Dr. Lisa Su Responds to TinyBox's Radeon RX 7900 XTX GPU Firmware Problems
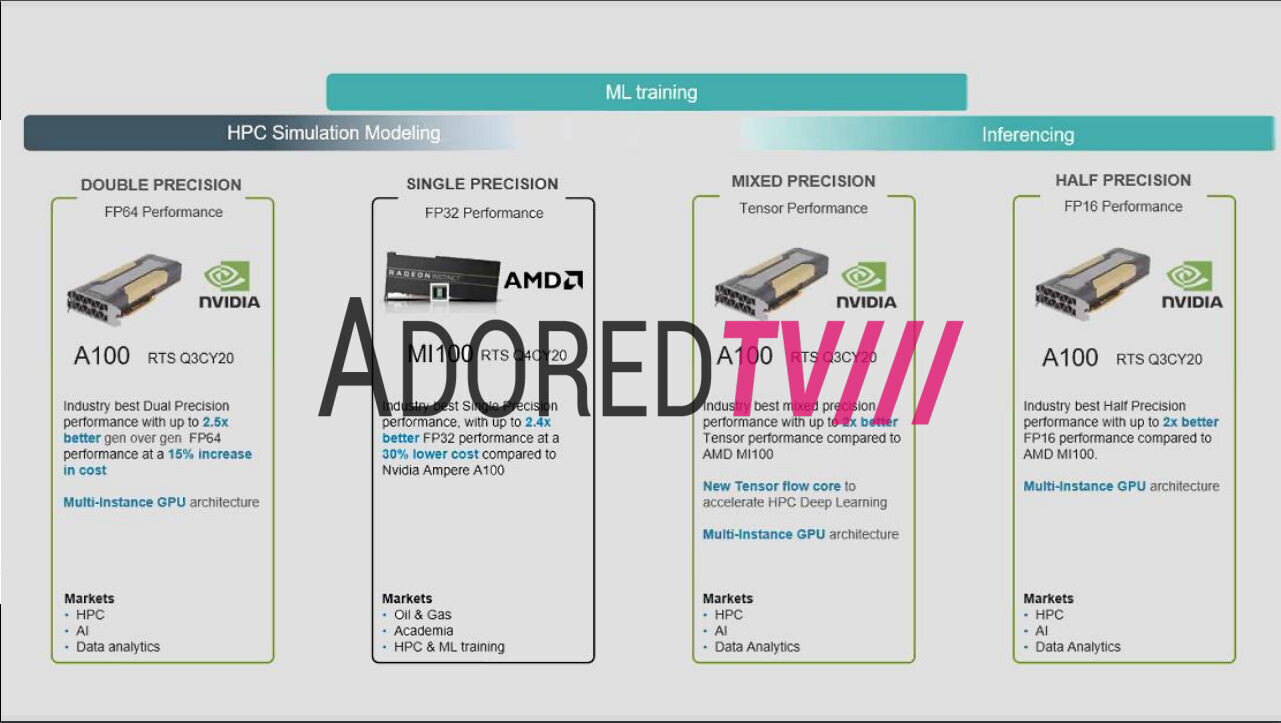
The TinyBox AI server system attracted plenty of media attention last week—its creator, George Hotz, decided to build with AMD RDNA 3.0 GPU hardware rather than the expected/traditional choice of CDNA 3.0. Tiny Corp. is a startup firm dealing in neural network frameworks—they currently "write and maintain tinygrad." Hotz & Co. are in the process of assembling rack-mounted 12U TinyBox systems for customers—an individual server houses an AMD EPYC 7532 processor and six XFX Speedster MERC310 Radeon RX 7900 XTX graphics cards. The Tiny Corp. social media account has engaged in numerous NVIDIA vs. AMD AI hardware debates/tirades—Hotz appears to favor the latter, as evidenced in his latest choice of components. ROCm support on Team Red AI Instinct accelerators is fairly mature at this point in time, but a much newer prospect on gaming-oriented graphics cards.
