Thursday, July 14th 2011

FX-Series Processors Clock Speeds 'Revealed'
On several earlier articles like this one, we were versed with the model numbers and even possible prices of AMD's next-generation FX series desktop processors, but the clock speeds stayed under the wraps, that's until a table listing them out was leaked. AMD's FX-series consists of eight-core FX-81xx parts, six-core FX-61xx, and quad-core FX-41xx parts, probably harvested out of the Zambezi silicon by disabling modules (groups of two cores closely interconnected with some shared resources). Most, if not all, FX series chips have unlocked multipliers, making it a breeze to overclock them. All chips come in the AM3+ package, feature 8 MB of L3 cache, and 2 MB L2 cache per module.
Leading the pack is FX-8150, with a clock speed of 3.6 GHz, and TurboCore speed of 4.2 GHz, a 500 MHz boost. The next chip, FX-8120, has a boost of close to a GHz, it has a clock speed of 3.1 GHz, that goes all the way up to 4 GHz with TurboCore. This will be available in 125W and 95W TDP variants. Next up is the FX-8100, with 2.8 GHz clock speed, that goes up to 3.7 GHz, another 900 MHz boost. The scene shifts to 6-core chips, with FX-6120, no clock speed numbers were given out for this one. FX-6100, on the other hand, is clocked at 3.3 GHz, with 3.9 GHz Turbo. The FX-4100 is the only quad-core part with clock speeds given out by this source: 3.6 GHz, with a tiny 200 MHz boost to 3.8 GHz. You can see that there is no pattern in the turbo speed amounts specific to models, and hence we ask you to take these with a pinch of salt.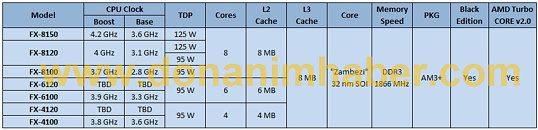
Source:
DonanimHaber
Leading the pack is FX-8150, with a clock speed of 3.6 GHz, and TurboCore speed of 4.2 GHz, a 500 MHz boost. The next chip, FX-8120, has a boost of close to a GHz, it has a clock speed of 3.1 GHz, that goes all the way up to 4 GHz with TurboCore. This will be available in 125W and 95W TDP variants. Next up is the FX-8100, with 2.8 GHz clock speed, that goes up to 3.7 GHz, another 900 MHz boost. The scene shifts to 6-core chips, with FX-6120, no clock speed numbers were given out for this one. FX-6100, on the other hand, is clocked at 3.3 GHz, with 3.9 GHz Turbo. The FX-4100 is the only quad-core part with clock speeds given out by this source: 3.6 GHz, with a tiny 200 MHz boost to 3.8 GHz. You can see that there is no pattern in the turbo speed amounts specific to models, and hence we ask you to take these with a pinch of salt.

412 Comments on FX-Series Processors Clock Speeds 'Revealed'
The Windows OS will schedule the threads not the software or the cpu
If it a 4 core app you will see any 2 modules being used
If it is a 3 core app you will see any 1 module being used + any 1 half-utilized module
In a 4 threaded application.
1 core in a module has access to 100% of the resources
2 cores in a module has access to 100% of the resources
The idea of CMT is to make 2 cores use the same resources to increase throughput/speed
1 module provides 2x the resources 1 core needs
4 cores being used in any pattern or setup will have 100% access to all the resources it needs
Simply put you do not need to worry about the module as a whole
Everything that needs to be dedicated is dedicated and everything that needs to be shared is shared
There is 800% resources
1 core can only access 100% of those resources
It is a hardware limitation
2 cores will use 200% of those
So, 1 core will completely use the stuff dedicated to it and only half the stuff shared with it there is only so much 1 core can do
The floating point is a dedicated entity shared between both cores, so it does not follow what we think of a normal FPU
That is why it is call a Flex FPU
1 core in a module has access to 100% of the resources in 1 module
2 cores in a module has access to 200% of the resources in 1 module
Module holds all the resources needed for 2 cores to run in it
There is no performance hit in this design
Performance to Resources used
100% -> 200% -> 300% -> 400% -> 500% -> 600% -> 700% -> 800%
{50% -> 100%} -> {150% -> 200%} -> {250% -> 300%} -> {350% -> All}
with 4 cores used in any module will utilize half of the CPUs total resources
with 2 cores used in any module will utiilize 1/4 of the CPUs total resources
with 6 """"" 3/4 of the CPUs total resources
with 8 """"" All of the the CPUs total resources
Module holds 100% of the stuff needed for 1 core and 2 cores to operate without a bottleneck
---and now for something totally different--------
What he does^
And eyefinity setups prove absolutely nothing. Gaming is an absolutely terrible metric to judge cpu performance.
