AMD Announces Spartan UltraScale+ Family of FPGAs
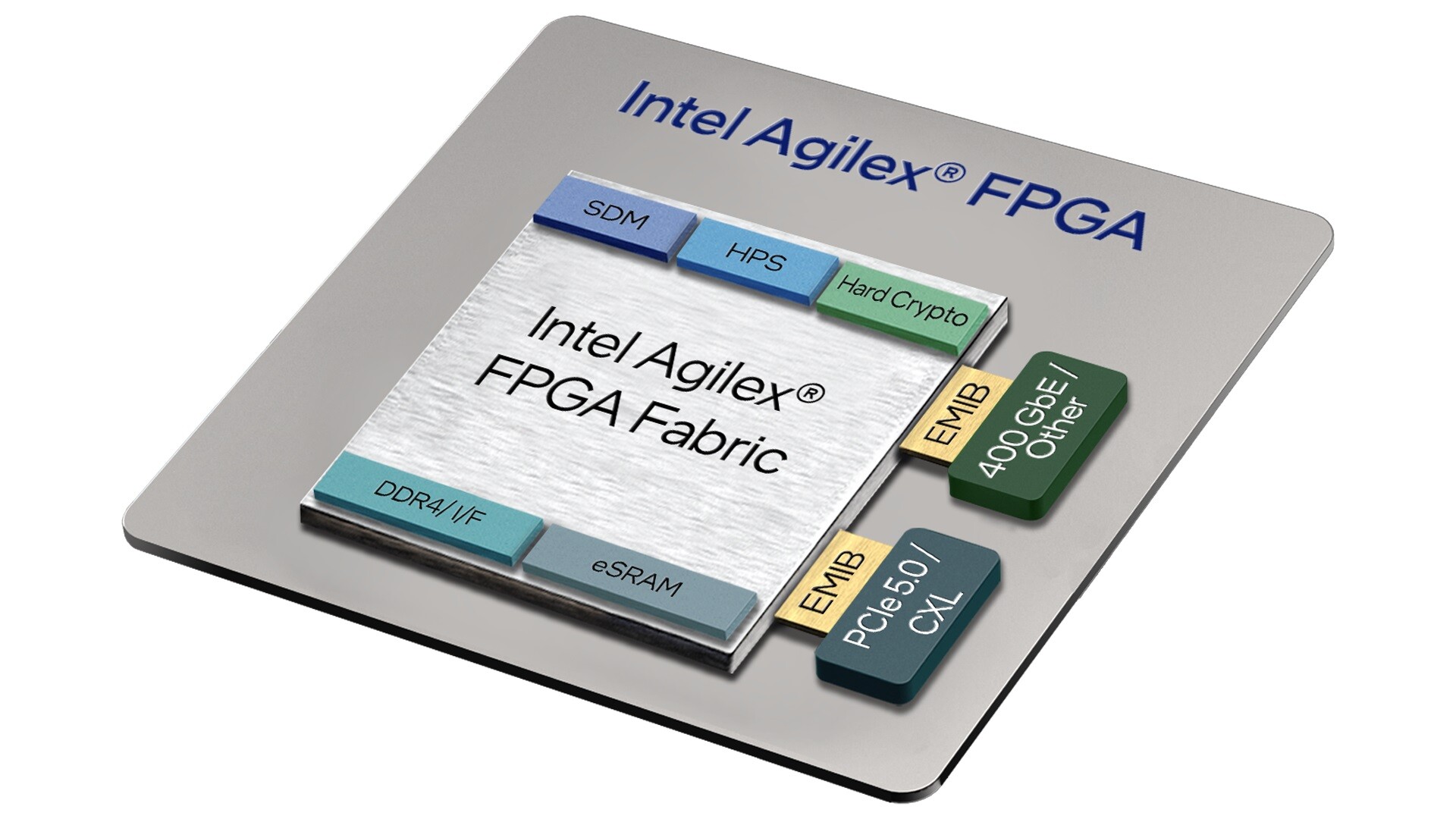
AMD today announced the AMD Spartan UltraScale+ FPGA family, the newest addition to the extensive portfolio of AMD Cost-Optimized FPGAs and adaptive SoCs. Delivering cost and power-efficient performance for a wide range of I/O-intensive applications at the edge, Spartan UltraScale+ devices offer the industry's highest I/O to logic cell ratio in FPGAs built in 28 nm and lower process technology, deliver up to 30 percent lower total power consumption versus the previous generation, and contain the most robust set of security features in the AMD Cost-Optimized Portfolio.
"For over 25 years the Spartan FPGA family has helped power some of humanity's finest achievements, from lifesaving automated defibrillators to the CERN particle accelerator advancing the boundaries of human knowledge," said Kirk Saban, corporate vice president, Adaptive and Embedded Computing Group, AMD. "Building on proven 16 nm technology, the Spartan UltraScale+ family's enhanced security and features, common design tools, and long product lifecycles further strengthen our market-leading FPGA portfolio and underscore our commitment to delivering cost-optimized products for customers."
"For over 25 years the Spartan FPGA family has helped power some of humanity's finest achievements, from lifesaving automated defibrillators to the CERN particle accelerator advancing the boundaries of human knowledge," said Kirk Saban, corporate vice president, Adaptive and Embedded Computing Group, AMD. "Building on proven 16 nm technology, the Spartan UltraScale+ family's enhanced security and features, common design tools, and long product lifecycles further strengthen our market-leading FPGA portfolio and underscore our commitment to delivering cost-optimized products for customers."