SK hynix Strengthens AI Memory Leadership & Partnership With Host at the TSMC 2024 Tech Symposium
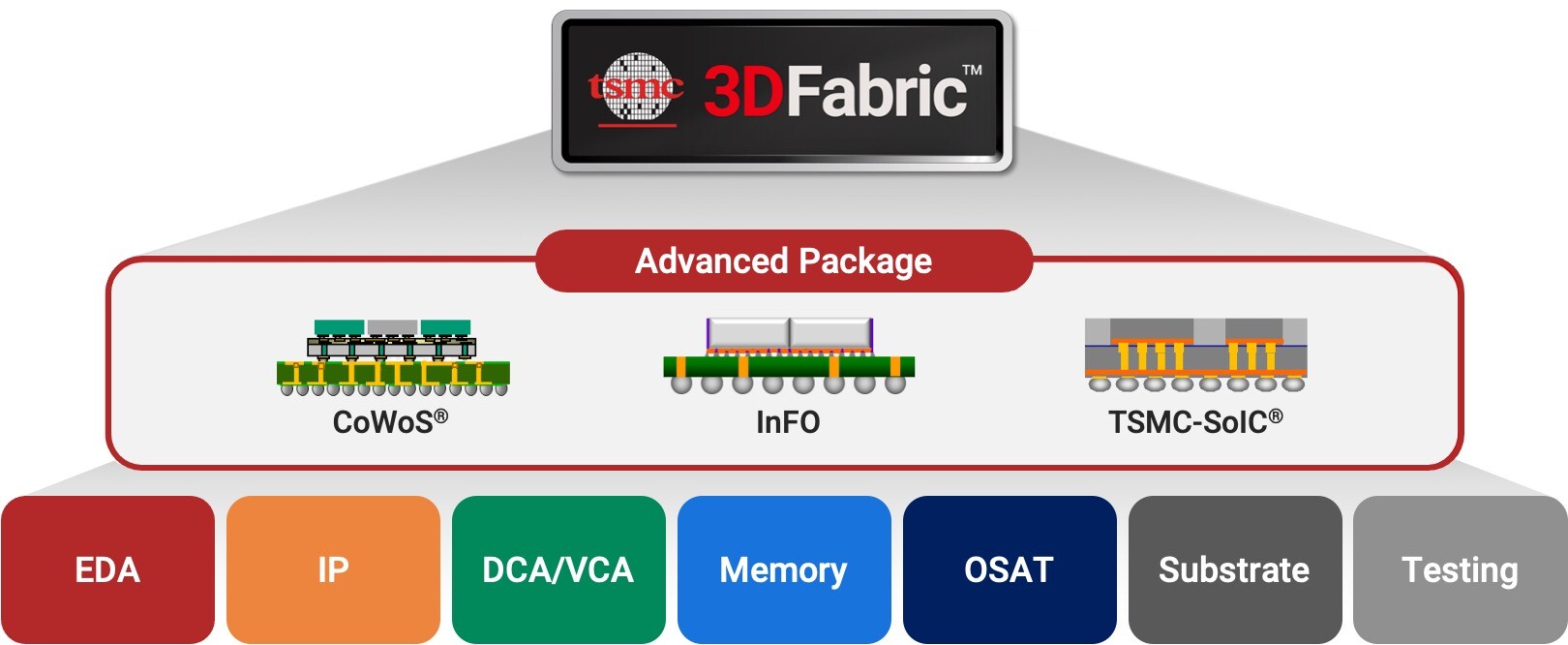
SK hynix showcased its next-generation technologies and strengthened key partnerships at the TSMC 2024 Technology Symposium held in Santa Clara, California on April 24. At the event, the company displayed its industry-leading HBM AI memory solutions and highlighted its collaboration with TSMC involving the host's CoWoS advanced packaging technology.
