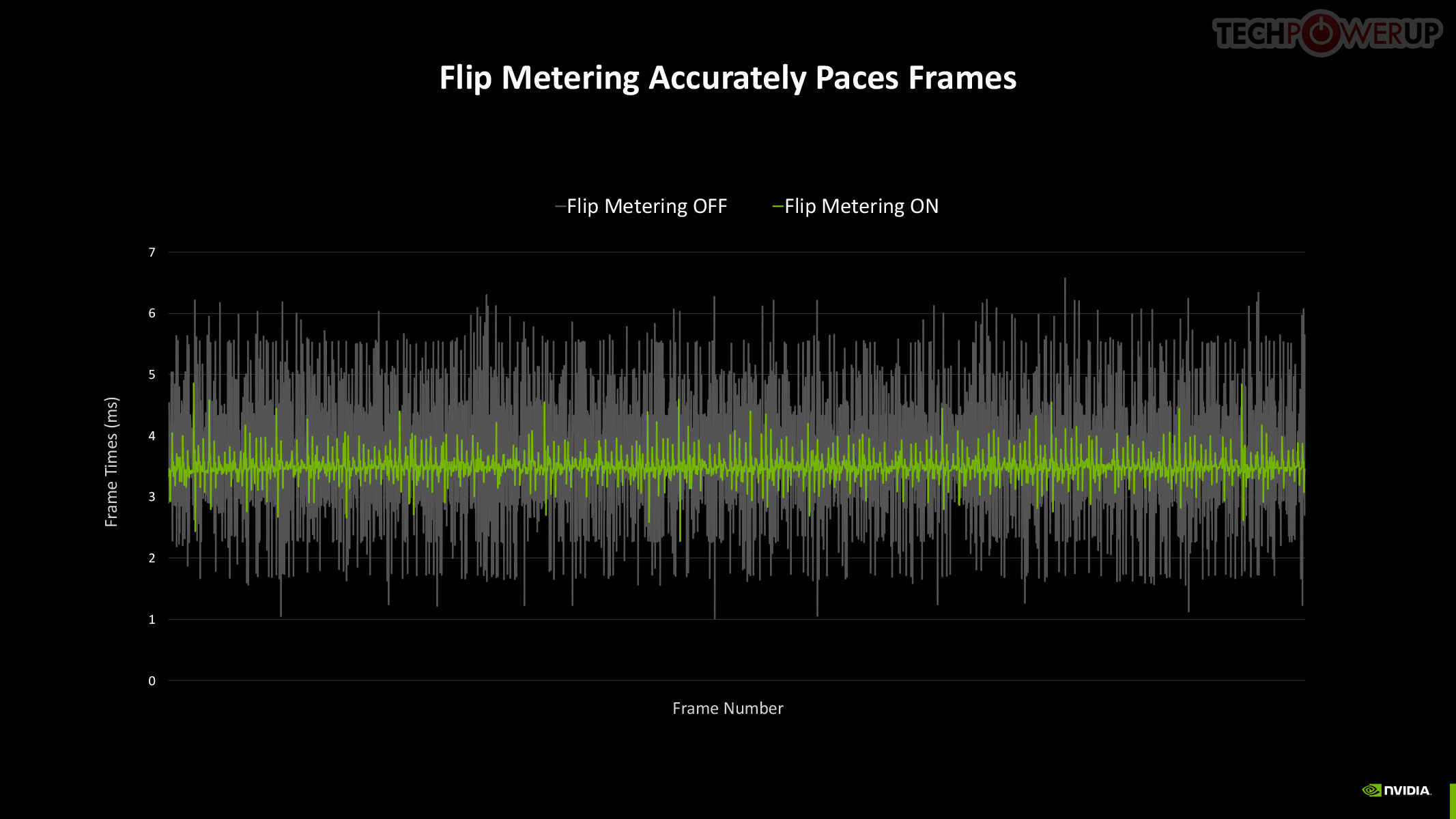
Now, assuming this rendered frame is a product of Super Resolution, with the maximum performance setting generating 4x the pixels from a single rendered pixel, you're looking at a possibility where the rendering effort of 1/4th a frame goes into drawing 4 frames, or 15 in every 16 pixels being generated entirely by DLSS. When generating so many frames, Frame Pacing becomes a problem—irregular frame intervals impact smoothness. DLSS 4 addresses these