 34
34
MSI Radeon RX 5700 XT Evoke Review
Packaging & Contents »Architecture: Navi and RDNA

We've been hearing the moniker "Navi" for years now, and AMD threw another one at us this Computex, "RDNA", so let us demystify the two first. "Navi" is the codename for the family of silicon the GPU is based on. RDNA is a new architecture introduced by AMD to succeed Graphics Core Next (GCN). It prescribes the GPU's component hierarchy and, more importantly, its main number-crunching machinery, the compute units.
Another example of this distinction would be "Vega". Vega 10, Vega 20, and Vega 12 are pieces of silicon from the same family, while the GPU follows the 5th generation Graphics Core Next architecture governing even its compute units. Over many years, AMD made incremental updates to GCN, but this time, it claims that RDNA is sufficiently different from GCN to not be considered a new version, but rather a new hardware component that brings with it massive IPC gains over the previous generation.




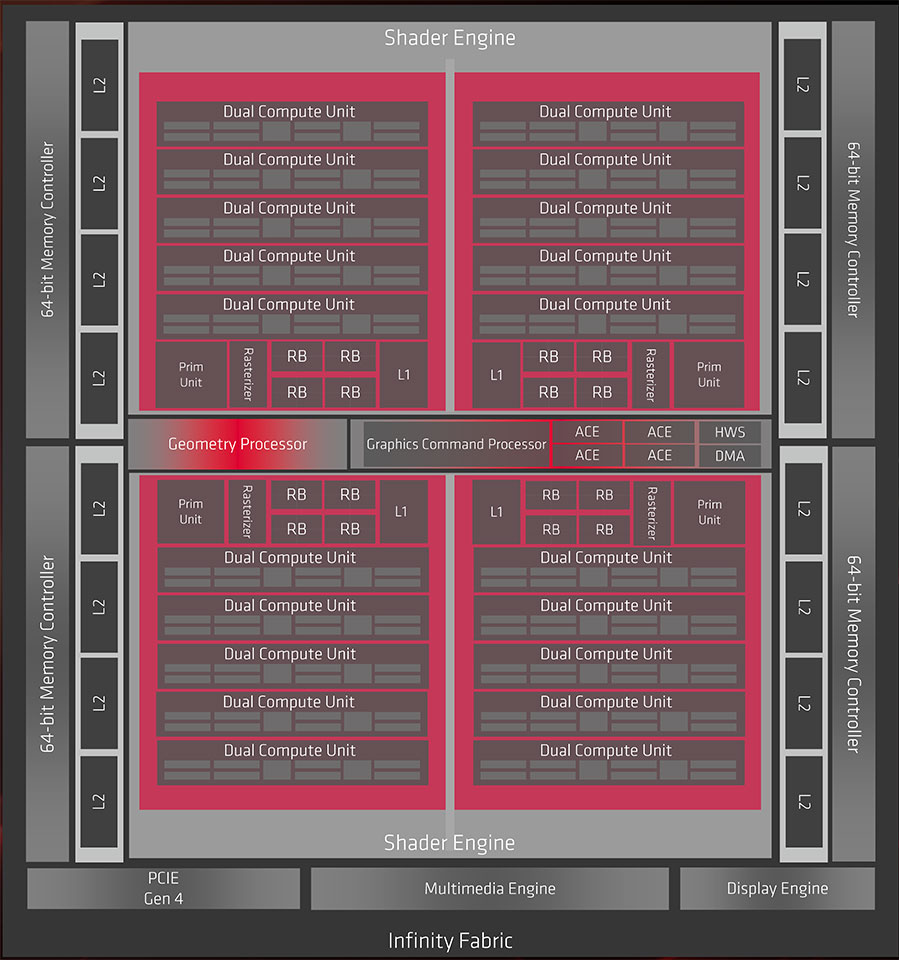
The Radeon RX 5700 series is built around "Navi 10," an elegant little piece of silicon engineered on the 7 nm process at TSMC with 10.3 billion transistors crammed into a die measuring just 251 mm². The chip features a PCI-Express 4.0 x16 bus interface and a 256-bit wide GDDR6 memory interface. Infinity Fabric, which debuted on AMD's Ryzen CPUs, is extensively used as an on-die interconnect linking the various major components.
The bulk of AMD's engineering effort with RDNA has been to increase the number of dedicated resources to avoid starvation by fewer components waiting for access to a resource. The "Navi 10" silicon has two Shader Engines sharing a centralized Command Processor that distributes workloads, a Geometry Processor, and ACEs (asynchronous compute engines).



Each Shader Engine is further divided into two Graphics Engines. A graphics engine shares render backends, a Rasterizer, and a Prim Unit among five Workgroup Processors. This is where the core of RDNA begins. AMD figured it could merge two compute units (CUs) to share schedulers, scalar units, a data-share, instruction and data caches, and TMUs. The Workgroup Processor, or "dual-compute unit" as shown in the architecture block diagram, is for all intents and purposes indivisible, in that individual CUs cannot be disabled.

