Thursday, March 9th 2023
South Korean Company Morumi is Developing a CPU with Infinite Parallel Processing Scaling
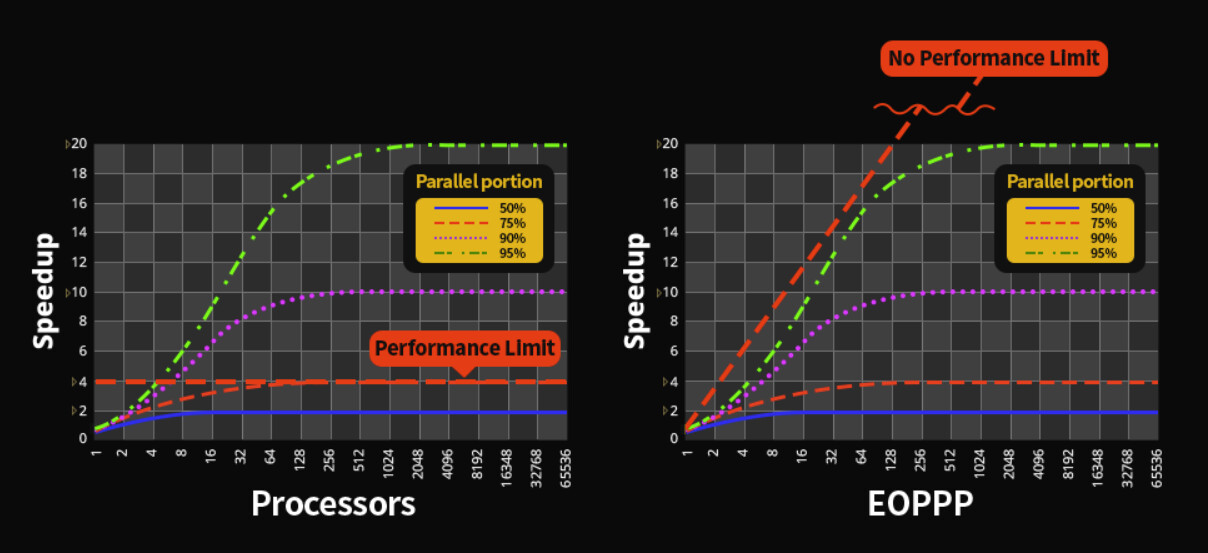
One of the biggest drawbacks of modern CPUs is that adding more cores doesn't equal more performance in a linear fashion. Parallelism in CPUs offer limited scaling for most applications and even none for some. A South Korean company called Morumi is now taking a stab at solving this problem and wants to develop a CPU that can offer more or less infinite processing scaling, as more cores are added. The company has been around since 2018 and focused on various telecommunications chips, but has now started the development on what it calls every one period parallel processor (EOPPP) technology.
EOPPP is said to distribute data to each of the cores in a CPU before the data is being processed, which is said to be done over a type of mesh network inside the CPU. This is said to allow for an almost unlimited amount of instructions to be handled at once, if the CPU has enough cores. Morumi already has an early 32-core prototype running on an FPGA and in certain tasks the company has seen a tenfold performance increase. It should be noted that this requires software specifically compiled for EOPPP and Moumi is set to release version 1.0 of its compiler later this year. It's still early days, but it'll be interesting to see how this technology develops, but if it's successfully developed, there's also a high chance of Morumi being acquired by someone much bigger that wants to integrate the technology into their own products.
Sources:
The Elec, Morumi
EOPPP is said to distribute data to each of the cores in a CPU before the data is being processed, which is said to be done over a type of mesh network inside the CPU. This is said to allow for an almost unlimited amount of instructions to be handled at once, if the CPU has enough cores. Morumi already has an early 32-core prototype running on an FPGA and in certain tasks the company has seen a tenfold performance increase. It should be noted that this requires software specifically compiled for EOPPP and Moumi is set to release version 1.0 of its compiler later this year. It's still early days, but it'll be interesting to see how this technology develops, but if it's successfully developed, there's also a high chance of Morumi being acquired by someone much bigger that wants to integrate the technology into their own products.
