 348
348
AMD Radeon R9 Fury X 4 GB Review
Packaging & Contents »Architecture
At the heart of the Radeon R9 Fury X is the most talked about GPU of the season, codenamed "Fiji." It is a multi-chip module of three important components - the GPU die itself, built on TSMC's 28 nm process, a specially designed silicon substrate layer that seats and connects the GPU die with the HBM memory stacks, called interposer and built by UMC on its 65 nm process, and four 1 GB HBM stacks made by SK Hynix on a 20 nm-class node. AMD had technical assistance from some of the industry's brightest VLSI teams, including from UMC, Amkor Technology, ASE Group, and SK Hynix.Let's begin with the GPU die itself. It features a familiar component hierarchy to the previous-generation "Hawaii" silicon. The Graphics CoreNext stream processors, however, are of a newer generation, GCN 1.2, which made its debut with the "Tonga" silicon that powers the Radeon R9 380 and R9 285.
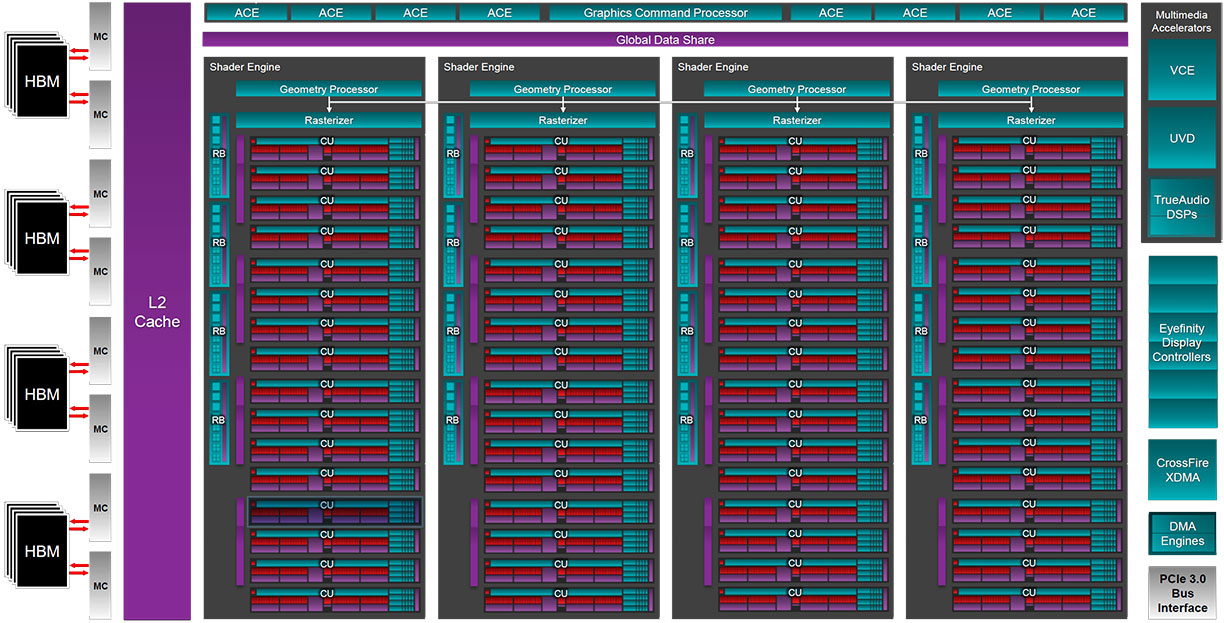
The GPU die features four shader engines, just like "Hawaii," but the compute unit (CU) count per shader engine has been increased to 16 from the 11 on "Hawaii." Each CU packs 64 stream processors, so there are 1,024 stream processors per engine and 4,096 on the chip in total. There are 16 render back-ends, which is the same as in "Hawaii," so the ROP count remains the same at 64. The higher CU count, however, means that the TMU count is at 256 instead of the 176 on "Hawaii." The biggest change, however, is the 4096-bit wide HBM interface which wires out to four 8 Gigabit HBM stacks.
