- Joined
- Oct 9, 2007
- Messages
- 47,294 (7.53/day)
- Location
- Hyderabad, India
| System Name | RBMK-1000 |
|---|---|
| Processor | AMD Ryzen 7 5700G |
| Motherboard | ASUS ROG Strix B450-E Gaming |
| Cooling | DeepCool Gammax L240 V2 |
| Memory | 2x 8GB G.Skill Sniper X |
| Video Card(s) | Palit GeForce RTX 2080 SUPER GameRock |
| Storage | Western Digital Black NVMe 512GB |
| Display(s) | BenQ 1440p 60 Hz 27-inch |
| Case | Corsair Carbide 100R |
| Audio Device(s) | ASUS SupremeFX S1220A |
| Power Supply | Cooler Master MWE Gold 650W |
| Mouse | ASUS ROG Strix Impact |
| Keyboard | Gamdias Hermes E2 |
| Software | Windows 11 Pro |
AMD at its 2020 Financial Analyst Day event unveiled its upcoming CDNA GPU-based compute accelerator architecture. CDNA will complement the company's graphics-oriented RDNA architecture. While RDNA powers the company's Radeon Pro and Radeon RX client- and enterprise graphics products, CDNA will power compute accelerators such as Radeon Instinct, etc. AMD is having to fork its graphics IP to RDNA and CDNA due to what it described as market-based product differentiation.
Data centers and HPCs using Radeon Instinct accelerators have no use for the GPU's actual graphics rendering capabilities. And so, at a silicon level, AMD is removing the raster graphics hardware, the display and multimedia engines, and other associated components that otherwise take up significant amounts of die area. In their place, AMD is adding fixed-function tensor compute hardware, similar to the tensor cores on certain NVIDIA GPUs.



AMD also talked about giving its compute GPUs advanced HBM2e memory interfaces, Infinity Fabric interconnect in addition to PCIe, etc. The company detailed a brief roadmap of CDNA looking as far into the future as 2021-22. The company's current-generation compute accelerators are based on the dated "Vega" architectures, and are essentially reconfigured "Vega 20" GPUs that lack tensor hardware.
Later this year, the company will introduce its first CDNA GPU based on "7 nm" process, compute unit IPC rivaling RDNA, and tensor hardware that accelerates AI DNN building and training.
Somewhere between 2021 and 2022, AMD will introduce its updated CDNA2 architecture based on an "advanced process" that AMD hasn't finalized yet. The company is fairly confident that "Zen4" CPU microarchitecture will leverage 5 nm, but hasn't been clear about the same for CDNA2 (both launch around the same time). Besides ramping up IPC, compute units, and other things, the design focus with CDNA2 will be hyper-scalability (the ability to scale GPUs across vast memory pools spanning thousands of nodes). AMD will leverage its 3rd generation Infinity Fabric interconnect and cache-coherent unified memory to accomplish this.
Much like Intel's Compute eXpress Link (CXL) and PCI-Express gen 5.0, Infinity Fabric 3.0 will support shared memory pools between CPUs and GPUs, enabling scalability of the kind required by exascale supercomputers such as the US-DoE's upcoming "El Capitan" and "Frontier." Cache coherent unified memory reduces unnecessary data-transfers between the CPU-attached DRAM memory and the GPU-attached HBM. CPU cores will be able to directly process various serial-compute stages of a GPU compute operation by directly talking to the GPU-attached HBM and not pulling data to its own main memory. This greatly reduces I/O stress. "El Capitan" is an "all-AMD" supercomputer with up to 2 exaflops (that's 2,000 petaflops or 2 million TFLOPs) peak throughput. It combines AMD EPYC "Genoa" CPUs based on the "Zen4" microarchitecture, with GPUs likely based on CDNA2, and Infinity Fabric 3.0 handling I/O.
Oh the software side of things, AMD's latest ROCm open-source software infrastructure will bring CDNA and CPUs together, by providing a unified programming model rivaling Intel's OneAPI and NVIDIA CUDA. A platform-agnostic API compatible with any GPU will be combined with a CUDA to HIP translation layer.
View at TechPowerUp Main Site
Data centers and HPCs using Radeon Instinct accelerators have no use for the GPU's actual graphics rendering capabilities. And so, at a silicon level, AMD is removing the raster graphics hardware, the display and multimedia engines, and other associated components that otherwise take up significant amounts of die area. In their place, AMD is adding fixed-function tensor compute hardware, similar to the tensor cores on certain NVIDIA GPUs.