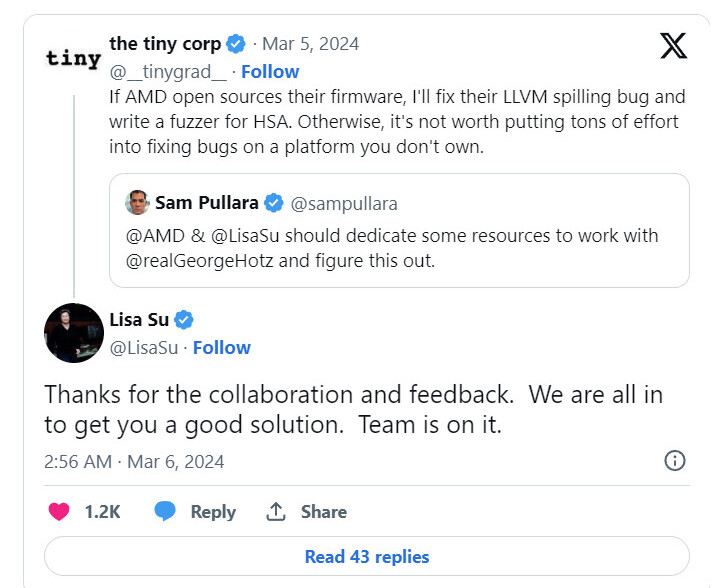
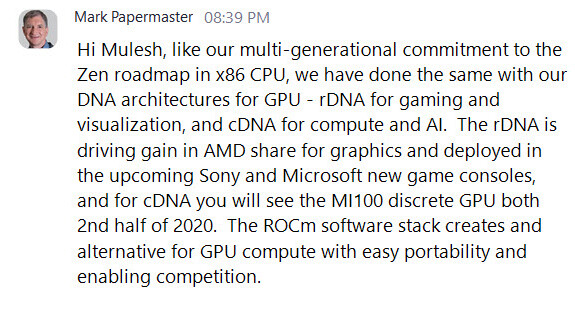
Tiny Corporation's unusual leveraging of Radeon RX 7900 XTX GPUs in a data center configuration has already hit a developmental roadblock. Yesterday, the company's social media account expressed driver-related frustrations in a public forum: "If AMD open sources their firmware, I'll fix their LLVM spilling bug and write a fuzzer for HSA. Otherwise, it's not worth putting tons of effort into fixing bugs on a platform you don't own." Hotz's latest complaint was taken onboard by AMD's top brass—Dr. Lisa Su responded with the following message: "Thanks for the collaboration and feedback. We are all in to get you a good solution. Team is on it." Her software engineers—within a few hours—managed to fling out a set of fixes in Tiny Corporation's direction. Hotz appreciated the quick turnaround, and proceeded to run a model without encountering major stability issues: "AMD sent me an updated set of firmware blobs to try. They are responsive, and there have been big strides in the driver in the last year. It will be good! This training run is almost 5 hours in, hasn't crashed yet." Tiny Corp. drummed up speculation about AMD open sourcing GPU MES firmware—Hotz disclosed that he will be talking (on the phone) to Team Red leadership.



Tiny Corporation's unusual leveraging of Radeon RX 7900 XTX GPUs in a data center configuration has already hit a developmental roadblock. Yesterday, the company's social media account expressed driver-related frustrations in a public forum: "If AMD open sources their firmware, I'll fix their LLVM spilling bug and write a fuzzer for HSA. Otherwise, it's not worth putting tons of effort into fixing bugs on a platform you don't own." Hotz's latest complaint was taken onboard by AMD's top brass—Dr. Lisa Su responded with the following message: "Thanks for the collaboration and feedback. We are all in to get you a good solution. Team is on it." Her software engineers—within a few hours—managed to fling out a set of fixes in Tiny Corporation's direction. Hotz appreciated the quick turnaround, and proceeded to run a model without encountering major stability issues: "AMD sent me an updated set of firmware blobs to try. They are responsive, and there have been big strides in the driver in the last year. It will be good! This training run is almost 5 hours in, hasn't crashed yet." Tiny Corp. drummed up speculation about AMD open sourcing GPU MES firmware—Hotz disclosed that he will be talking (on the phone) to Team Red leadership.