Sorry, but I would happily bet money that Intel still wins IPC per core per clock.
So now I'm back to hoping that they can figure out a way to make 4 threads run on 4 modules.
256bit commands are done at the module level not the core level
(Meaning AVX support is the same as Intel's AVX for compatibility)
SSE5 is where it is at for AMD(XOP, CVT16, FMA4)
SSE is done at the core level(8xSSE)(SSE5 128bit)
AVX is done at the module level(4xAVX)(AVX 128bit+AVX 128bit)
Sorry, but I would bet money that AMD and Intel have equal IPC per core per clockHe isn't talking about what I am talking about
It's harder to explain once you go from the throughput world to the speed world
There is no overhead....that is the issue
The core CMP issue is there but isn't really bad
CMT scales on the module level not the core level
200% -> 397.5% -> 595% -> 792.5%
vs CMP
100% -> 197.5% -> 295% -> 392.5% -> 490% -> 587.5% -> 685% -> 782.5%
Do you see the trade off?
AVX done on both cores or done half-length
128bit AVX+128bit AVX
2x128bit AVX
You not understanding this is lousy tiddingsBack to you
4 core Orochi vs 4 core Phenom II
Both score 4000~
But in multithreading there is an overhead but the Orochi design alleviates that to the module level and not to the core level
4 core Orochi will get a real world score of 15000~ where in an no-overhead world it will get 16k
4 core Phenom II will get a real world score of 14000~ where in an no-overhead world it will get 16k
The distance gets even bigger with more cores
8 core Orochi vs 8 core Phenom II
4000 again
8 core Orochi will get a real world score of 30000 where in a no overhead world it will get 32K
8 core Phenom II will get a real world score of 28000 where in no overhead world it will get 32k
But that is at the same clocks and for the same IPC
Phenom II has 3 IPC per core while Zambezi has 4 IPC per core(this is where the 25% comes in)
and Zambezi will have a higher clock
Same clocks though
Phenom II 3.4GHz
4200
Zambezi ignoring all the extra stuff that increases a little bit
5000~(I'm going to say it will get 5000ish(±400)
Phenom II 8C - 29400
Zambezi 8C - 34500
But that is if it is well programmed
Is this real enough?
128bit Execution per Core
256bit Execution per Module
128-bit - 32 FLOPS
256-bit - 64 FLOPS
wait what?
Intel doesn't have FMACs
1x128bit
or
1x256bit
per core
AMD has FMACs
1x128bit
per core
1x256bit
per module
The best I can come up with
Anyway, FMAC has nothing to do with that. FMAC is the way the math is done. AMD used 2x128 bit FMAC units. Which means 2 fused mulply accumulate units.
Intel used 1x 256 bit FMUL and 1x 256 bit FADD. The result is similar.
The difference is that BD can use 1x 128 bit for each "core", which may or might not be an advantage for legacy code that is heavily parallelized (8 threads). In the server arena this might be a real advantage, in desktop, it will help nothing most probably (8 threads required).
What AMD doesn't say either is that the 128+128 = 256 bit operation is slower than the "native" 256 bit operation, so slower for AVX, there is overhead. Pretending there is not, is just like believing in fairies.
Or just like believing that GlobalFoundries or not, the yields are the same for an old architecture and a new architecture. :rolleyes:
I do plan on picking up one of these processors, of course after they are actually out and I've read a couple of reviews.
Should I worry about all the info that is being thrown around here?
We just like to talk about and predict performance based on our knowledge of the architecture and the different tech utilized.
The yields are better
Because they have been producing AMD Zambezi chips since
Late August 2010(8 weeks after Bulldozer was taped out)
Late August 2010 -Late October 2010 = A1
November 2010 - January 2011 = B0
February 2011- April 2011 = B1
May 2011 - July 2011 = B2
^That span of time I am pretty sure they don't have yield issues
Since, the desktop market likes the legacy benchies it will do greatNo, you shouldn't we are bickering about stuff you won't have to worry aboutBasically
not once have i seen it be your imho:wtf:, no your waffling like its a fact, and no sprd sheets please or screanies , ive seen em all and been following it as long as everyone else on TPU:D
legacy apps == poor multi-threading == don't dream of 4 threads being fully utilized, let alone 8 == 128+128 bit advantage goes down the drain.
And when major developers start using AVX in 1-2 years tops, BD will have the disadvantage. "Only" 6% if you will (I want proof btw), still a big one considering that the die size increases too.
You need to read thisAnd those issues weren't yield bentI am mainly talking about Cinebench, wPrime, and those other benchies
The Floating Point Unit needs the cores
:roll:
Oh me....forgetting about that single fact