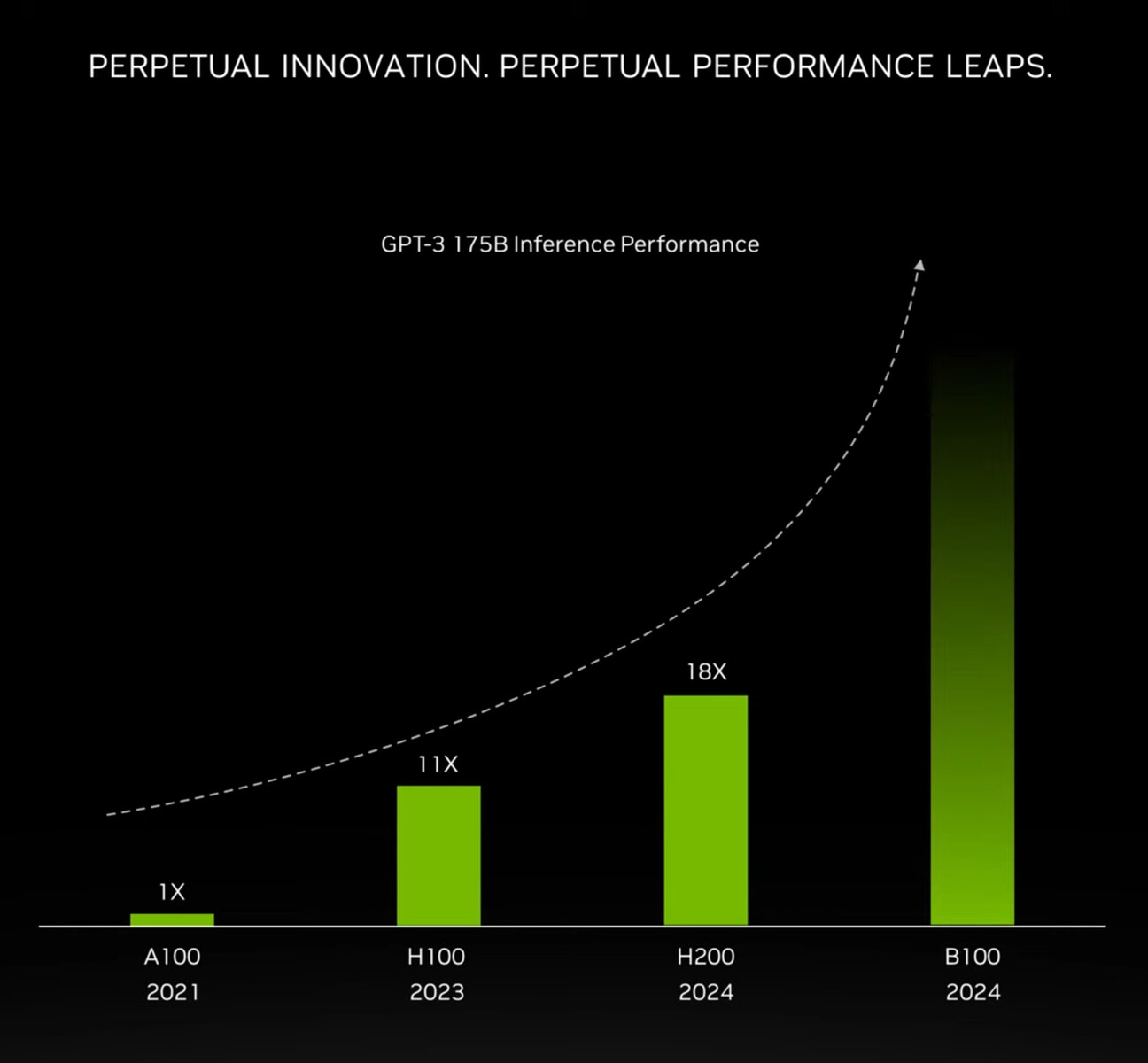
TSMC, a global semiconductor foundry, invites its major partners to this annual conference in the first half of each year so they can share their new products and technologies. Attending the event under the slogan "Memory, the Power of AI," SK hynix received significant attention for presenting the industry's most powerful AI memory solution, HBM3E. The product has recently demonstrated industry-leading performance, achieving input/output (I/O) transfer speed of up to 10 gigabits per second (Gbps) in an AI system during a performance validation evaluation.



TSMC, a global semiconductor foundry, invites its major partners to this annual conference in the first half of each year so they can share their new products and technologies. Attending the event under the slogan "Memory, the Power of AI," SK hynix received significant attention for presenting the industry's most powerful AI memory solution, HBM3E. The product has recently demonstrated industry-leading performance, achieving input/output (I/O) transfer speed of up to 10 gigabits per second (Gbps) in an AI system during a performance validation evaluation.