AMD didn't announce any changes to the ancillaries - the multimedia engine, XDMA CrossFire (no bridge cables required), display controllers with support for DisplayPort 1.2a and HDMI 1.4a, and PCI-Express gen 3.0 x16 host interface remain the same as on "Hawaii." There is one notable change, though, since the reference design card lacks DVI connectors. It features three DP 1.2a and one HDMI ports. All ports are on the first slot elevation, making this card truly single-slot capable with aftermarket liquid-cooling blocks (the piggybacked DVI connector that extends into the second slot denies NVIDIA cards this cool feature unless you're skillful enough to solder out the DVI connector without accidentally shorting any pins).
High Bandwidth Memory and Interposer
With Windows 10 and its companion DirectX 12 API on the horizon, and high display resolutions such as 1440p and 4K Ultra HD getting increasingly more affordable - 1440p displays start at $250 and 4K starts at $400 if you know where to look - the demands on video memory to catch up have never been higher. GDDR5 served the industry well since its debut in 2008. It has driven five generations of GPUs since, but is approaching its design limitation for performance upscaling through clock-speed increases.
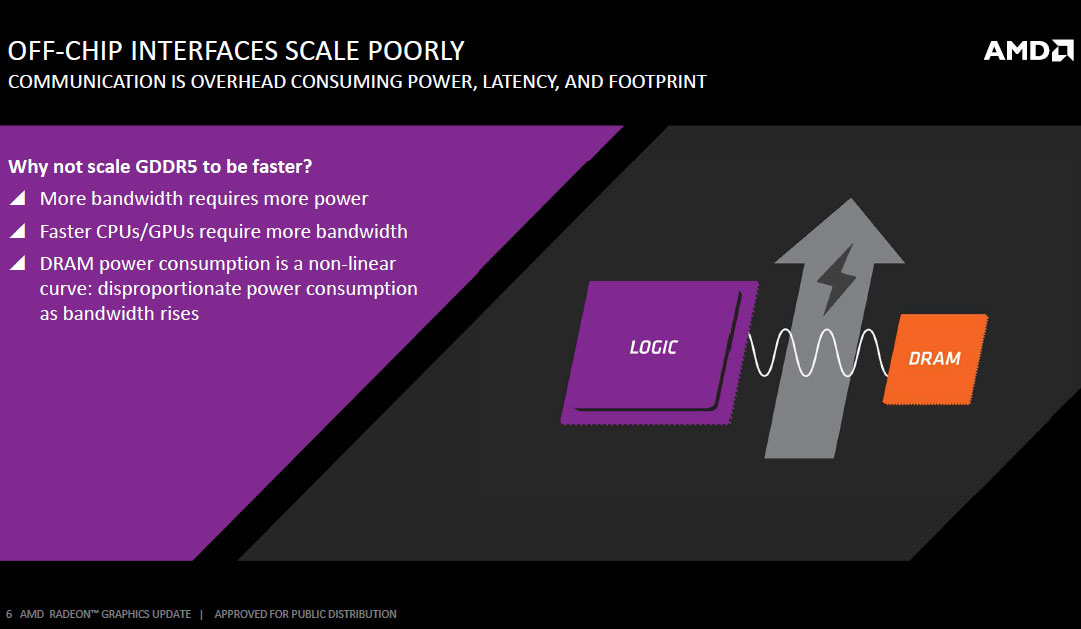
For any memory standard (including HBM), memory speed/bandwidth and power draw don't scale linearly. Beyond a point, the equation tapers too much in favor of power requirements, and so, an increasingly disproportionate amount of power is required to achieve higher clocks. This is what necessitates a new memory standard. HBM is just starting out on that same curve, and hence, has much better energy efficiency than GDDR5. HBM trades frequency for bus-width and offers vertical stacking of DRAM dies. This generation of HBM allows vertical stacking of up to four DRAM dies, with a fifth logic die holding the PHY and connections out of the stack.
