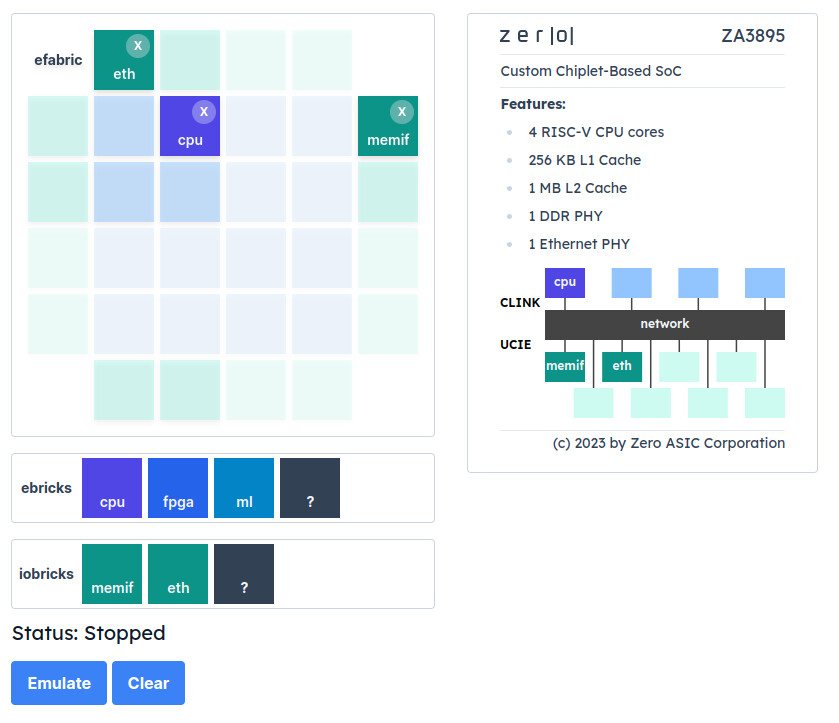
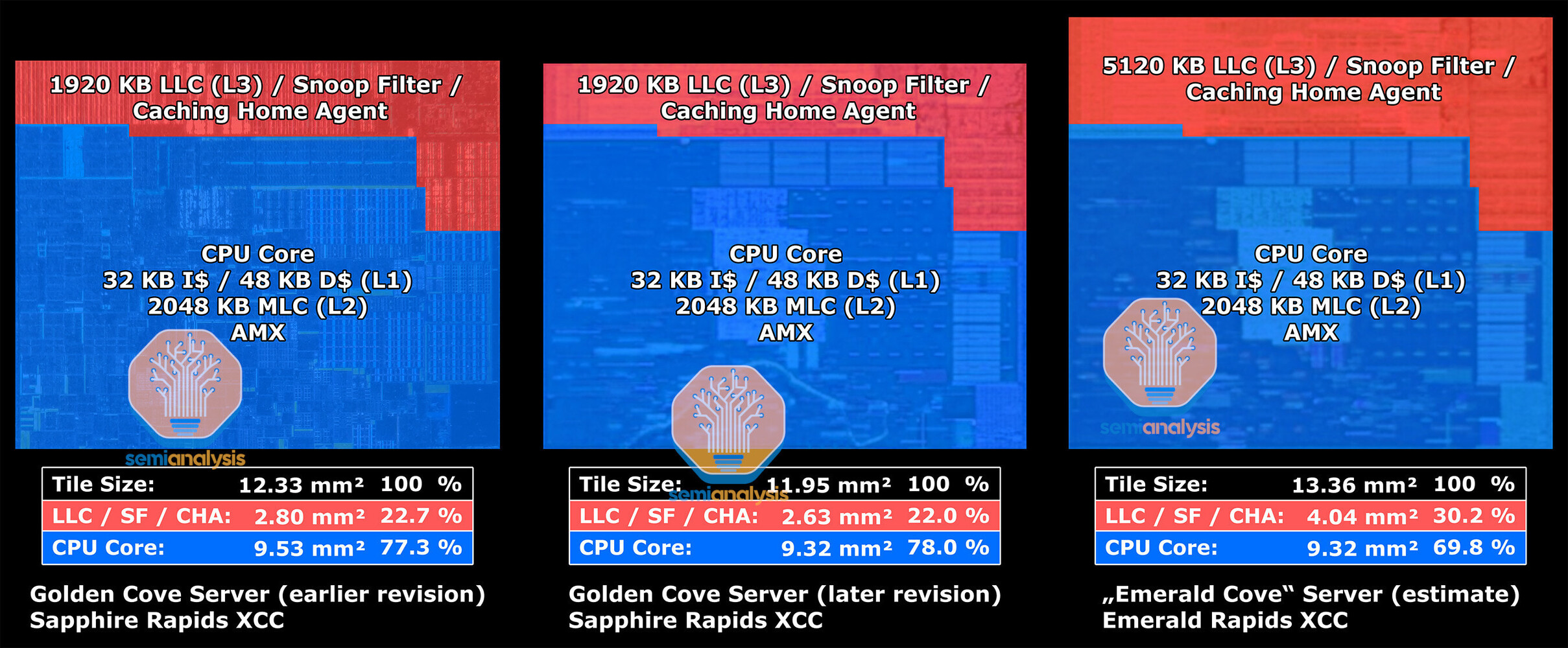
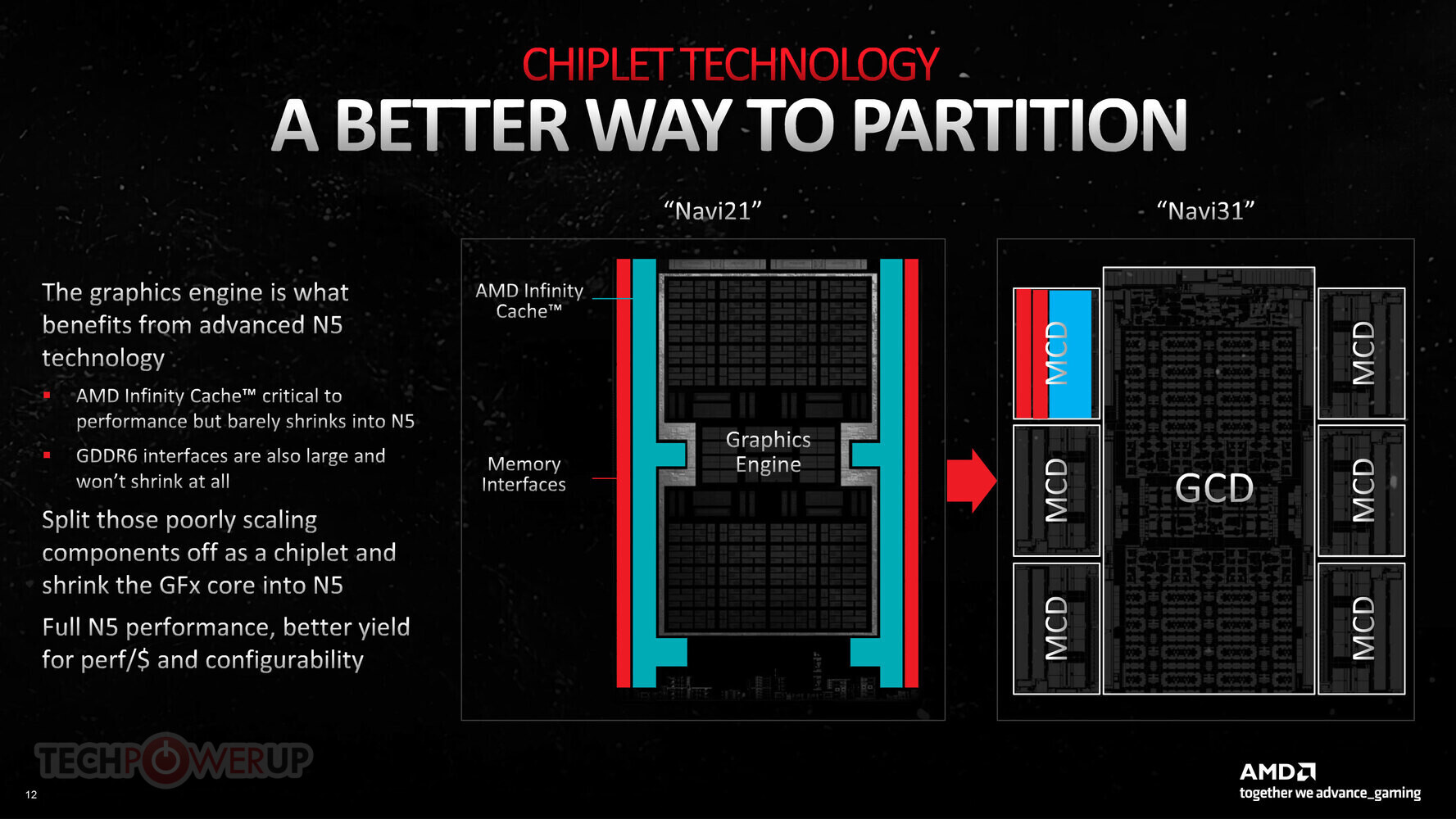
Intel Lunar Lake Chiplet Arrangement Sees Fewer Tiles—Compute and SoC
Intel Core Ultra "Lunar Lake-MX" will be the company's bulwark against Apple's M-series Pro and Max chips, designed to power the next crop of performance ultraportables. The MX codename extension denotes MoP (memory-on-package), which sees stacked LPDDR5X memory chips share the package's fiberglass substrate with the chip, to conserve PCB footprint, and give Intel greater control over the right kind of memory speed, timings, and power-management features suited to its microarchitecture. This is essentially what Apple does with its M-series SoCs powering its MacBooks and iPad Pros. Igor's Lab scored the motherlode on the way Intel has restructured the various components across its chiplets, and the various I/O wired to the package.
When compared to "Meteor Lake," the "Lunar Lake" microarchitecture sees a small amount of "re-aggregation" of the various logic-heavy components of the processor. On "Meteor Lake," the CPU cores and the iGPU sat on separate tiles—Compute tile and Graphics tile, respectively, with a large SoC tile sitting between them, and a smaller I/O tile that serves as an extension of the SoC tile. All four tiles sat on top of a Foveros base tile, which is essentially an interposer—a silicon die that facilitates high-density microscopic wiring between the various tiles that are placed on top of it. With "Lunar Lake," there are only two tiles—the Compute tile, and the SoC tile.

When compared to "Meteor Lake," the "Lunar Lake" microarchitecture sees a small amount of "re-aggregation" of the various logic-heavy components of the processor. On "Meteor Lake," the CPU cores and the iGPU sat on separate tiles—Compute tile and Graphics tile, respectively, with a large SoC tile sitting between them, and a smaller I/O tile that serves as an extension of the SoC tile. All four tiles sat on top of a Foveros base tile, which is essentially an interposer—a silicon die that facilitates high-density microscopic wiring between the various tiles that are placed on top of it. With "Lunar Lake," there are only two tiles—the Compute tile, and the SoC tile.