issues by using a dedicated hardware unit inside Blackwell, which takes care of flip metering, reducing frame display variability by 5-10x. The Display Engine of Blackwell contains the hardware for flip metering.
NVIDIA Reflex 2
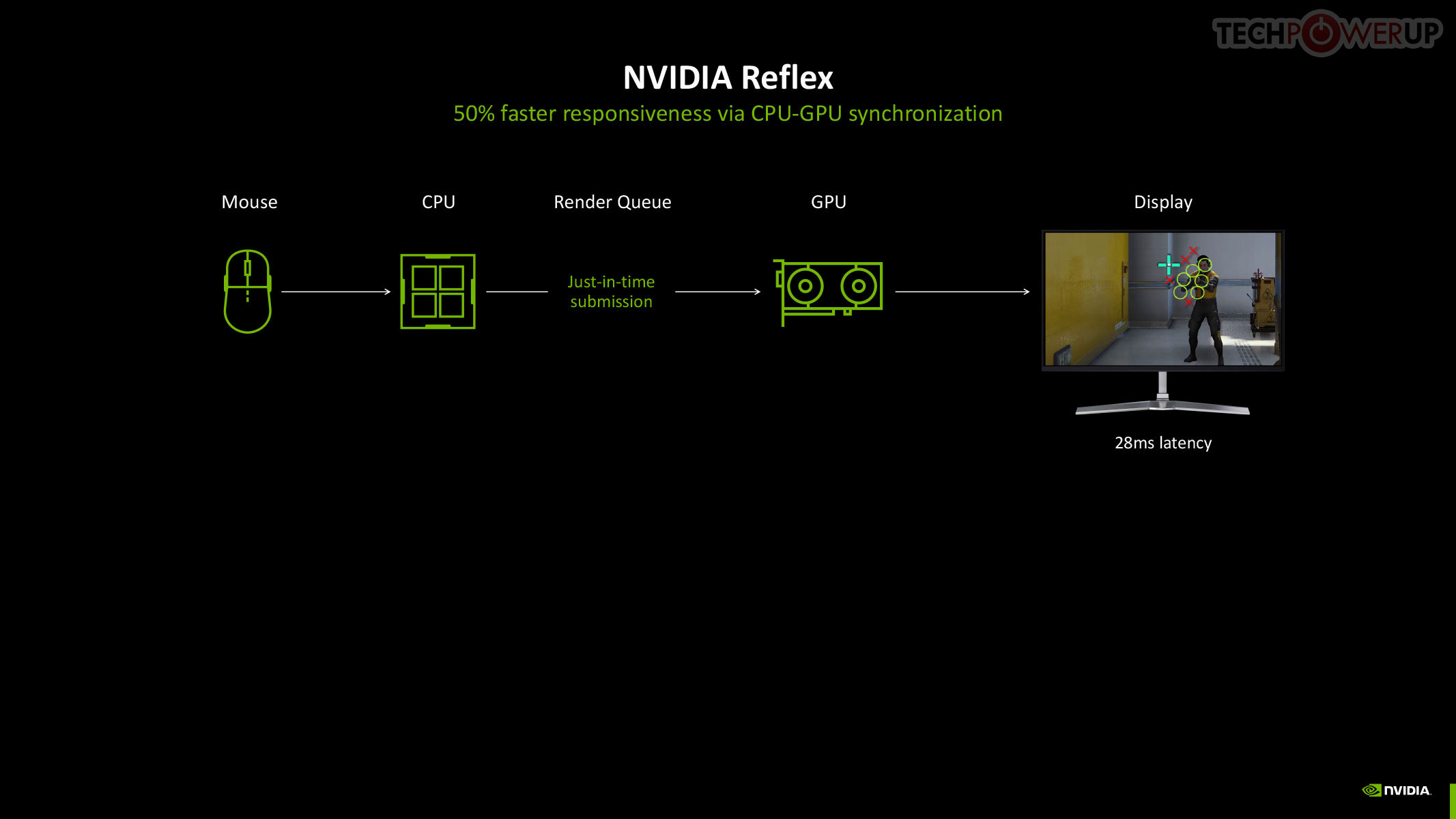
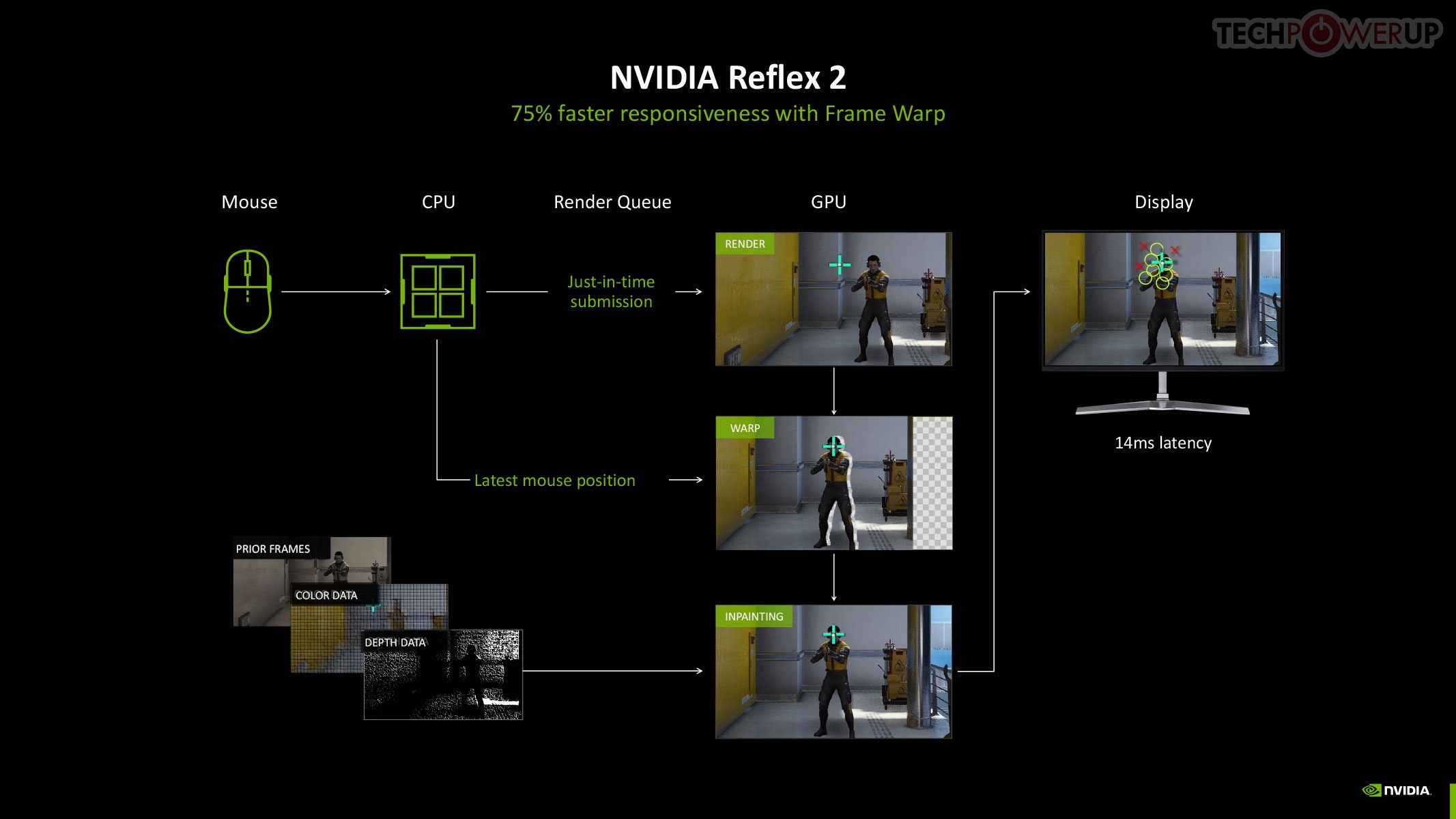
The original NVIDIA Reflex brought about a significant improvement to the responsiveness of maxed out graphics in competitive online gameplay, by compacting the rendering queue with the goal of reducing the whole system latency by up to 50%. Reflex is mandatory in DLSS 3 Frame Generation, given the latency cost imposed by the technology. Multi-frame generation calls for an equally savvy piece of technology, so we hence have Reflex 2. NVIDIA claims to have achieved a 75% reduction in latency with Frame Warp, which updates the camera (viewport) positions based on user inputs in real-time, and then uses temporal information to reconstruct the frame to display.
Packaging