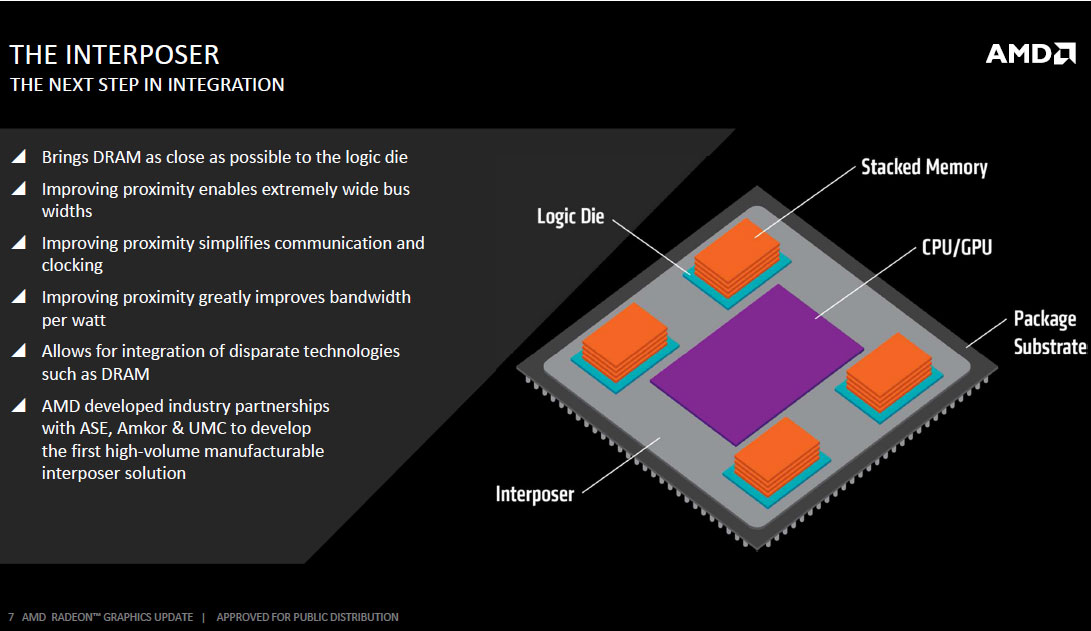
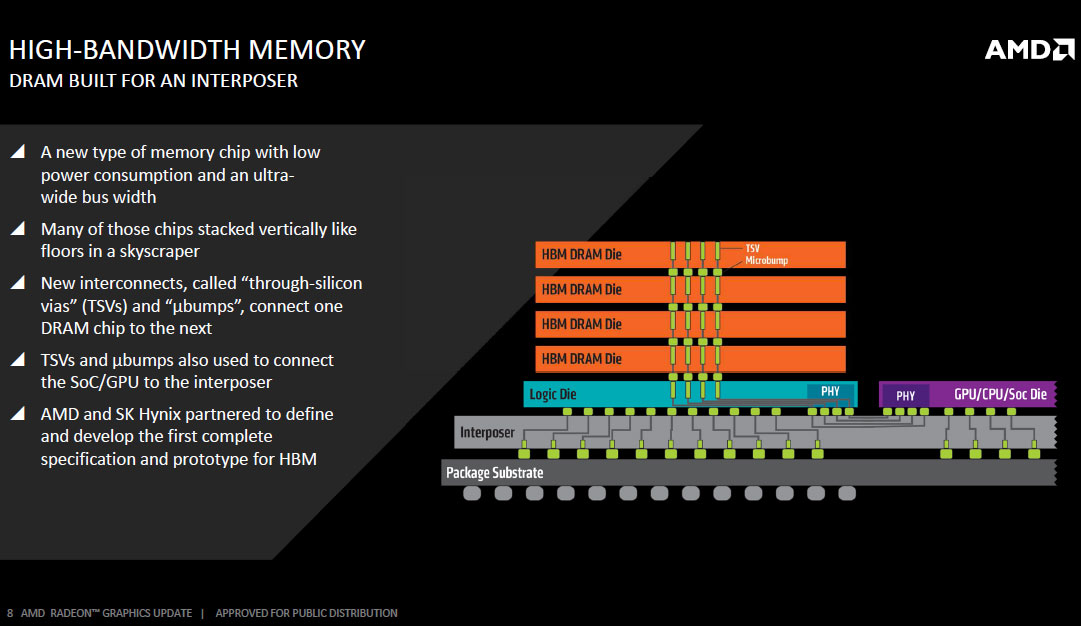
The Fiji package features four 8 Gb HBM stacks, each with 1,024-bit wide memory bus. Since such a wide bus per stack would take up an obscene number of pins on a standalone memory chip package, AMD decided to integrate it into the GPU package, using a specially designed substrate called the interposer to deal with the wiring problem.
