NVIDIA "Blackwell" GeForce RTX to Feature Same 5nm-based TSMC 4N Foundry Node as GB100 AI GPU
Following Monday's blockbuster announcements of the "Blackwell" architecture and NVIDIA's B100, B200, and GB200 AI GPUs, all eyes are now on its client graphics derivatives, or the GeForce RTX GPUs that implement "Blackwell" as a graphics architecture. Leading the effort will be the new GB202 ASIC, a successor to the AD102 powering the current RTX 4090. This will be NVIDIA's biggest GPU with raster graphics and ray tracing capabilities. The GB202 is rumored to be followed by the GB203 in the premium segment, the GB205 a notch lower, and the GB206 further down the stack. Kopite7kimi, a reliable source with NVIDIA leaks, says that the GB202 silicon will be built on the same TSMC 4N foundry node as the GB100.
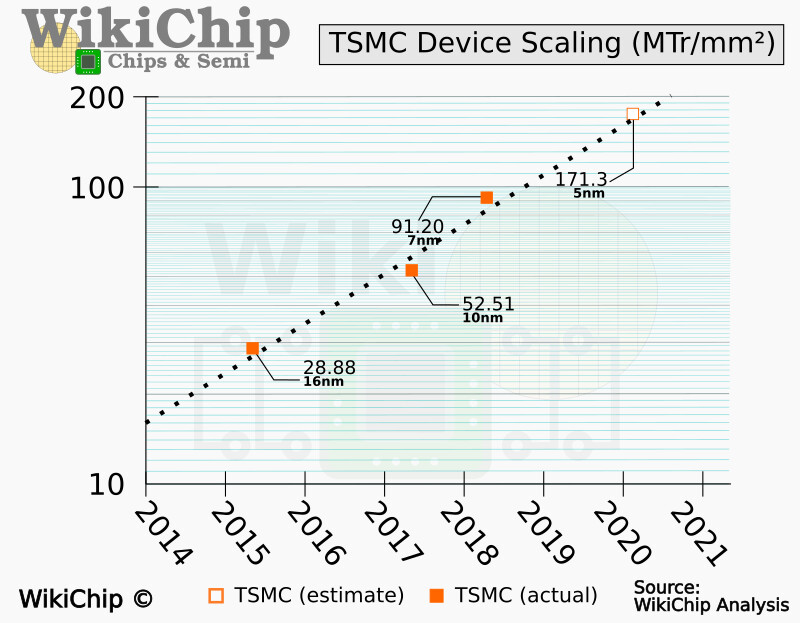
TSMC 4N is a derivative of the company's mainline N4P node, the "N" in 4N stands for NVIDIA. This is a nodelet that TSMC designed with optimization for NVIDIA SoCs. TSMC still considers the 4N as a derivative of the 5 nm EUV node. There is very little public information on the power- and transistor density improvements of the TSMC 4N over TSMC N5. For reference, the N4P, which TSMC regards as a 5 nm derivative, offers a 6% transistor-density improvement, and a 22% power efficiency improvement. In related news, Kopite7kimi says that with "Blackwell," NVIDIA is focusing on enlarging the L1 caches of the streaming multiprocessors (SM), which suggests a design focus on increasing the performance at an SM-level.
TSMC 4N is a derivative of the company's mainline N4P node, the "N" in 4N stands for NVIDIA. This is a nodelet that TSMC designed with optimization for NVIDIA SoCs. TSMC still considers the 4N as a derivative of the 5 nm EUV node. There is very little public information on the power- and transistor density improvements of the TSMC 4N over TSMC N5. For reference, the N4P, which TSMC regards as a 5 nm derivative, offers a 6% transistor-density improvement, and a 22% power efficiency improvement. In related news, Kopite7kimi says that with "Blackwell," NVIDIA is focusing on enlarging the L1 caches of the streaming multiprocessors (SM), which suggests a design focus on increasing the performance at an SM-level.