Phison Debuts the X1 to Provide the Industry's Most Advanced Enterprise SSD Solution
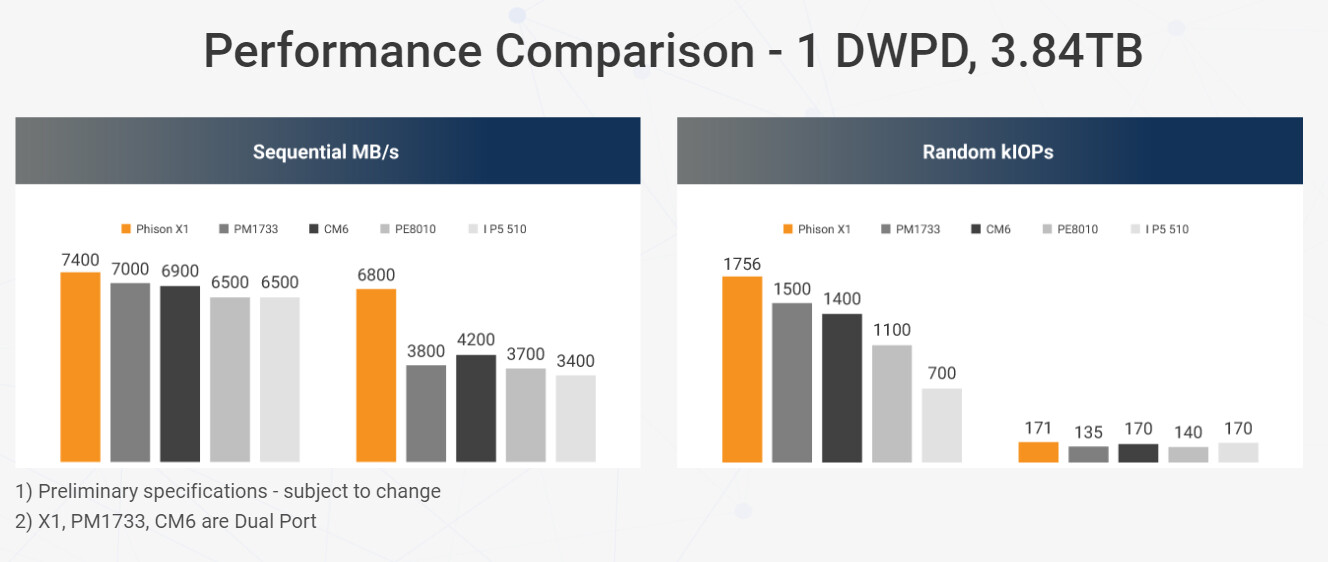
Phison Electronics Corp., a global leader in NAND flash controller and storage solutions, today announced the launch of its X1 controller based solid state drive (SSD) platform that delivers the industry's most advanced enterprise SSD solution. Engineered with Phison's technology to meet the evolving demands of faster and smarter global data-center infrastructures, the X1 SSD platform was designed in partnership with Seagate Technology Holdings plc, a world leader in mass-data storage infrastructure solutions. The X1 SSD customizable platform offers more computing with less energy consumption. With a cost-effective solution that eliminates bottlenecks and improves quality of service, the X1 offers more than a 30 percent increase in data reads than existing market competitors for the same power used.
"We combined Seagate's proprietary data management and customer integration capabilities with Phison's cutting-edge technology to create highly customized SSDs that meet the ever-evolving needs of the enterprise storage market," said Sai Varanasi, senior vice president of product and business marketing at Seagate Technology. "Seagate is excited to partner with Phison on developing advanced SSD technology to provide the industry with increased density, higher performance and power efficiency for all mass capacity storage providers."

"We combined Seagate's proprietary data management and customer integration capabilities with Phison's cutting-edge technology to create highly customized SSDs that meet the ever-evolving needs of the enterprise storage market," said Sai Varanasi, senior vice president of product and business marketing at Seagate Technology. "Seagate is excited to partner with Phison on developing advanced SSD technology to provide the industry with increased density, higher performance and power efficiency for all mass capacity storage providers."