Tuesday, May 21st 2019

AMD "Navi" Features 8 Streaming Engines, Possible ROP Count Doubling?
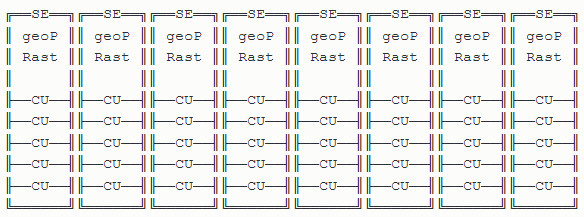
AMD's 7 nm "Navi 10" silicon may finally address two architectural shortcomings of its performance-segment GPUs, memory bandwidth, and render-backends (deficiency thereof). The GPU almost certainly features a 256-bit GDDR6 memory interface, bringing about a 50-75 percent increase in memory bandwidth over "Polaris 30." According to a sketch of the GPU's SIMD schematic put out by KOMACHI Ensaka, Navi's main number crunching machinery is spread across eight shader engines, each with five compute units (CUs).
Five CUs spread across eight shader engines, assuming each CU continues to pack 64 stream processors, works out to 2,560 stream processors on the silicon. This arrangement is in stark contrast to the "Hawaii" silicon from 2013, which crammed 10 CUs per shader engine across four shader engines to achieve the same 2,560 SP count on the Radeon R9 290. The "Fiji" silicon that followed "Hawaii" stuck to the 4-shader engine arrangement. Interestingly, both these chips featured four render-backends per shader engine, working out to 64 ROPs. AMD's decision to go with 8 shader engines raises hopes for the company doubling ROP counts over "Polaris," to 64, by packing two render backends per shader engine. AMD unveils Navi in its May 27 Computex keynote, followed by a possible early-July launch.
Sources:
KOMACHI Ensaka (Twitter), Edificil (Reddit)
Five CUs spread across eight shader engines, assuming each CU continues to pack 64 stream processors, works out to 2,560 stream processors on the silicon. This arrangement is in stark contrast to the "Hawaii" silicon from 2013, which crammed 10 CUs per shader engine across four shader engines to achieve the same 2,560 SP count on the Radeon R9 290. The "Fiji" silicon that followed "Hawaii" stuck to the 4-shader engine arrangement. Interestingly, both these chips featured four render-backends per shader engine, working out to 64 ROPs. AMD's decision to go with 8 shader engines raises hopes for the company doubling ROP counts over "Polaris," to 64, by packing two render backends per shader engine. AMD unveils Navi in its May 27 Computex keynote, followed by a possible early-July launch.
24 Comments on AMD "Navi" Features 8 Streaming Engines, Possible ROP Count Doubling?
Assuming Raja actually did his job before he left for Intel, which was to make GCN more scale-able.
The Geometry limit was the Achilles heel of GCN in terms of gaming performance.
In Pixel Fill-rate the Radeon VII actually beats the 2080, but when you look at Geometry it is far behind.
The ROP count might not be the actual issue.
Monopolies aren't good for anyone, as it normally means higher prices, slower innovation and poor selection.
Nvidia might not be a monopoly, but with their performance lead on the higher end of the market, they might as well be.
Here's also fingers crossed that Intel will bring out something competitive when they launch their GPUs.
I long for the days when there were half a dozen competitive GPU makers, but that was a very long time ago and before they were called GPUs...
Remember the 128ROP BS that pop up around Vega 20? This can easily be another round of BS before launch.
2. AMD is very flexible in the wired amount of ROP, so they could´ve used 128 ROP with Hawaii if they wanted, they´ve seen no need for that by now, even for the Radeon VII, or MI60 they didn´t.
3. Even Nvidia is shy for using 8 Geo-Engines because the wirering will owerwhelm the chip with nearly no efficiency-gain
4. Navi is GCN and more than 4 Shader-Arrays are forbidden in GCN.
The picture on the bottom is changeable to avec (with) blending. The Vegas will be over 100 for the upper 4 numbers, wich is no bad at all.
www.hardware.fr/articles/955-7/performances-theoriques-pixels.html
It´s the newest one Mr Triolet made before his departure to AMD and later to Intels Graphic division.
Radeon VII (1 TB/s) vs. RTX 2080 (448 GB/s)
Vega 64 (484 GB/s) vs. GTX 1080 (320 GB/s)
RTX 580 (256 GB/s) vs. GTX 1060 (192 GB/s)
Just looking at benchmarks and comparing AMD cards to their Nvidia rivals in different resolutions is enough.
AMD generally puts more bandwidth on their cards simply because they can't compete head to head and need more raw resourses to do so.
Amd/comments/braa94/_/eof8jvd
They're stuck, and they have been stuck since Hawaii, its what I've been seeing and saying ever since. Fury X was not competitive and HBM for the gaming segment was a stopgap measure to keep GCN in the game, not something you do if you like a healthy profit margin. Vega simply didn't perform as it should have (or should have been ready for launch when Nvidia launched GP104), and VII is saved by the 7nm node; 'sorta'.
Beyond that, there is nothing to give. At the same time, they haven't got the technology/performance lead that provides the necessary time to complete revamp GCN from the ground up. Ironically, its rather similar to Intel's current CPU roadmap. Perhaps that is part of the rationale for Intel to focus on GPU as well; perhaps they've seen you can't be leading all the time without creating new risk (stagnation).
The other method is the compute shader: it does not throttle tmus, but the tmu cache is still quarter rate per 16x af and it does not work like the pixel shader. One benefit of the pixel shader is, it is fully pipelined: you don't go full netburst-prescott disaster; it is pipelined, every data is memory mapped and you get the usual benefits. The gain of compute shader is that it is the non-native version of this pipeline - whether the developer can benefit from his own custom pipeline is his doing. While the pixel shader is streamlined per memory accesses(reads) for less latency by default, the compute shader has the benefit of write streamlining, since caches are a faster storage medium than memory. It is just a coincidence which fits the attempted end result - using caches instead of vram has the added benefit of cutting out the middleman oem manufacturers at setting the memory timing parameters in their premium gpu lines; caches are a more uniform solution than custom gddr dies.
Been thinking about that name Navi ,I got New Architecture for Vertical Integration, i'm thinking :);) it'll be modular obviously and obviously adaptable.
The star's a coincidence.
it a joke, 780 Ti from zillion years ago have 2800 :x
Honestly, consider for a moment that a 390 has more double-precision compute power than a 2080 Ti which would be hilarious beside the fact that it gets you absolutely nothing in games.