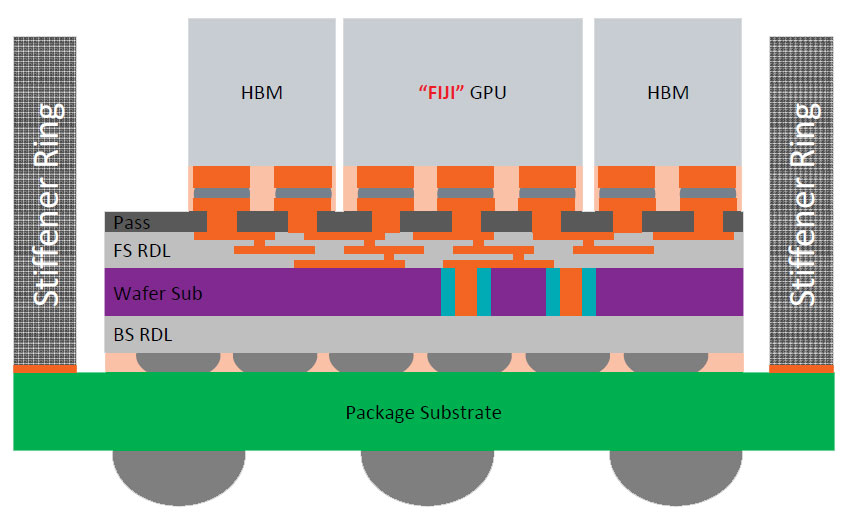
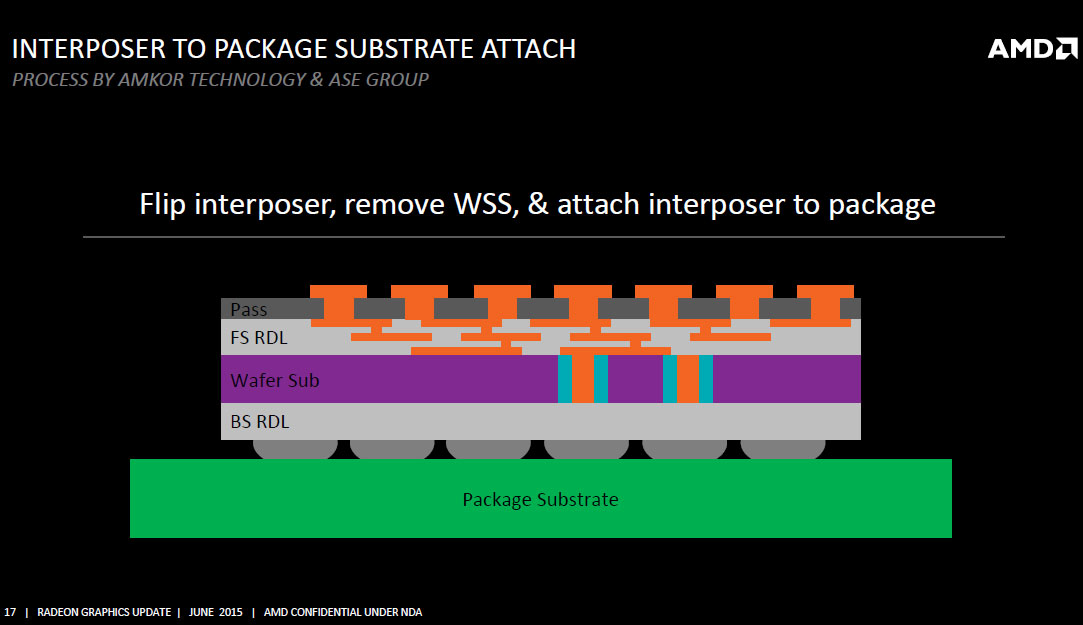
The interposer is essentially a very large silicon die that acts as a substrate for other dies. There's no number crunching or storage happening here as there is just a vast network of microscopic wires running between the HBM stacks and the GPU die. The interposer is built on a 65 nanometer silicon fab node. It may not sound like much in the 20 nm-class era, but compared to conventional fiberglass PCB wiring, wires on the 65 nm node are infinitesimally smaller, as are bumps, points of contact between two dies or between a die and a substrate. AMD innovated microscopic bumps specifically for contact between the GPU die and the interposer because wiring between the GPU and the memory is just so dense.

