 115
115
Intel Lunar Lake Technical Deep Dive - So many Revolutions in One Chip
Battlemage Xe2 Graphics »The Real Star of Lunar Lake: the Skymont E-core


When Intel started packing E-cores in its mainline processors with Lakefield, it was seen as a lazy way to shore up CPU core counts. With the arrival of the 12th Gen Core Alder Lake, it became clear that Intel was on to something—that client PCs really don't need a mountain of CPU cores, and that a fewer P-cores can deal with the heavy stuff, and much of client computing is light-thru-medium workloads that can be processed by small efficient cores at a fraction of the power of the P-core, even with its best power management and lowest clock multiplier. This was only amplified with "Raptor Lake," where Intel dialed up the number of E-cores, but not the P-cores.
Having achieved a great performance/power figure with Gracemont, and its successor, the Crestmont E-core, which provided a 4% IPC uplift, Intel decided to embark on an experiment. The question was "what if we spruced up the E-core within its performance/power curve," it hence arrived at Skymont, the E-core muscle of Lunar Lake and the upcoming Arrow Lake.
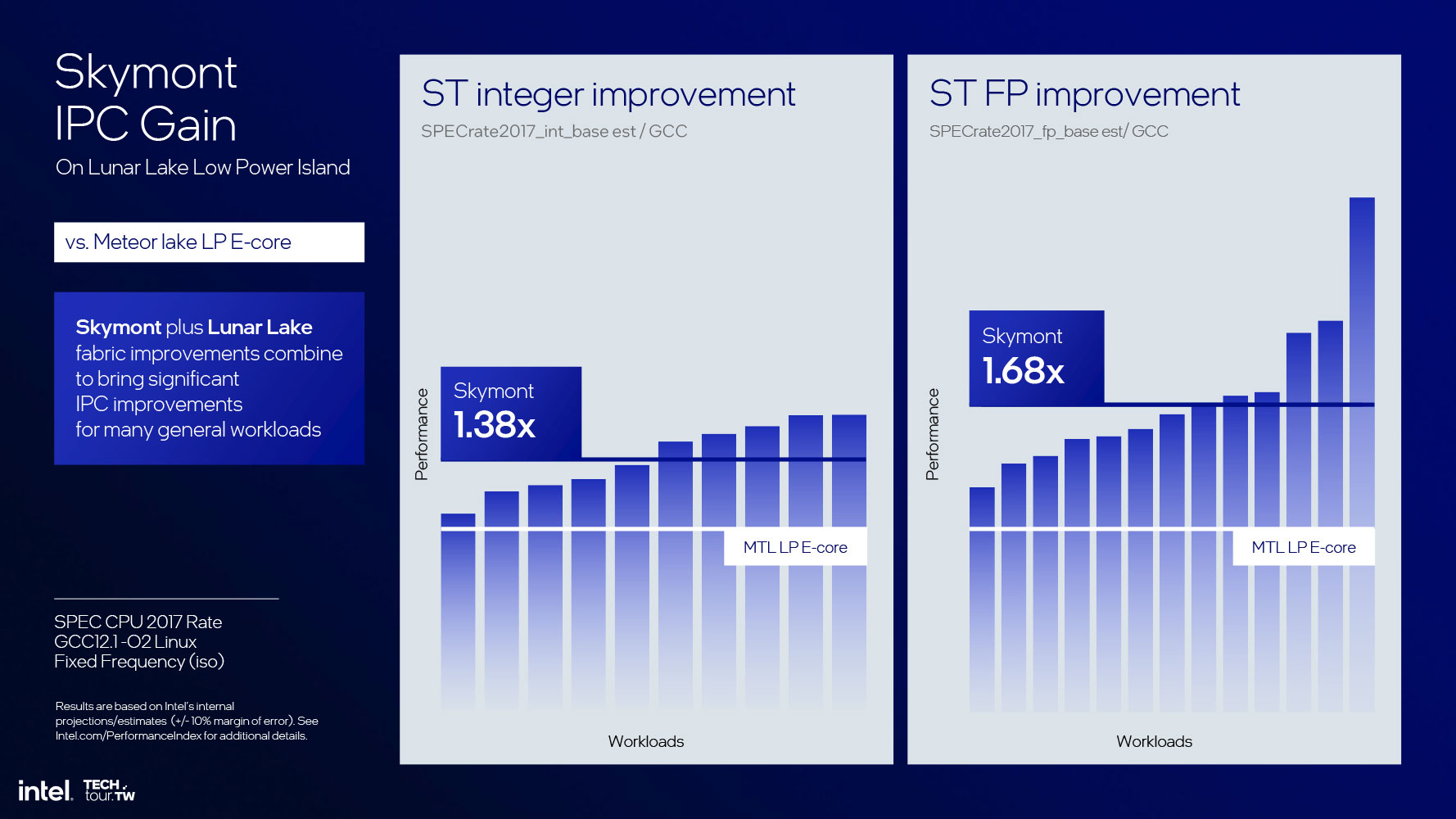
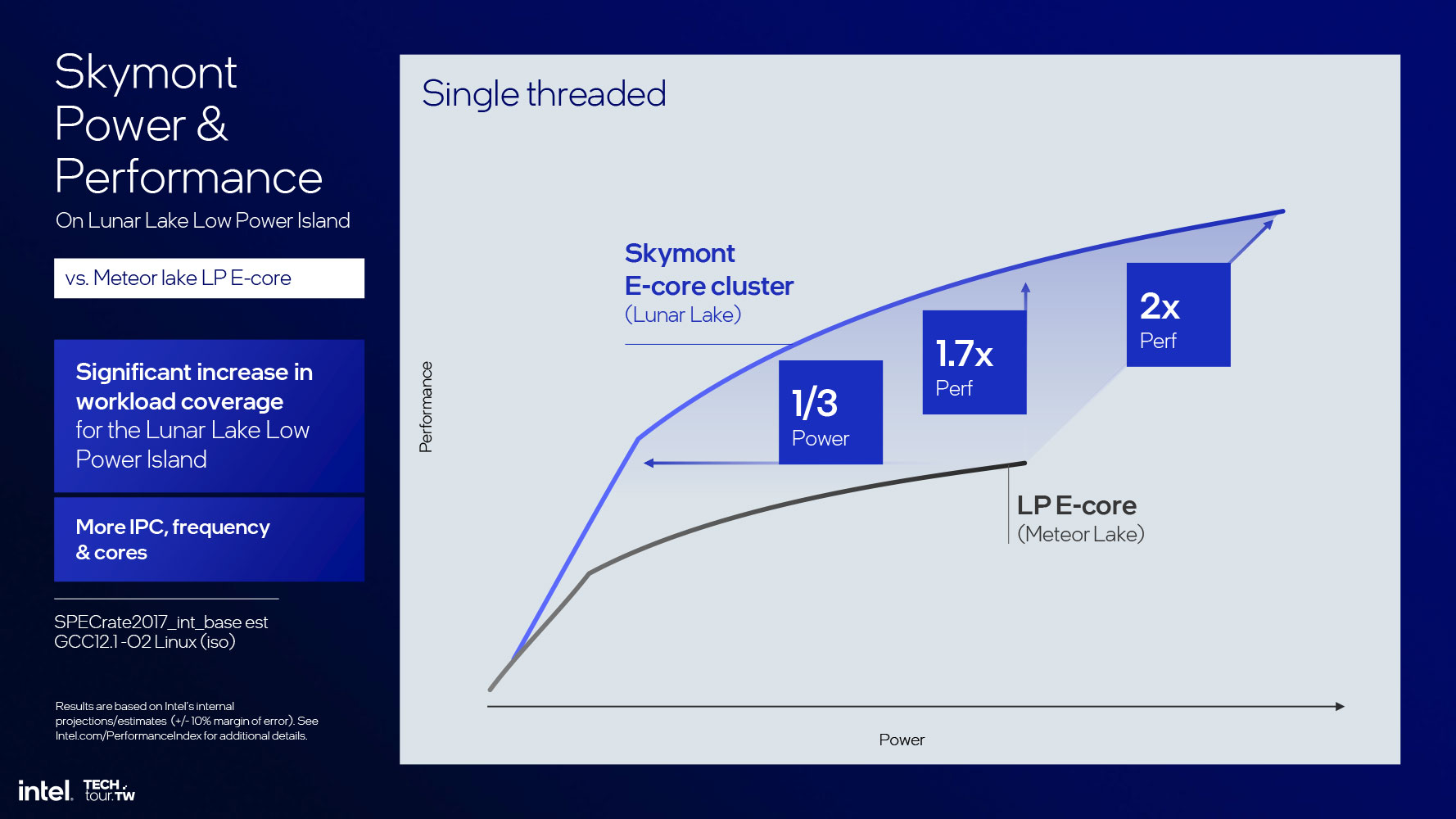
Before we get into the nuts and bolts of the core, let's talk about what Intel achieved: a whopping 68% IPC increase over Crestmont (as the low-power island E-core on Meteor Lake). This is a valid comparison, as the Skymont E-core cluster isn't part of the P-core ring, but an island (while being on the same Compute tile). At iso-performance, we're looking a 300% performance/power increase. At iso-power, we're looking at a 2.9 times performance increase. When at the peak power possible on Lunar Lake, the core offers as much as four times the performance of a Crestmont LP island core.
