AMD Readies MI250X Compute Accelerator with 110 CUs and 128 GB HBM2E
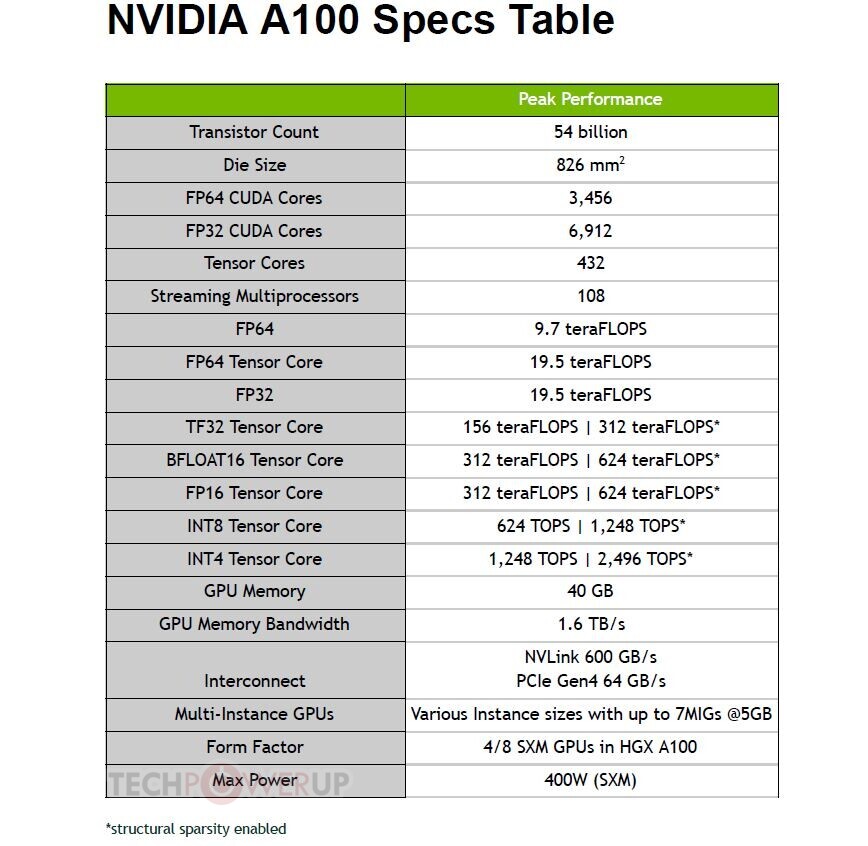
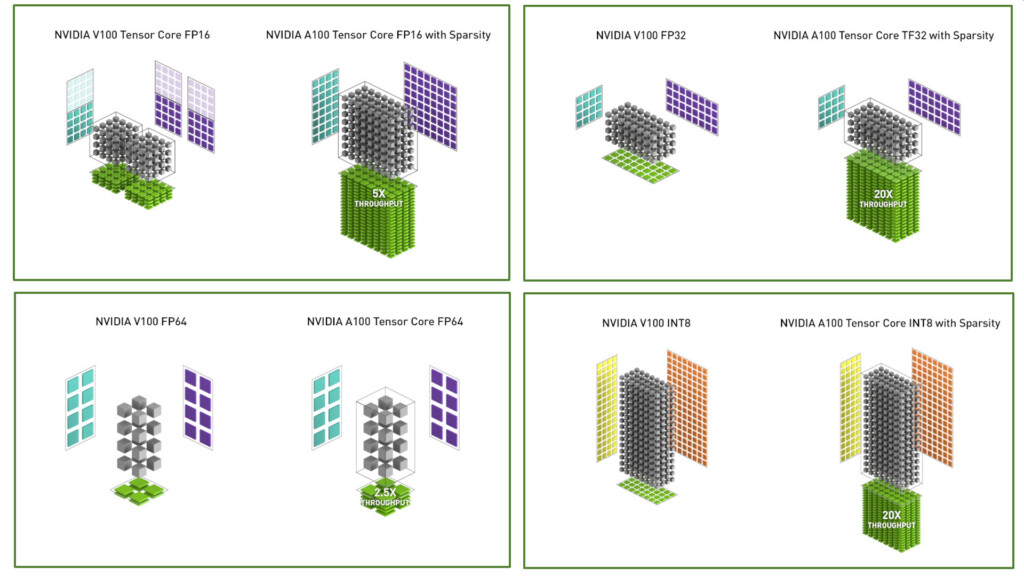
AMD is preparing an update to its compute accelerator lineup with the new MI250X. Based on the CDNA2 architecture, and built on existing 7 nm node, the MI250X will be accompanied by a more affordable variant, the MI250. According to leaks put out by ExecutableFix, the MI250X packs a whopping 110 compute units (7,040 stream processors), running at 1.70 GHz. The package features 128 GB of HBM2E memory, and a package TDP of 500 W. As for speculative performance numbers, it is expected to offer double-precision (FP64) throughput of 47.9 TFLOP/s, ditto full-precision (FP32), and 383 TFLOP/s half-precision (FP16 and BFLOAT16). AMD's MI200 "Aldebaran" family of compute accelerators are expected to square off against Intel's "Ponte Vecchio" Xe-HPC, and NVIDIA Hopper H100 accelerators in 2022.