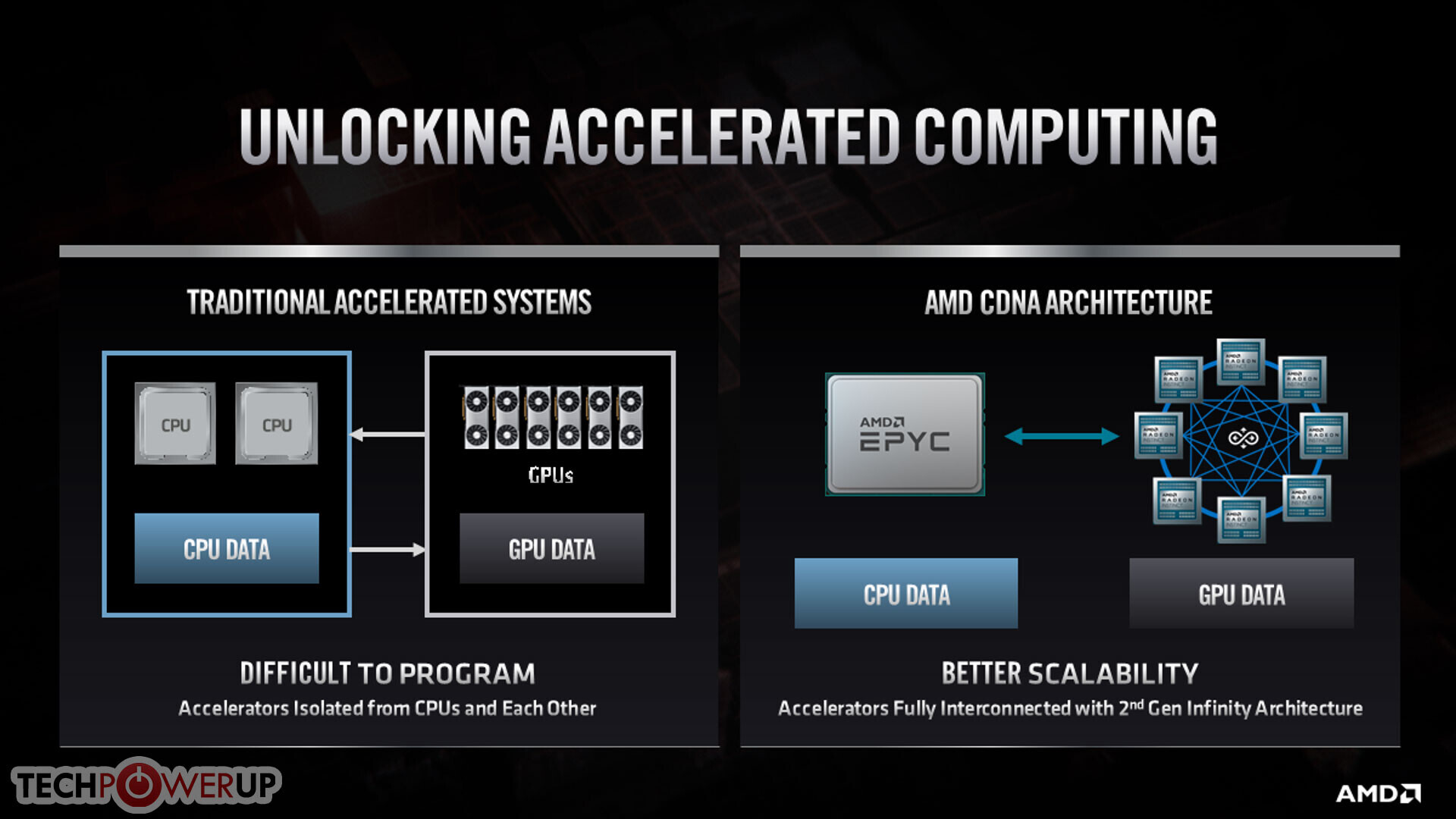

AMD also talked about giving its compute GPUs advanced HBM2e memory interfaces, Infinity Fabric interconnect in addition to PCIe, etc. The company detailed a brief roadmap of CDNA looking as far into the future as 2021-22. The company's current-generation compute accelerators are based on the dated "Vega" architectures, and are essentially reconfigured "Vega 20" GPUs that lack tensor hardware.
Later this year, the company will introduce its first CDNA GPU based on "7 nm" process, compute unit IPC rivaling RDNA, and tensor hardware that accelerates AI DNN building and training.
Somewhere between 2021 and 2022, AMD will introduce its updated CDNA2 architecture based on an "advanced process" that AMD hasn't finalized yet. The company is fairly confident that "Zen4" CPU microarchitecture will leverage 5 nm, but hasn't been clear about the same for CDNA2 (both launch around the same time). Besides ramping up IPC, compute units, and other things, the design focus with CDNA2 will be hyper-scalability (the ability to scale GPUs across vast memory pools spanning thousands of nodes). AMD will leverage its 3rd generation Infinity Fabric interconnect and cache-coherent unified memory to accomplish this.
Much like Intel's Compute eXpress Link (CXL) and PCI-Express gen 5.0, Infinity Fabric 3.0 will support shared memory pools between CPUs and GPUs, enabling scalability of the kind required by exascale supercomputers such as the US-DoE's upcoming "El Capitan" and "Frontier." Cache coherent unified memory reduces unnecessary data-transfers between the CPU-attached DRAM memory and the GPU-attached HBM. CPU cores will be able to directly process various serial-compute stages of a GPU compute operation by directly talking to the GPU-attached HBM and not pulling data to its own main memory. This greatly reduces I/O stress. "El Capitan" is an "all-AMD" supercomputer with up to 2 exaflops (that's 2,000 petaflops or 2 million TFLOPs) peak throughput. It combines AMD EPYC "Genoa" CPUs based on the "Zen4" microarchitecture, with GPUs likely based on CDNA2, and Infinity Fabric 3.0 handling I/O.
Oh the software side of things, AMD's latest ROCm open-source software infrastructure will bring CDNA and CPUs together, by providing a unified programming model rivaling Intel's OneAPI and NVIDIA CUDA. A platform-agnostic API compatible with any GPU will be combined with a CUDA to HIP translation layer.
View at TechPowerUp Main Site