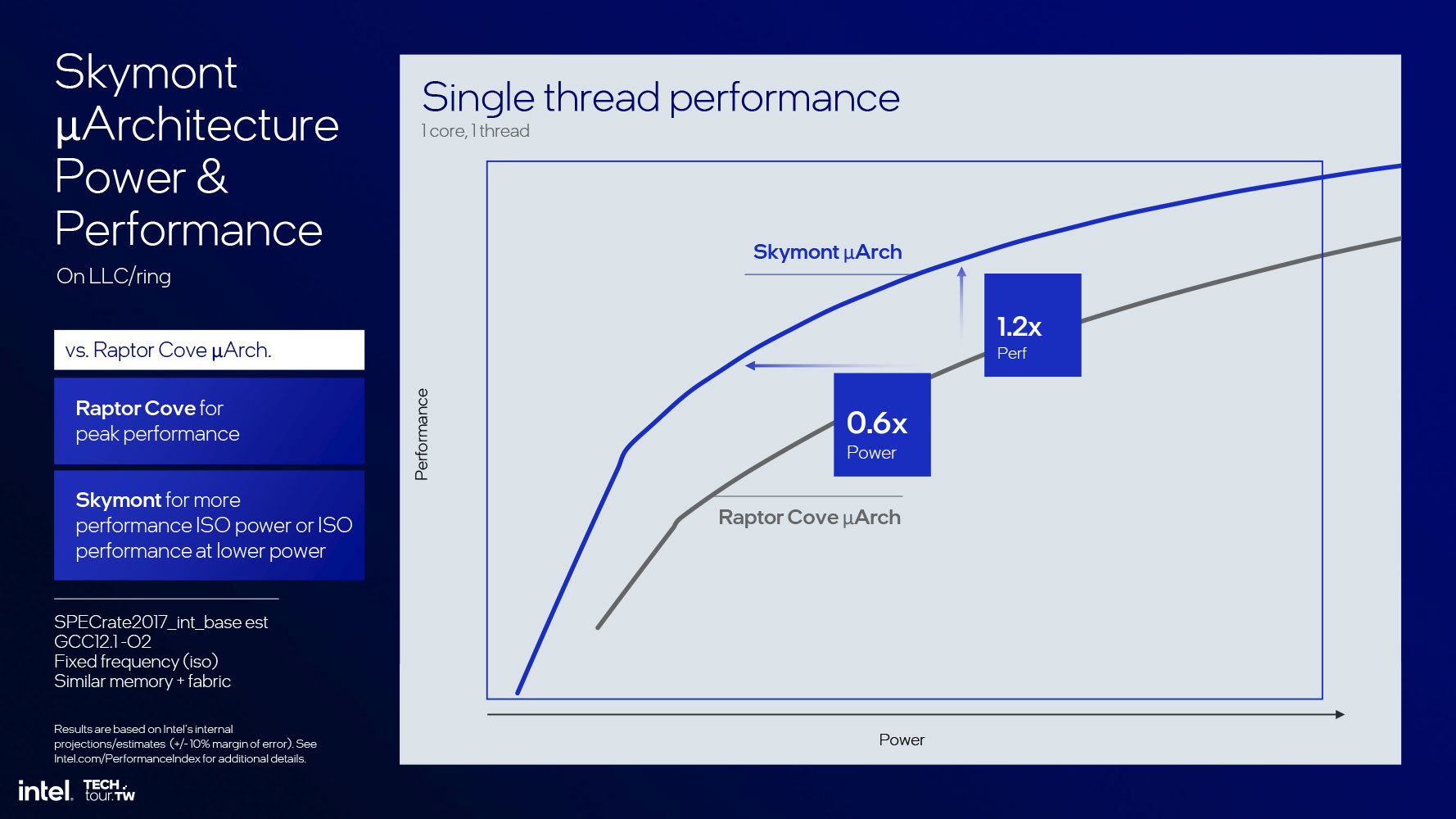
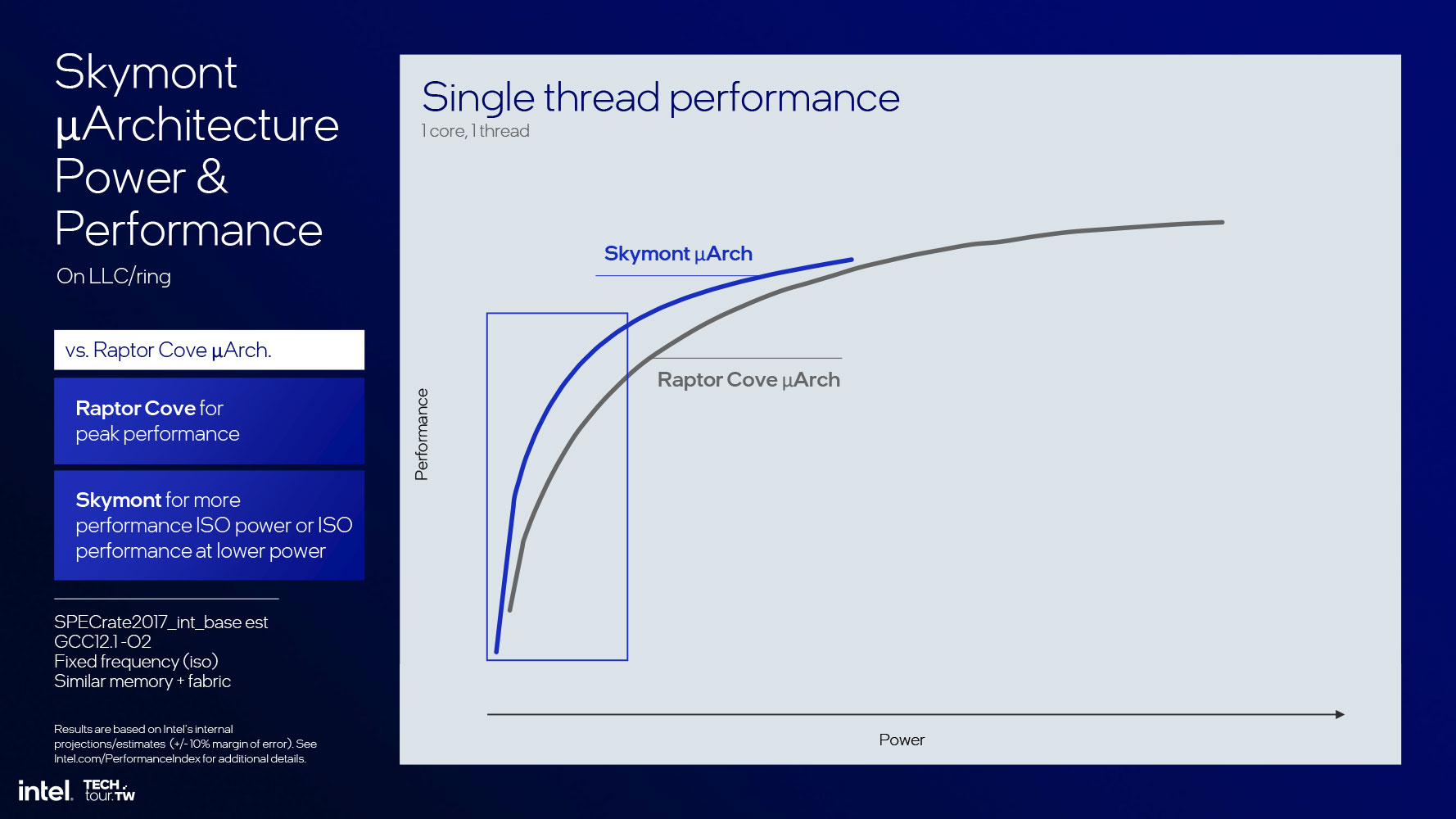
This phenomenal IPC increase is why Intel is not just confident in having only 4 E-cores, but also having them located as an island compute complex; and this is where Intel got the confidence to physically do away with Hyper-Threading on the Lion Cove P-core, and thin down its die footprint. The performance/power curves of Skymont and Lion Cove have a broad intersection, which is how the overall 4P+4E configuration in Lunar Lake is able to offer generational performance gains over Meteor Lake.


