New Specs of AMD RDNA3 GPUs Emerge
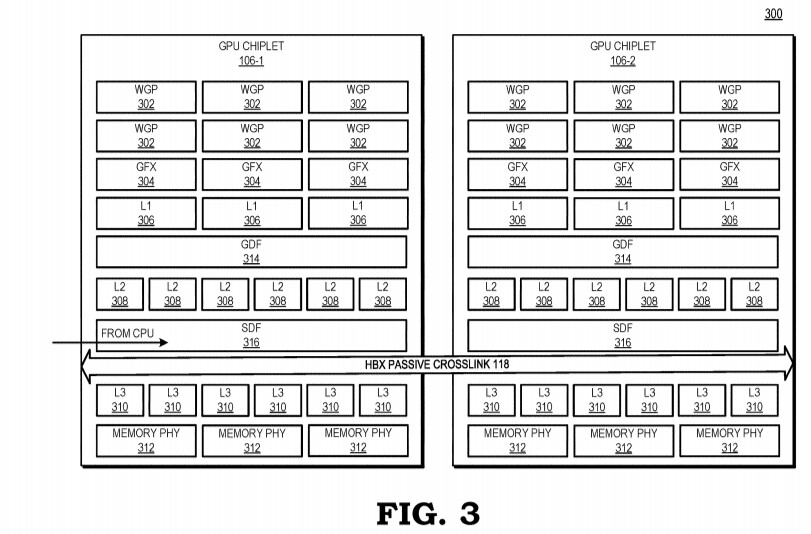
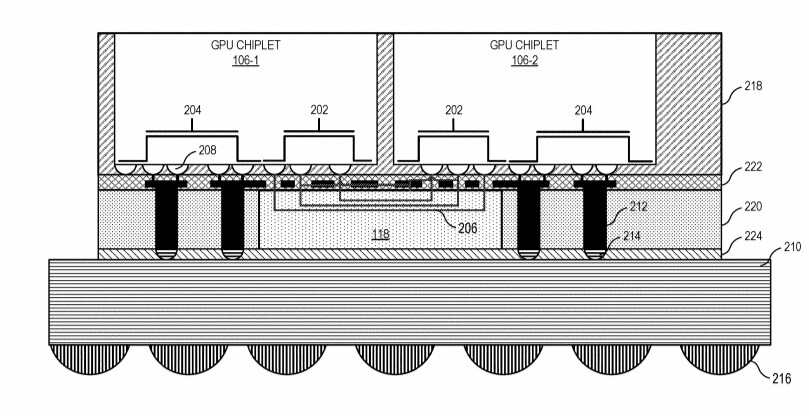
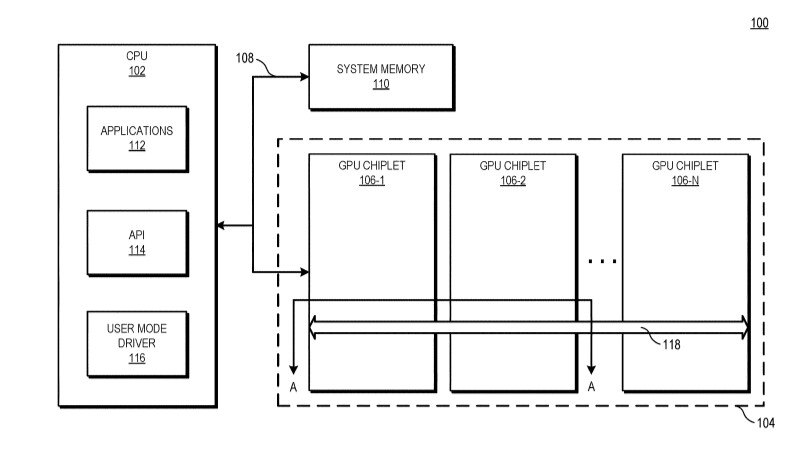
A new list of specifications of AMD's next-generation "Navi 3x" GPUs based on the RDNA3 graphics architecture emerged, with lower CU counts than previously reported. It turns out that the large "Navi 31" GPU comes with 12,288 stream processors across 48 WGP (workgroup processors), 12 SA (shader arrays), and 6 SE (shader engines). This still amounts to a 140% increase in stream processors over the Navi 21. This chip will power SKUs that succeed the Radeon RX 6800-series and RX 6900-series.
The second largest silicon from the series is the Navi 32, with two-thirds the number-crunching machinery of the Navi 31. That's 8,192 stream processors across 32 WGPs, 8 SAs, and 4 SEs. The Navi 32 silicon powers successors of the RX 6700-series. The third largest chip is the Navi 33, with half the muscle of the Navi 32, and one-third that of the Navi 31. This means 4,096 stream processors spread across 16 WGP, 4 SA, and 2 SE. There's no word on other specs such as memory bus width, but we've heard rumors of AMD doubling down on the Infinity Cache memory technology, by giving these chips even larger on-die caches. RDNA3 is also expected to improve ray tracing performance, as more of the ray tracing pipeline is handled by fixed-function hardware.
The second largest silicon from the series is the Navi 32, with two-thirds the number-crunching machinery of the Navi 31. That's 8,192 stream processors across 32 WGPs, 8 SAs, and 4 SEs. The Navi 32 silicon powers successors of the RX 6700-series. The third largest chip is the Navi 33, with half the muscle of the Navi 32, and one-third that of the Navi 31. This means 4,096 stream processors spread across 16 WGP, 4 SA, and 2 SE. There's no word on other specs such as memory bus width, but we've heard rumors of AMD doubling down on the Infinity Cache memory technology, by giving these chips even larger on-die caches. RDNA3 is also expected to improve ray tracing performance, as more of the ray tracing pipeline is handled by fixed-function hardware.