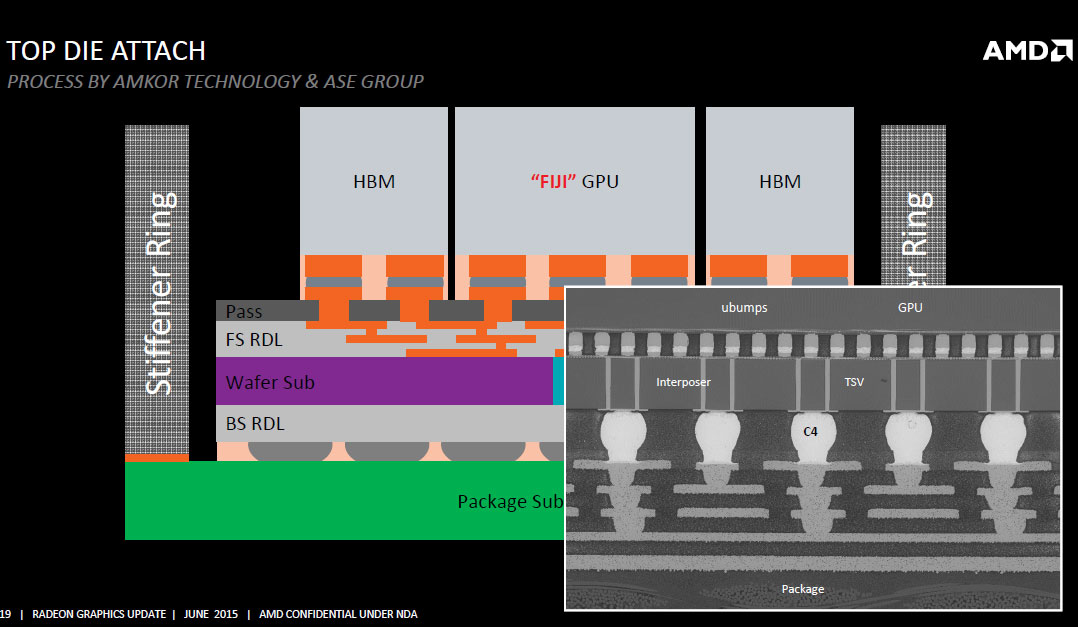
The interposer has microscopic bumps on the side that faces toward the GPU die and HBM stacks and conventional bumps, also on the side, that face toward the main fiberglass substrate of the GPU package. With the memory moved to the GPU package, and more importantly, the most sensitive wiring of the video card (that between the memory and GPU) moved to the GPU package, there's not much action on the PCB. The pins on the package are for power, system bus, and display I/O, which gives AMD greater quality control.


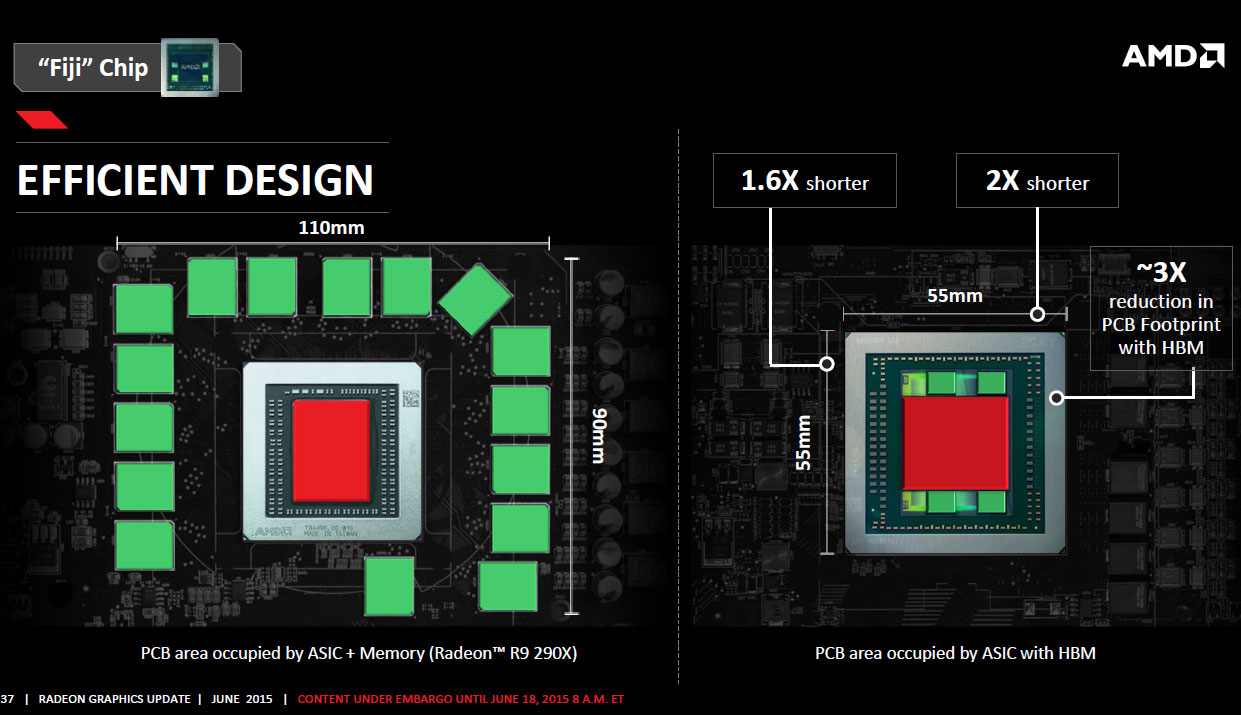
Another major benefit of moving the memory to the GPU package, however, is the savings in PCB real-estate. Sure, the package in itself is bigger than "Hawaii" or any GPU ever made, but since there are no memory chips surrounding it, all that's left on the video card's PCB are the GPU package, VRM, and display I/O. This allows AMD to create some extremely compact products. The reference PCB of the Radeon R9 Fury X is just 19 cm long. Dual GPU video card PCBs made using this chip will be smaller than even single-GPU cards made using "Hawaii," which should also benefit notebook MXM designers.
Apr 10th, 2025 08:58 EDT
change timezone
Latest GPU Drivers
New Forum Posts
- Your PC ATM (35332)
- Do you use Linux? (576)
- Thermal testing two different size Gigabyte 5070 Ti cards - huge differences (21)
- Technical Issues - TPU Main Site & Forum (2025) (90)