Skymont's journey toward becoming something special begins with the fetch and branch prediction unit, which now looks 128 bytes ahead for possible branches, which speeds up the instruction fetch. Up to 96 instruction bytes are fetched in parallel. The front-end sees a new 9-wide decode (compared to 6-wide on Crestmont), support for nano-code (similar segments of microcode clumped together for greater parallelism), and a broader micro-op queue of 96 entries instead of 64 on the previous generation.


The out-of-order engine sees the meat of the updates. The allocation queue is 8-wide (up from 6-wide), and the retire queue is 16-wide (up from 8-wide). There is intelligence behind dependency breaking. The out-of-order window is broadened to 416 entries, up from 256, as are the physical register files, reservation stations, and load-store unit buffering.


There are 26 dispatch ports to the execution engine, leading to 8 Integer ALUs, with 3 jump ports, and 3 loads per cycle (50% increase).

The vector engine features four 128-bit FPUs, doubling GigaFLOPS. The FMUL, FADD, and FMA latencies are reduced. FP rounding now sees native hardware acceleration. Additional execution units should also benefit AI performance. The load/store unit sees 33% to 50% increases in loads, and store address generation performance. The L2 TLB has increased in size to 4,192 entries, up from 3,096.
Lastly, the Skymont E-core cluster sees four cores share a 4 MB L2 cache. Intel has doubled the L2 bandwidth, as well as L1 to L1 transfers among the cores.
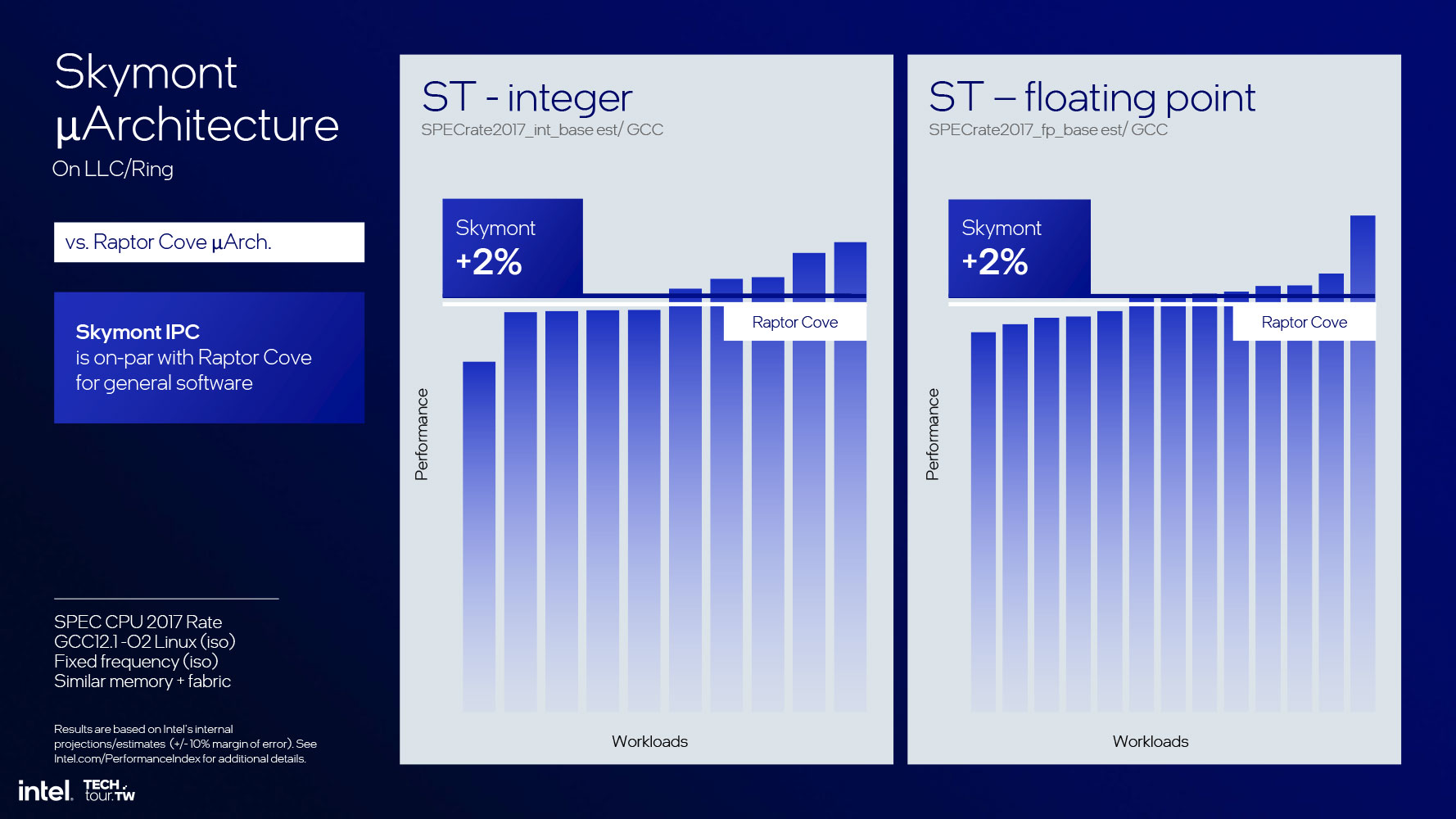
