Marvell and AWS Collaborate to Enable Cloud-First Silicon Design
Marvell Technology, Inc., a leader in data infrastructure semiconductor solutions, announced today that it has selected Amazon Web Services, Inc. (AWS) as its cloud provider for electronic design automation (EDA). A cloud-first approach helps Marvell to rapidly and securely scale its service on the world's leading cloud, rise to the challenges brought by increasingly complex chip design processes, and deliver continuous innovation for the expanding needs across the automotive, carrier, data center, and enterprise infrastructure markets it serves. The work extends the longstanding relationship between the two companies—Marvell is also a key semiconductor supplier for AWS, helping the company support the design and rapid delivery of cloud services that best meet customers' demanding requirements.
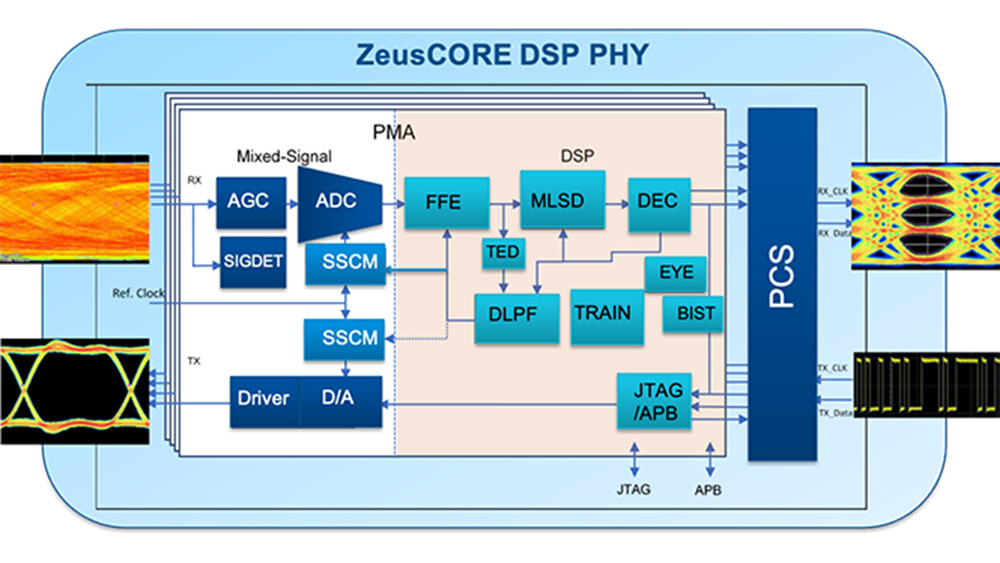
EDA refers to the specialized and compute-intensive processes used in chip making and is a critical piece of Marvell's R&D. Over the years, the number of transistors on an integrated chip has increased exponentially. Each advance in chip design calls for a calculated application of software modules overseeing logic design, debugging, component placement, wire routing, optimization of time and power consumption, and verification. Due to the computationally intensive nature of EDA workloads, it is no longer cost-effective or timely to run EDA on premises. By powering its EDA with AWS, Marvell leverages an unmatched portfolio of services including secure, elastic, high-performance compute capacity in the cloud to solve challenges around speed, latency, security of IP, and data transfer.
EDA refers to the specialized and compute-intensive processes used in chip making and is a critical piece of Marvell's R&D. Over the years, the number of transistors on an integrated chip has increased exponentially. Each advance in chip design calls for a calculated application of software modules overseeing logic design, debugging, component placement, wire routing, optimization of time and power consumption, and verification. Due to the computationally intensive nature of EDA workloads, it is no longer cost-effective or timely to run EDA on premises. By powering its EDA with AWS, Marvell leverages an unmatched portfolio of services including secure, elastic, high-performance compute capacity in the cloud to solve challenges around speed, latency, security of IP, and data transfer.