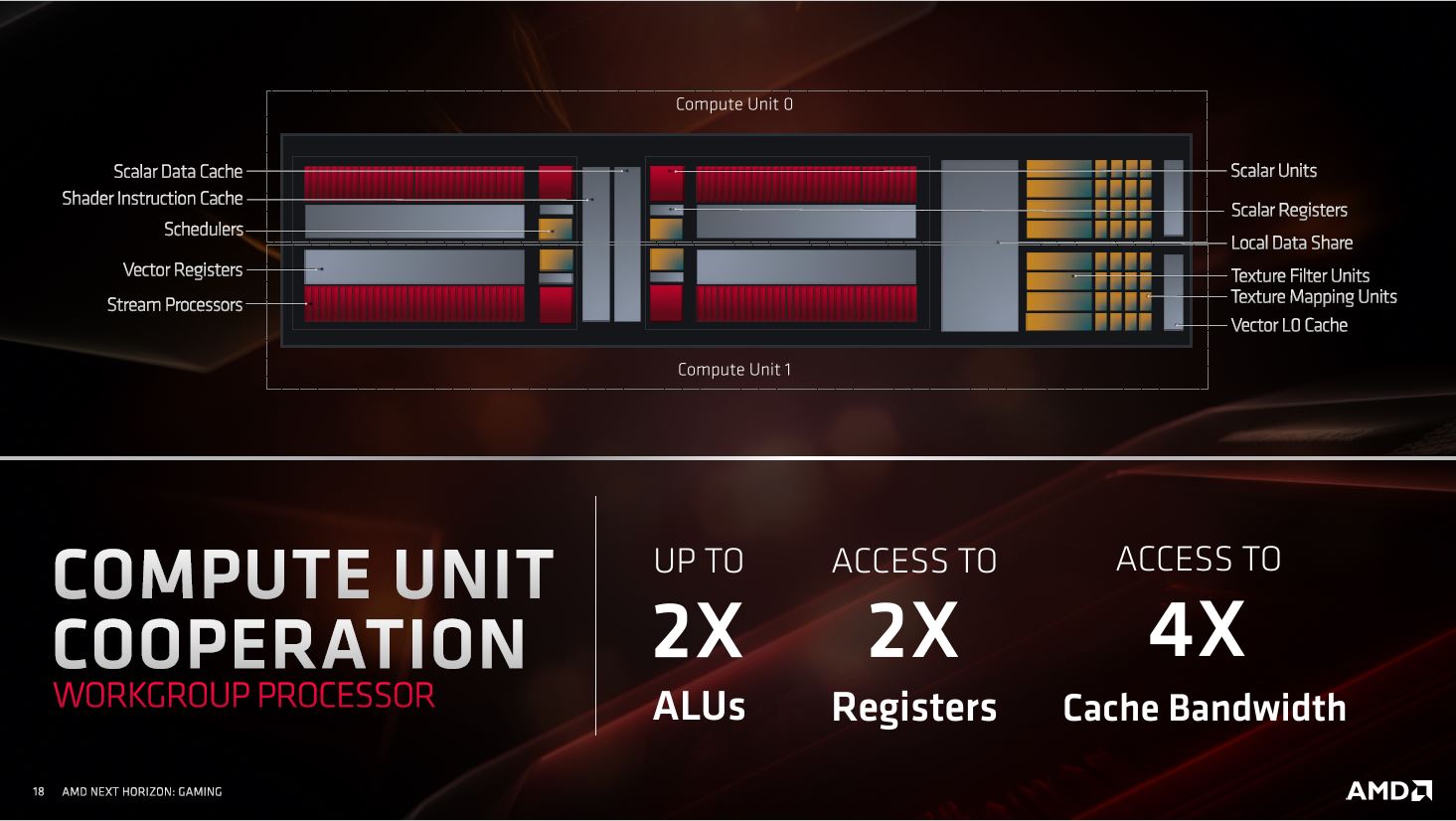
An RDNA compute unit packs 64 stream processors for vector operations and double the number of scalar units for localized serial processing. The stream processors in a CU are split into groups of two, each equipped with a scalar unit. According to AMD, this greatly reduces latency and improves the overall IPC of the compute unit. It also more efficiently utilizes local caches.


The vector execution units, or stream processors, is where much of the GPU's parallel processing happens. Due to the redesigned compute unit, two scalar processors pull two SIMD32 vector units made up of 32 stream processors, each, instead of a single scalar processor pulling four SIMD16 vector units. How is this important? On GCN, the way SIMD units are laid out, all items in a Wave64 operation get to do work once every four clocks due to hardware interleaving. With RDNA, Wave32 work items can do work every clock cycle. In all, RDNA minimizes wasted clock cycles by more efficiently and uniformly utilizing the hardware resources.