In terms of IPC, the SPECrate2017 Integer benchmark posts a 38% performance increase; and the floating point performance posts a 68% increase over the Crestmont core implemented as a low-power island E-core. Intel is so confident about the IPC of Skymont, that it claims that the IPC is on par with the Raptor Cove P-core that drives the Raptor Lake processor. Now imagine a Zerg swarm of Skymont cores that are a fraction of the die-size of a Raptor Cove, with a fraction of the power, and you can see why Intel has knocked the question of its compute engine out of the park.
Thread Director Improvements

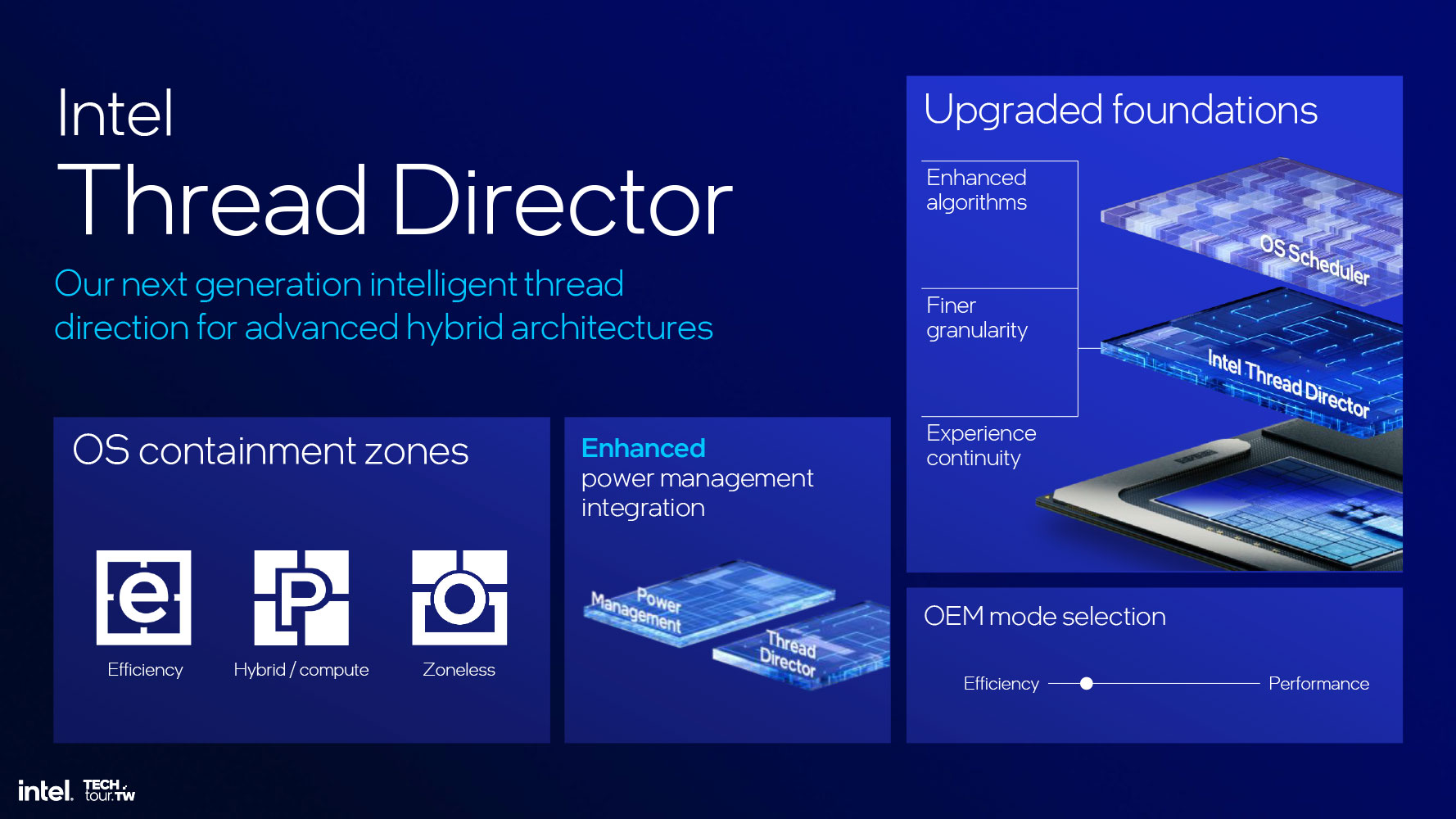
Intel made generational improvements to Thread Director, its hardware component that ensures the right CPU processing load is allocated to the right kind of CPU core, and they migrate correctly. Intel has improved the accuracy and aptitude of its algorithms, and gave the algorithm finer granularity.


This version of Thread Director also introduces OS containment zones, which lets users tag software to be contained to the P-cores, the E-core cluster, or be zoneless. Lunar Lake uses a dynamic scheduling policy that runs everything on E-cores, and graduates them to P-cores based on processing demand.
May 4th, 2025 00:28 EDT
change timezone
Latest GPU Drivers
New Forum Posts
- Technical Issues - TPU Main Site & Forum (2025) (160)
- Are the 8 GB cards worth it? (778)
- Do you use Linux? (612)
- Ssd failure, I don’t know what to do (20)
- Input lag, floaty mouse, delayed keyboard, choppy display. (7)
