Wednesday, July 13th 2022
CXL Memory Pooling will Save Millions in DRAM Cost
Hyperscalers such as Microsoft, Google, Amazon, etc., all run their cloud divisions with a specific goal. To provide their hardware to someone else in a form called instance and have the user pay for it by the hour. However, instances are usually bound by a specific CPU and memory configuration, which you can not configure yourself. But instead, you can only choose from the few available options that are listed. For example, when selecting one virtual CPU core, you get two GB of RAM and can go as high as you want with CPU cores. However, the available RAM will also double, even though you might not need it. When renting an instance, the allocated CPU cores and memory are yours until the instance is turned off.
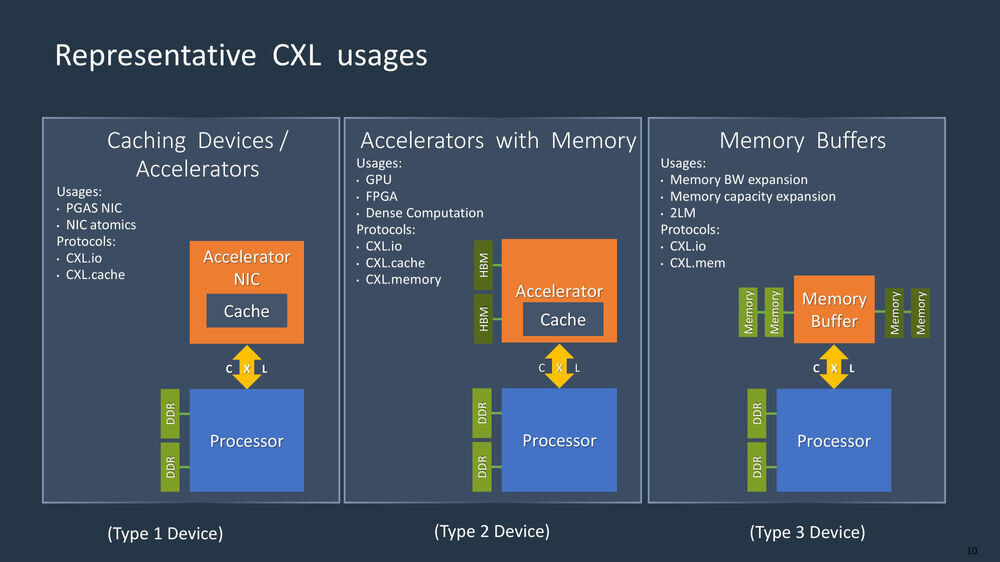
And it is precisely this that hyperscalers are dealing with. Many instances don't fully utilize their DRAM, making the whole data center usage inefficient. Microsoft Azure, one of the largest cloud providers, measured that 50% of all VMs never touch 50% of their rented memory. This makes memory stranded in a rented VM, making it unusable for anything else. To achieve better results, we have to turn to mainframe designs and copy their behavior. The memory pooling concept is designed to allow the CPU to access as much memory as it needs without occupying and stranding DRAM in VMs that don't need it. Backing this up is the new CXL protocol for cache coherency, which every major hardware provider is including in their offering. Having a data center with CXL hardware allows companies like Microsoft to reduce costs. As the company notes, "[memory] disaggregation can achieve a 9 - 10% reduction in overall DRAM, which represents hundreds of millions of dollars in cost savings for a large cloud provider."
To achieve better results, we have to turn to mainframe designs and copy their behavior. The memory pooling concept is designed to allow the CPU to access as much memory as it needs without occupying and stranding DRAM in VMs that don't need it. Backing this up is the new CXL protocol for cache coherency, which every major hardware provider is including in their offering. Having a data center with CXL hardware allows companies like Microsoft to reduce costs. As the company notes, "[memory] disaggregation can achieve a 9 - 10% reduction in overall DRAM, which represents hundreds of millions of dollars in cost savings for a large cloud provider." Microsoft estimates that the use of CXL and memory pooling will cut data center costs by 4-5% server costs. This is a significant number, as DRAM alone consumes more than 50% of server costs.
Microsoft estimates that the use of CXL and memory pooling will cut data center costs by 4-5% server costs. This is a significant number, as DRAM alone consumes more than 50% of server costs.
As the performance is concerned, the Azure team benchmarked a few configurations that use local DRAM and pooled DRAM to achieve the best results. The performance penalty for using pooled memory depended on the application. However, we know that accessing pooled memory required an additional 67-87 ns (nanoseconds) latency. This is quite a significant performance hit, resulting in a slowdown of a few applications. About 20% of applications receive no perfromance hit from pooled memory; 23% of applications receive less than 5% slowdown; 25% experience more than 20% slowdown; while 12% experienced more than 30% downshift. Performance figures can be seen below.
 According to Microsoft, this is only the first generation testing conducted on the first wave of CXL hardware. Results are promising as they reduce cloud costs for the hyperscaler. With the next-generation hardware and CXL protocol specifications, we could experience much better behavior. For more information, please refer to the paper that examines this in greater detail.
According to Microsoft, this is only the first generation testing conducted on the first wave of CXL hardware. Results are promising as they reduce cloud costs for the hyperscaler. With the next-generation hardware and CXL protocol specifications, we could experience much better behavior. For more information, please refer to the paper that examines this in greater detail.
Source:
SemiAnalysis
And it is precisely this that hyperscalers are dealing with. Many instances don't fully utilize their DRAM, making the whole data center usage inefficient. Microsoft Azure, one of the largest cloud providers, measured that 50% of all VMs never touch 50% of their rented memory. This makes memory stranded in a rented VM, making it unusable for anything else.
At Azure, we find that a major contributor to DRAM inefficiency is platform-level memory stranding. Memory stranding occurs when a server's cores are fully rented to virtual machines (VMs), but unrented memory remains. With the cores exhausted, the remaining memory is unrentable on its own, and is thus stranded. Surprisingly, we find that up to 25% of DRAM may become stranded at any given moment.

As the performance is concerned, the Azure team benchmarked a few configurations that use local DRAM and pooled DRAM to achieve the best results. The performance penalty for using pooled memory depended on the application. However, we know that accessing pooled memory required an additional 67-87 ns (nanoseconds) latency. This is quite a significant performance hit, resulting in a slowdown of a few applications. About 20% of applications receive no perfromance hit from pooled memory; 23% of applications receive less than 5% slowdown; 25% experience more than 20% slowdown; while 12% experienced more than 30% downshift. Performance figures can be seen below.


24 Comments on CXL Memory Pooling will Save Millions in DRAM Cost
Capitalism 101 at it's finest, and megacorps getting stronger/moar powerful and the rich getting richer by the minute, at the sole expense of everyone else ..:eek:..:fear:..:cry:
Back in 1980s, semiconductor device manufacturing are the crown jewel. Then WWW. Then smartphones and UGCs. Then AIs. You can't just restore the glory of an industry that is already behind its days. Just as you can't split a dam into two and let two hydroplant to "compete". It's simply stupid.
Its great because you can flexibly use RAM around to maxmise their usage however it can lead to situations where things wont run because the RAM assigned is below what is required to start the process and also if the oversubscribe the node and then those instances DO decide to heavily use their RAM? THe node falls over due to it trying to use more RAM than what it has.
So great for 95% of use cases. Fucks over that other 5%.
Anyway, are modern Windows and Linux OSes, running as VM guests, capable of using RAM that's variable in size instead of fixed?
Also it can cause issues for places that want to skimp and save now that then run out of capacity far sooner than intended due to unforseen growth/demand.