AMD examined previous generations of its graphics architecture to locate bottlenecks in the graphics pipeline. Besides increasing the number of dedicated resources, the company reworked the chip's cache hierarchy by cushioning data transfers at various stages. Each workgroup processor has dedicated 32 KB instruction and 16 KB data caches, which write back to a 128 KB L1 cache dedicated to each Graphics Engine.
These L1 caches talk to 4 MB of L2 cache. The introduction of the L1 cache and doubling in bandwidth between the various caches contributes greatly to IPC as it minimizes memory accesses, which are much slower than cache accesses. AMD is also using faster (lower latency) SRAM that reduces cache latencies by around 20 percent on die and by 8 percent at the memory level. AMD also introduced new features to the ACEs that include async-compute tunneling.

AMD summarizes the benefits of RDNA in a 25 percent IPC gain over the latest version of GCN, and an effective 50 percent performance gain for the GPU when taking into account IPC, the 7 nm process, and gains from the frequency and power management (ability to sustain boost frequencies better).


Elsewhere on the silicon, AMD updated the Display Engine and Multimedia Engine to keep up with the latest display and video standards. The Display Engine now supports DSC 1.2a (display stream compression) along with output standards HDMI 2.0 and DisplayPort 1.4 HDR to support display formats as bandwidth-intensive as 4K 240 Hz or 8K 60 Hz over a single cable, and support for 30 bits per pixel color depth. The multimedia engine supports VP9 and H.265 decoding at up to 8K 24 Hz, or 4K 90 Hz, and hardware-accelerated H.265 encoding at up to 4K 60 Hz.
Features: FidelityFX and Anti-Lag




With each new graphics architecture, gamers expect new image quality enhancement features. NVIDIA introduced DLSS, and AMD's response to that is FidelityFX, a combination of content-specific and image-specific quality enhancements. The first part of this is contrast-adaptive sharpening, which brings out details in a scene by enhancing their contrast. To work best, it requires game developers to declare which parts of the image are to be sharpened (like the HUD and on-screen texts). Details such as wear-lines on the slick tires of a race-car or hexagonal patterns on a wall come to life. We will test this feature later in a separate article.




AMD wants to improve its adoption by professional e-Sports gamers by addressing a key bottleneck with modern high-end graphics: mouse lag. This would be the amount of time taken for a click to register and a response to be rendered by the GPU. Radeon Anti-Lag is a CTR (click-to-response) enhancement that reduced mouse lag by roughly a third across various popular e-Sports titles. This setting is effectively identical to "pre-rendered" frames on NVIDIA. Modern GPUs calculate one or two frames ahead, so they can better time sending them to the monitor to avoid stuttering. Of course, this results in input lag because any input information that comes in only makes it to the screen one or two frames later.
Feb 26th, 2025 20:26 EST
change timezone
Latest GPU Drivers
New Forum Posts
- Installing Classic Zalman Flower cooler to a modern system (42)
- Share your AIDA 64 cache and memory benchmark here (3024)
- The TPU UK Clubhouse (25809)
- AM3 build, uses in 2025 (12)
- VRR Flicker when using Frame Generation (3)
- TECHPOWERUP HWBOT Contest with Cash Prizes (87)
- TPU's Nostalgic Hardware Club (20012)
- RTX5000 Series Owners Club (138)
- Help with integrated gpu. (62)
- revisiting hpet bcdedit tweaks: what are your timer bench results and settings? (102)
Popular Reviews
- Corsair Xeneon 34WQHD240-C Review - Pretty In White
- Corsair Virtuoso MAX Wireless Review
- ASUS GeForce RTX 5070 Ti TUF OC Review
- Gigabyte X870 Aorus Elite WiFi 7 Review
- MSI GeForce RTX 5070 Ti Ventus 3X OC Review
- MSI GeForce RTX 5070 Ti Vanguard SOC Review
- Montech HyperFlow Silent 360 Review
- AMD Ryzen 7 9800X3D Review - The Best Gaming Processor
- MSI GeForce RTX 5070 Ti Gaming Trio OC+ Review
- Montech TITAN PLA 1000 W Review
Controversial News Posts
- NVIDIA GeForce RTX 50 Cards Spotted with Missing ROPs, NVIDIA Confirms the Issue, Multiple Vendors Affected (496)
- AMD Radeon 9070 XT Rumored to Outpace RTX 5070 Ti by Almost 15% (304)
- AMD Plans Aggressive Price Competition with Radeon RX 9000 Series (274)
- AMD Radeon RX 9070 and 9070 XT Listed On Amazon - One Buyer Snags a Unit (247)
- NVIDIA Investigates GeForce RTX 50 Series "Blackwell" Black Screen and BSOD Issues (244)
- Edward Snowden Lashes Out at NVIDIA Over GeForce RTX 50 Pricing And Value (241)
- AMD Denies Radeon RX 9070 XT $899 USD Starting Price Point Rumors (239)
- AMD Mentions Sub-$700 Pricing for Radeon RX 9070 GPU Series, Looks Like NV Minus $50 Again (194)