- Random Colored Dots or Flickering Light Pixels in Some Games – GPU Fault or Just a Visual Bug? (9)
- Modified drivers for X-Fi sound cards. (37)
- Postulation: Is anyone else concerned with the proliferation of AI? (311)
- 7900XT - Lower my GPU too constatly be running 500-600rpm (25)
- random system shutdown with fans running at full speed (74)
Popular Reviews
- Clair Obscur: Expedition 33 Performance Benchmark Review - 33 GPUs Tested
- ASUS Radeon RX 9070 XT TUF OC Review
- ASUS ROG Maximus Z890 Hero Review
- Montech HS02 PRO Review
- NVIDIA GeForce RTX 5060 Ti 8 GB Review - So Many Compromises
- ASUS GeForce RTX 5090 Astral Liquid OC Review - The Most Expensive GPU I've Ever Tested
- Seasonic Vertex GX 850 W Review
- Upcoming Hardware Launches 2025 (Updated Apr 2025)
- ASRock Radeon RX 9070 XT Taichi OC Review - Excellent Cooling
- Team Group GC Pro 2 TB Review
Controversial News Posts
- NVIDIA GeForce RTX 5060 Ti 16 GB SKU Likely Launching at $499, According to Supply Chain Leak (182)
- AMD Radeon RX 9060 XT to Roll Out 8 GB GDDR6 Edition, Despite Rumors (129)
- NVIDIA Sends MSRP Numbers to Partners: GeForce RTX 5060 Ti 8 GB at $379, RTX 5060 Ti 16 GB at $429 (128)
- NVIDIA Launches GeForce RTX 5060 Series, Beginning with RTX 5060 Ti This Week (115)
- Nintendo Confirms That Switch 2 Joy-Cons Will Not Utilize Hall Effect Stick Technology (105)
- NVIDIA PhysX and Flow Made Fully Open-Source (95)
- Sony Increases the PS5 Pricing in EMEA and ANZ by Around 25 Percent (84)
- Parts of NVIDIA GeForce RTX 50 Series GPU PCB Reach Over 100°C: Report (78)