Wednesday, June 17th 2020

AMD Confirms CDNA-Based Radeon Instinct MI100 Coming to HPC Workloads in 2H2020
Mark Papermaster, chief technology officer and executive vice president of Technology and Engineering at AMD, today confirmed that CDNA is on-track for release in 2H2020 for HPC computing. The confirmation was (adequately) given during Dell's EMC High-Performance Computing Online event. This confirms that AMD is looking at a busy 2nd half of the year, with both Zen 3, RDNA 2 and CDNA product lines being pushed to market.
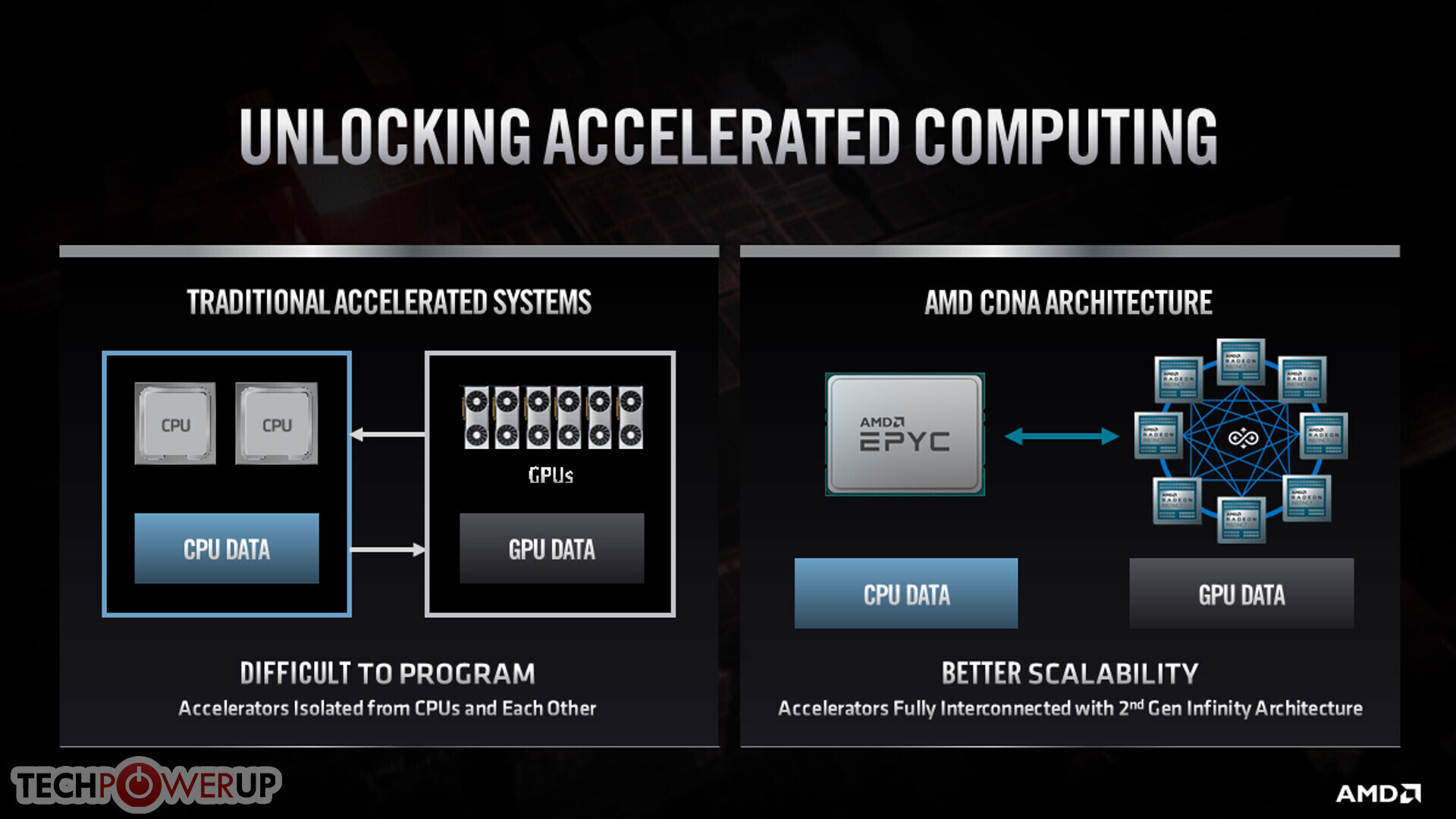
CDNA is AMD's next push into the highly-lucrative HPC market, and will see the company differentiating their GPU architectures through market-based product differentiation. CDNA will see raster graphics hardware, display and multimedia engines, and other associated components being removed from the chip design in a bid to recoup die area for both increased processing units as well as fixed-function tensor compute hardware. CNDA-based Radeon Instinct MI100 will be fabricated under TSMC's 7 nm node, and will be the first AMD architecture featuring shared memory pools between CPUs and GPUs via the 2nd gen Infinity Fabric, which should bring about both throughput and power consumption improvements to the platform.

Sources:
Hassn Mutjaba @ Twitter, via Videocardz
CDNA is AMD's next push into the highly-lucrative HPC market, and will see the company differentiating their GPU architectures through market-based product differentiation. CDNA will see raster graphics hardware, display and multimedia engines, and other associated components being removed from the chip design in a bid to recoup die area for both increased processing units as well as fixed-function tensor compute hardware. CNDA-based Radeon Instinct MI100 will be fabricated under TSMC's 7 nm node, and will be the first AMD architecture featuring shared memory pools between CPUs and GPUs via the 2nd gen Infinity Fabric, which should bring about both throughput and power consumption improvements to the platform.

13 Comments on AMD Confirms CDNA-Based Radeon Instinct MI100 Coming to HPC Workloads in 2H2020
If Arcturus MI100 turns out to be a beast, I guess developers will fight between each other who to code for it...
Specs please ?
OpenCL is pretty broken so far with ROCm. Not sure about Vulkan compute.
Hopefully they find some good use for these GPUs
AMD needs to invest more time and money into supporting ROCm (and OpenCL).
Both RDNA and GCN executes wave64 compute.
Read Amd/comments/ctfbemFigure 3 (bottom of page 5) shows 4 lines of shader instructions being executed in GCN, vs RDNA in Wave32 or “backwards compatible” Wave64.
Vega takes 12 cycles to complete the instruction on a GCN SIMD. Navi in Wave32 (optimized code) completes it in 7 cycles.
In backwards compatible (optimized for GCN Wave64) mode, Navi completes it in 8 cycles.
So even on code optimized for GCN, Navi is faster., but more performance can be extracted by optimizing for Navi.
Lower latency, and no wasted clock cycles.
GCN such as "Vega 20" supports 64bit FP.
RDNA still executes GCN instruction set with less latency.