The Card



NVIDIA's RTX 5090 comes with a refreshed Founders Edition design theme. It's instantly recognizable that this is a FE card, but there have been small aesthetics tweaks, like more smooth corners etc. Also note that both sides of the back now have cutouts for air to flow though.


Dimensions of the card are 30.0 x 14.0 cm, and it weighs 1814 g.



Here's the RTX 5090 compared to the RTX 4090. Same footprint, but just two slots.


Installation requires two slots in your system. We measured the card's width to be 40 mm.

Display connectivity includes three standard DisplayPort 2.1b and one HDMI 2.1b.
Standard for all GeForce RTX 50-series Blackwell cards is a new display engine that supports three DisplayPort 2.1b outputs, each capable of UHBR20; and one HDMI 2.1a. Both interfaces support DSC (display stream compression). With DSC enabled, a single DisplayPort on this card can drive 4K 12-bit HDR at 480 Hz; or 8K 12-bit HDR at up to 165 Hz. The RTX 5090 features an updated media acceleration engine with support for 4:2:2 video formats, AV1 UHQ, and MV-HEVC. There are three independent NVENC units, and two NVDEC.




Inside the Founders Edition box you'll find an 8-pin to 16-pin adapter. This is a new model that feels MUCH better, thanks to softer cables and a better plug that's more massive, so it can withstand more abuse.

Here's a side-by-side comparison between the old and new adapter.




The card uses a single 16-pin connector, which allows a maximum power draw of 600 W. NVIDIA has improved the location of the adapter, and it's recessed now and comes out at an angle.


NVIDIA's Founders Edition features white lighting on the GeForce RTX logo and around the air inlets on both sides. The lighting effect is static, it can't be adjusted in color or brightness. There's also no way to turn it off.
Our Patreon Silver Supporters can read articles in single-page format.
May 6th, 2025 17:09 EDT
change timezone
Latest GPU Drivers
New Forum Posts
- vccsa and vccio have another name AsRock ? (5)
- RX 9000 series GPU Owners Club (678)
- The TPU UK Clubhouse (26218)
- Why doesn't every house have solar installed? (343)
- laptop cooler- more smaller fans or less larger fans? (4)
- need help choosing a CPU (3)
- What is the latest game you finished or 100% (22)
- Not thermal throttling, not power throttling, and yet still... throttling - lenovo laptop, i5 9300H (1)
- Game Soundtracks You Love (1062)
- How high of a ram frequency can i run on a Z690 with an 14700Kf processor? (7)
Popular Reviews
- Arctic Liquid Freezer III Pro 360 A-RGB Review
- ASUS Radeon RX 9070 XT TUF OC Review
- Clair Obscur: Expedition 33 Performance Benchmark Review - 33 GPUs Tested
- ASUS ROG Maximus Z890 Hero Review
- Zotac GeForce RTX 5070 Ti Amp Extreme Review
- Upcoming Hardware Launches 2025 (Updated Apr 2025)
- Seasonic Vertex GX 850 W Review
- Sapphire Radeon RX 9070 XT Nitro+ Review - Beating NVIDIA
- ASUS GeForce RTX 5090 Astral Liquid OC Review - The Most Expensive GPU I've Ever Tested
- AMD Ryzen 7 9800X3D Review - The Best Gaming Processor
Controversial News Posts
- AMD Radeon RX 9060 XT to Roll Out 8 GB GDDR6 Edition, Despite Rumors (142)
- NVIDIA Sends MSRP Numbers to Partners: GeForce RTX 5060 Ti 8 GB at $379, RTX 5060 Ti 16 GB at $429 (128)
- NVIDIA Launches GeForce RTX 5060 Series, Beginning with RTX 5060 Ti This Week (115)
- Nintendo Confirms That Switch 2 Joy-Cons Will Not Utilize Hall Effect Stick Technology (105)
- Sony Increases the PS5 Pricing in EMEA and ANZ by Around 25 Percent (84)
- Parts of NVIDIA GeForce RTX 50 Series GPU PCB Reach Over 100°C: Report (78)
- Intel "Bartlett Lake-S" Gaming CPU is Possible, More Hints Appear for a 12 P-Core SKU (77)
- China Develops HDMI Alternative: 192 Gbps Speeds and 480 W Power Delivery (74)