- Looking for input on fan placement for my Define R5 (11)
- How is the Gainward Phoenix Model in terms of quality? (6)
- DTS DCH Driver for Realtek HDA [DTS:X APO4 + DTS Interactive] (2131)
- Microcenter GPU Stock status (72)
- Asking before I mess up (19)
- Can you guess Which game it is? (66)
Popular Reviews
- The Last Of Us Part 2 Performance Benchmark Review - 30 GPUs Compared
- ASRock Z890 Taichi OCF Review
- MCHOSE L7 Pro Review
- Sapphire Radeon RX 9070 XT Pulse Review
- PowerColor Radeon RX 9070 Hellhound Review
- Upcoming Hardware Launches 2025 (Updated Apr 2025)
- Sapphire Radeon RX 9070 XT Nitro+ Review - Beating NVIDIA
- Acer Predator GM9000 2 TB Review
- ASUS GeForce RTX 5080 Astral OC Review
- Zotac GeForce RTX 5070 Ti Amp Extreme Review
Controversial News Posts
- NVIDIA GeForce RTX 5060 Ti 16 GB SKU Likely Launching at $499, According to Supply Chain Leak (174)
- MSI Doesn't Plan Radeon RX 9000 Series GPUs, Skips AMD RDNA 4 Generation Entirely (146)
- Microsoft Introduces Copilot for Gaming (124)
- AMD Radeon RX 9070 XT Reportedly Outperforms RTX 5080 Through Undervolting (119)
- NVIDIA Reportedly Prepares GeForce RTX 5060 and RTX 5060 Ti Unveil Tomorrow (115)
- Nintendo Confirms That Switch 2 Joy-Cons Will Not Utilize Hall Effect Stick Technology (100)
- Over 200,000 Sold Radeon RX 9070 and RX 9070 XT GPUs? AMD Says No Number was Given (100)
- Nintendo Switch 2 Launches June 5 at $449.99 with New Hardware and Games (99)