AMD Formally Launches Ryzen Threadripper PRO 9000 and Radeon AI PRO 9000 Series
AMD today formally launched a slew of new hardware for workstations. These include the new Ryzen Threadripper PRO 9000 "Shimada Peak" line of high core-count processors, and the Radeon AI PRO 9000 line of graphics cards that cover a range of use-cases spanning from edge AI acceleration to professional visualization. The Threadripper 9000 series is based on the "Zen 5" microarchitecture, and "Shimada Peak" is a variant of the "Turin" MCM powering 5th Gen EPYC processors, which comes with workstation-relevant I/O. Meanwhile, the Radeon AI Pro 9000 series is based on the same RDNA 4 graphics architecture powering the Radeon RX 9000 series gaming graphics cards.
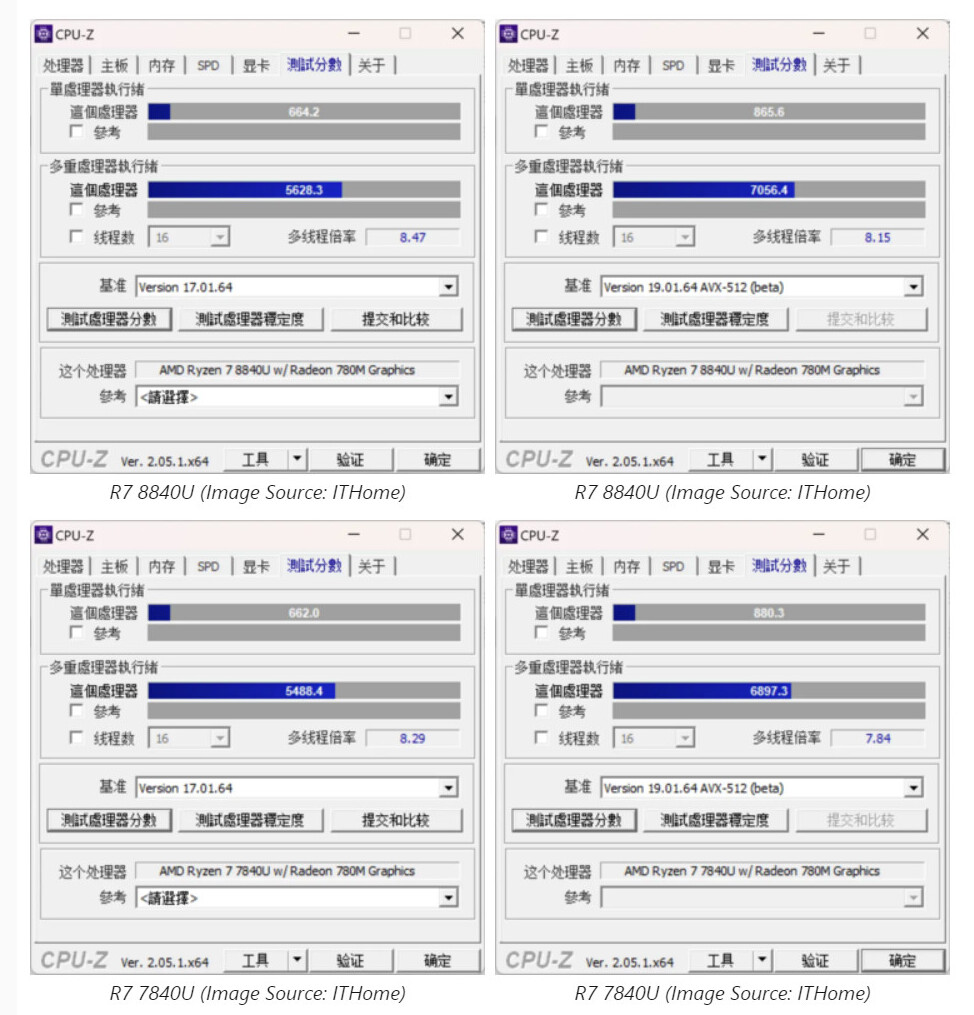
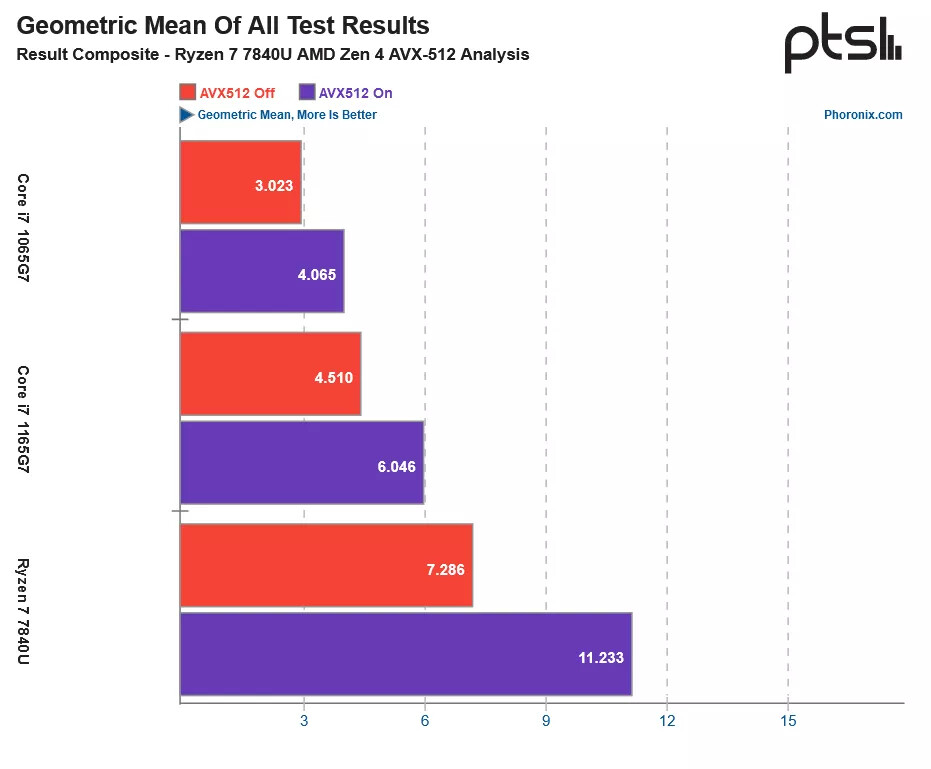
The Ryzen Threadripper 9000 series comes with CPU core counts of up to 96-core/192-thread, with an IPC uplift from the "Zen 5" microarchitecture over the previous Threadripper 7000 series "Storm Peak" processors powered by "Zen 4." More than IPC, workstation users should benefit greatly from the architecture's full 512-bit FPU data-path, offering significant increases in performance of applications that leverage the AVX-512 instruction set. AMD also fine-tuned the IOD (I/O die) to support increased memory speeds of DDR5-6400 (native), AMD EXPO profiles, and CKD. With these changes, and minor increases in clock speeds for certain SKUs, AMD is promising a 16% uplift in performance over the Threadripper 7000 series predecessors in workstation benchmarks, and a significant 25% increase in SPEC Workstation AI and ML benchmarks (comparing identical core-counts and frequency).



The Ryzen Threadripper 9000 series comes with CPU core counts of up to 96-core/192-thread, with an IPC uplift from the "Zen 5" microarchitecture over the previous Threadripper 7000 series "Storm Peak" processors powered by "Zen 4." More than IPC, workstation users should benefit greatly from the architecture's full 512-bit FPU data-path, offering significant increases in performance of applications that leverage the AVX-512 instruction set. AMD also fine-tuned the IOD (I/O die) to support increased memory speeds of DDR5-6400 (native), AMD EXPO profiles, and CKD. With these changes, and minor increases in clock speeds for certain SKUs, AMD is promising a 16% uplift in performance over the Threadripper 7000 series predecessors in workstation benchmarks, and a significant 25% increase in SPEC Workstation AI and ML benchmarks (comparing identical core-counts and frequency).