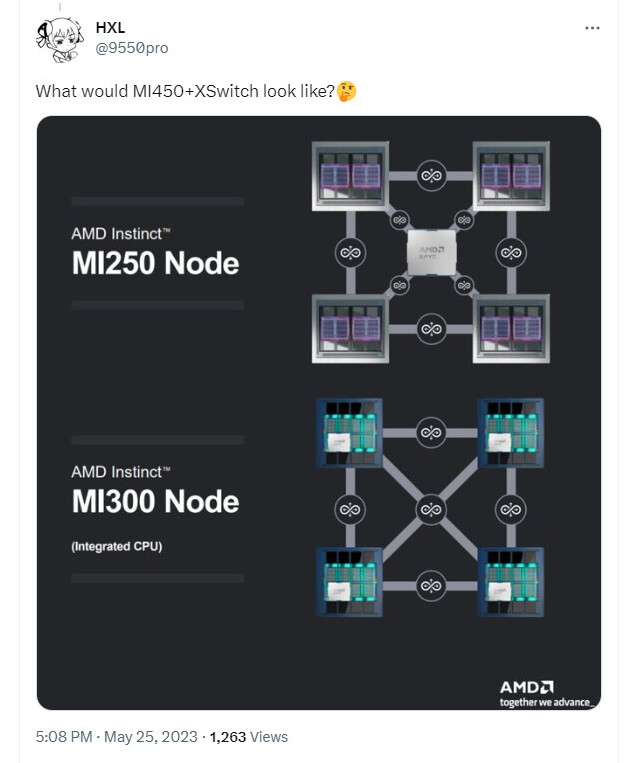
Based on a report by Tom's Hardware, AMD's CEO Lisa Su is planning a trip to Taiwan in the next couple of months. It is said that she is planning to meet with multiple partners in Taiwan, such as ASUS, Acer and maybe more importantly, ASMedia, which will be the sole maker of chipsets for AMD, once the X570 chipset is discontinued. AMD is apparently also seeing various less well known partners that deliver parts for its CPUs, such as Nan Ya PCB, Unimicron Technologies and Kinsus Interconnects.
However, it appears that the main reason for Lisa Su herself to visit Taiwan will be to meet with TSMC, to discuss future collaboration with CC Wei, TSMC's chief executive. This is so AMD can secure enough wafer allocation on future nodes, such as its 3 nm and 2 nm class nodes. The move to these nodes is obviously not happening in the near future for AMD, but considering that TSMC is currently the leading foundry and is operating at capacity, it makes sense to get in early, as the competition is stiff when it comes to getting wafer allocation on cutting edge nodes. It's unclear which exact 3 nm class node AMD will be aiming for, but it might be the N3P node, which is said to kick off production sometime next year. Lisa Su is also said to have meetings with TSMC, SPIL and Ase Technology when it comes to advanced packaging for AMD's products. This includes technologies such as chip-on-wafer-on-substrate (CoWoS) and fan-out embedded bridge (FO-EB), with AMD already being expected to use some of these technologies in its upcoming Navi 3x GPUs.