29 Comments on South Korean Company Morumi is Developing a CPU with Infinite Parallel Processing Scaling
en.wikipedia.org/wiki/Amdahl%27s_law
I'll believe it when I see it, but I strongly suspect the capabilities of this EOPPP thing are either grossly exaggerated, or an outright scam entirely.
Sighhh
I quote " is said to distribute data to each of the cores in a CPU before the data is being processed, which is said to be done over a type of mesh network inside the CPU. This is said to allow for an almost unlimited amount of instructions to be handled at once, "
Hmnnn now is anyone else thinking wtaf is it me.
I thought that's how CPU work, distribute data, work on data , does an EORPPP use magical stuff wherein Intel use silicon.
What gives.
And have I mentioned that I am inventing a raycasting chip that can do infinite rays, it takes work in first then does work and through this simple change I WILL BEAT Nvidia, wait what.
From the source link. Maybe I misunderstood something.
Worked on and,
Put back together at the end.
We have two versions of this in modern pcs already, this is exactly what a GPU does, unified processing across core's and has memory constraints since SRAM has stopped scaling and in general eats space, obviously a CPU does this on a limited small scale?!?.
But EORPPP needs to be specifically written for or compiled for and by the sound of it conceptually written For, ohh kk I mean Academia and enterprise might have a use but I think it limited, especially since we have massively parallel symptoms we already struggle to make work on general tasks and not enough tasks to warrant the financial input.
Well see , but Cerberus would also be saying yo What now.
Ps massively parallel systems :p made me laugh, it's staying, now where are those glasses. :):D
It's the "no performance limit" claim that is BS if there previously was one, as that would require sequential part to be nonexistent, i.e., program code being redesigned, and not just ran on another CPU.
Let's say you have a piece of code.
1) You run it on CPU A, say, 128 core Xeon, but 127 of those disabled. You get some performance numbers.
2) Now you enable all cores, run it again. You get 10x speedup.
3) Now have same code ran on different CPU B with only 1 core, 127 disabled. You get some other performance number.
4) Rerun that code on CPU B with 128 cores too. What would speedup vs scenario 3) be? x10 too
What would difference between CPU A and CPU B when ran single-to-single or multi-to-multi? That has nothing to do with Amdahl's law, but with how A and B architectures are optimized for this kind of task.
So what Amdahl's law states is that speedup between scenarios 1 vs 2 and 3 vs 4 is the same, because you keep same architecture, but add more cores. This is actual scope of Amdahl's law.
Scenarios 1 vs 3 and 2 vs 4 are not the scope of Amdahl's law.
Changing an architecture is a different scenario. It can make CPU B 10/100/1000x faster than CPU A core-to-core, but it cannot change that speedup from adding more cores will plateau proportionally as well. That max speedup is inherent property of specific code and not something to work around in CPU architecture.
Only way to make it scale without limit is to rewrite the code so that there is no sequential part and all threads are ran independent from each other.
Then you get infinite scaling with more cores on CPU A, but also CPU B, and any other CPU that can run this code.
IOW, there is nothing magical about described CPU that would make same code have infinite scaling, if it didn't have it already.
10x speedup from more cores is not it, as it's predicted by that law to be entirely possible.
Making same code scale infinitely with more cores, when it didn't on other processors? That's not an observation. That's a claim. Not a validated one by anything provided. Until it actually gets validated, Amdahl's law stands. And I have temerity to strongly doubt it would get validated, ever. Somewhere in the range of doubting perpetuum mobile existing.
For the record "10x speedup" is a claim too for all we know now, but an easily believable one, since:
1)It does not violate said law
2)Processor designing companies have been optimizing architectures for specific tasks for decades
I guess you won't be complaining about clickbait in headlines for the sake of being consistent then.
Company's claims are.
Creating a highly performing/efficient architecture for specific tasks? I hope they do lol.
Overturning Amdahl's law by making programs suddenly perfectly scale with more cores when it didn't on other processors? I have a bridge to sell you, if you honestly believe that.
Same as, say, evolution. Oh, it's "just" a theory, right? Yet we have so much evidence for it, that we basically accept it at this point. Unless one's tinfoil hat is slipping that is ;)
What you described just sounds like an enhanced hyperthreading?
Parallel Processing Apparatus Capable of Consecutive Parallelism
??