 223
223
AMD Radeon Vega GPU Architecture
Conclusion »Next Generation Geometry, Compute, and Pixel Engine
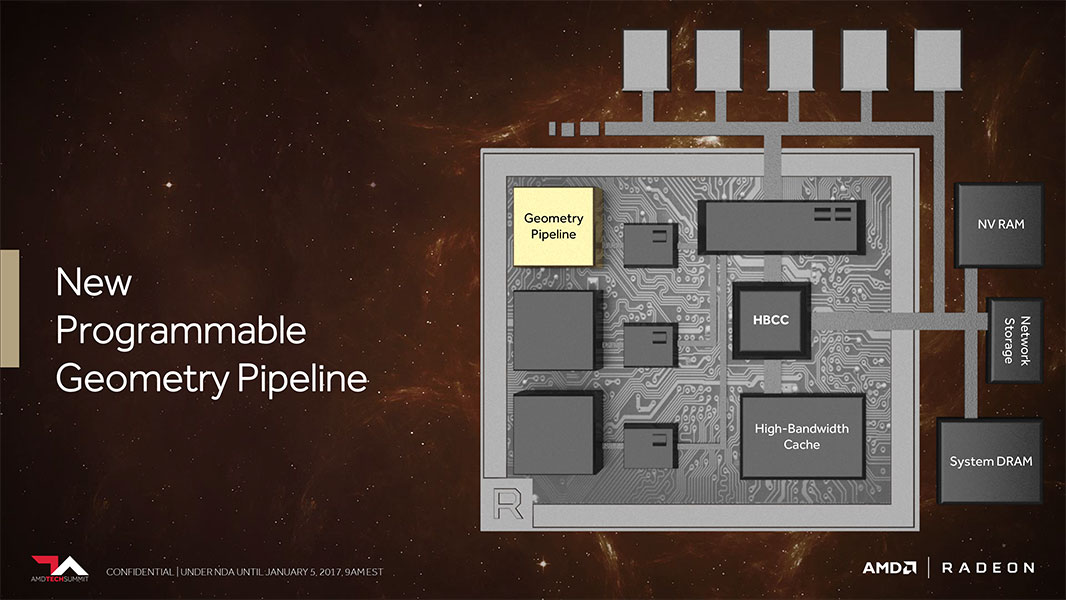



AMD improved the geometry processing machinery available to previous generations with "Vega." The new generation programmable geometry pipeline has over two times the peak throughput per clock. Vega now supports primitive shaders, besides the contemporary vertex and geometry shaders. AMD has also improved the way it distributes workloads between the geometry, compute, and pixel engines. A primitive shader is a new type of low-level shader that gives the developer more freedom to specify all the shading stages they want to use, and run those at a higher rate because they are now decoupled from the traditional DirectX shader pipeline model. While ideally the developer would perform that optimization, AMD also has the ability to use their graphics driver to predefine cases for a game, in which a number of DirectX shaders can be replaced by a single primitive shader for improved performance.
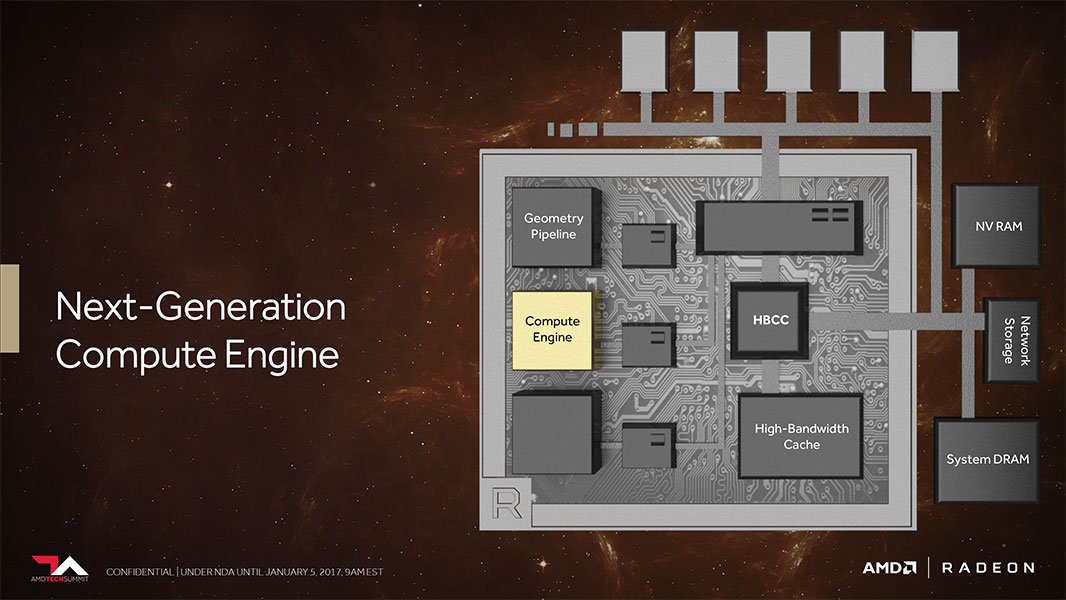

The compute unit (CU) is the basic, heavily parallelized number-crunching machinery of the GPU. With "Vega," AMD improved the functionality of the CUs, which it now calls NCUs (next-generation compute units), by adding support for super-simple 8-bit ops, in addition to the 16-bit ops (FP16) introduced with "Polaris" and the conventional single- and double-precision floating point ops support on older generations. Support for 8-bit ops lets game developers simplify their code, so if it falls within the memory footprint of the 8-bit address space, 512 of them can be crunched per clock cycle.


AMD also introduced a new feature called "Rapid Packed Math" in which it clumps multiple 16-bit operations between 32-bit registers for more simple work done per clock. Thanks to these improvements, the Vega NCU is able to crunch four times the operations per clock cycle as the previous generation, as well as run at double the clock speed. AMD has carried over its memory bandwidth-saving lossless compression algorithms. Lastly, AMD improved the pixel-engine with a new-generation draw-stream binning rasterizer. This conserves clock cycles, which helps with on-die cache locality and memory footprint.
AMD changed the hierarchy of the GPU in a way that improves performance of apps that use deferred shading. The geometry pipeline, the compute engine, and and the pixel engine, which output to the ROPs (L1 caches), are now tied to the L2 cache. Earlier, the pixel and texture engines had non-coherent memory access in which the pixel engine wrote to the memory controller.
Feb 22nd, 2025 06:32 EST
change timezone
Latest GPU Drivers
New Forum Posts
- Warning about DOCP (10)
- Nvidia's GPU market share hits 90% in Q4 2024 (gets closer to full monopoly) (472)
- The Apocalypse is Near. (3)
- It's happening again, melting 12v high pwr connectors (850)
- The TPU UK Clubhouse (25747)
- RTX 5070 Ti Benelux pricing. It hurts (11)
- Is this thermal paste or phase change pad? (1)
- 2022-X58/1366 PIN Motherboards NVME M.2 SSD BIOS MOD Collection (886)
- PBO issues on ASRock B650 PG Lightning (11)
- can you use 2 of the same model "centers" as 2.0 ? (0)
Popular Reviews
- MSI GeForce RTX 5070 Ti Ventus 3X OC Review
- Gigabyte GeForce RTX 5090 Gaming OC Review
- Galax GeForce RTX 5070 Ti 1-Click OC White Review
- ASUS GeForce RTX 5070 Ti TUF OC Review
- Ducky One X Inductive Keyboard Review
- MSI GeForce RTX 5070 Ti Vanguard SOC Review
- MSI GeForce RTX 5070 Ti Gaming Trio OC+ Review
- darkFlash DY470 Review
- MSI MAG Z890 Tomahawk Wi-Fi Review
- Palit GeForce RTX 5070 Ti GameRock OC Review
Controversial News Posts
- NVIDIA GeForce RTX 5090 Spotted with Missing ROPs, NVIDIA Confirms the Issue, Multiple Vendors Affected, RTX 5070 Ti, Too (303)
- AMD Radeon 9070 XT Rumored to Outpace RTX 5070 Ti by Almost 15% (302)
- AMD Plans Aggressive Price Competition with Radeon RX 9000 Series (269)
- AMD is Taking Time with Radeon RX 9000 to Optimize Software and FSR 4 (256)
- AMD Radeon RX 9070 and 9070 XT Listed On Amazon - One Buyer Snags a Unit (247)
- Edward Snowden Lashes Out at NVIDIA Over GeForce RTX 50 Pricing And Value (241)
- AMD Denies Radeon RX 9070 XT $899 USD Starting Price Point Rumors (239)
- New Leak Reveals NVIDIA RTX 5080 Is Slower Than RTX 4090 (215)